



Table of Links
Abstract and 1. Introduction
-
Related Work
-
Proposed Dataset
-
SymTax Model
4.1 Prefetcher
4.2 Enricher
4.3 Reranker
-
Experiments and Results
-
Analysis
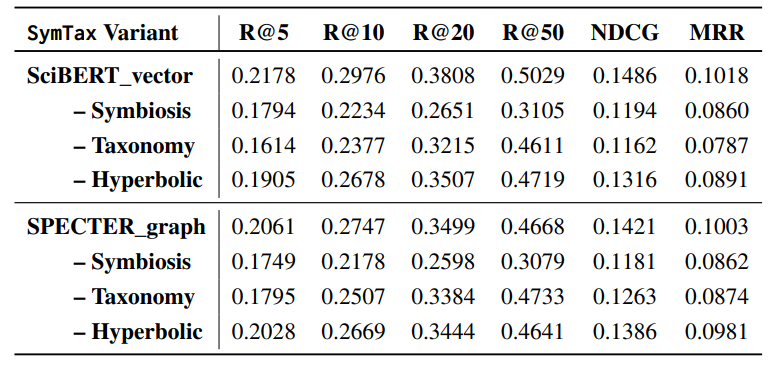
6.1 Ablation Study
6.2 Quantitative Analysis and 6.3 Qualitative Analysis
-
Conclusion
-
Limitations
-
Ethics Statement and References
Appendix
5 Experiments and Results
This section illustrates the various baselines, evaluation metrics and datasets used to benchmark our proposed method followed by the performance comparison.
Baselines. We consider evaluating various available systems for comparison. BM25 (Robertson et al., 2009): It is a prominent ranking algorithm, and we consider its several available implementations and choose Elastic Search implementation[9] as it gives the best performance with the highest speed. SciNCL (Ostendorff et al., 2022): We use its official implementation available on GitHub[10]. HAtten (Gu et al., 2022): We use its official implementation available on GitHub[11]. NCN (Ebesu and Fang, 2017) could have been a potential baseline; however, as reported by Medic and Šnajder (2020), the results mentioned could not be replicated. DualLCR (Medic and Šnajder, 2020): It is essentially a ranking method that requires a small and already existing list of candidates containing the ground truth, which turns it into an artificial setup that, in reality, does not exist. This unfair setup is also reported by Gu et al. (2022), which is state-of-the-art in our task. Thus for a fair comparison, we could not consider it in comparing our final results.
Evaluation Metrics. To stay consistent with the literature that uses Recall@10 and Mean Reciprocal Rank (MRR) as the evaluation metrics, we additionally use Normalised Discounted Cumulative Gain (NDCG@10) and Recall@K for different values of K to obtain more insights from the recommendation performance. Recall@K measures the percentage of cited papers appearing in top-K recommendations. MRR measures the reciprocal rank of the cited paper among the recommended candidates. NDCG takes into account the relative order of recommendations in the ranked list. The above metrics are averaged over all test queries, and higher values indicate better performance.
Performance Comparison. As evident from Table 2, our evaluation shows the superior performance of SymTax on all metrics across all the datasets. We consider two different variants of SymTax in our main results comparison (i) SpecG: with SPECTER (Cohan et al., 2020) as LM and graph-based taxonomy fusion, and (ii) SciV: with SciBERT (Beltagy et al., 2019) as LM and vectorbased taxonomy fusion. SPECTER and SciBERT are two state-of-the-art LMs trained on scientific text. SciV performs as the best model on ACL-200, FullTextPeerRead, RefSeer and ArSyTa on all metrics. SpecG performs best on arXiv(HAtten) on all metrics and results in a marginally less R@20 score than SciV. We observe the highest scores on FullTextPeerRead followed by ACL-200. It is due to the fact that these datasets lack diversity to a large extent. e.g. FullTextPeerRead is extracted from papers belonging to Artificial Intelligence field, and ACL-200 contains papers published at ACL venues. In contrast, we observe the lowest scores on ArSyTa followed by arXiv(HAtten). The common reason driving these performance trends is that both of these arXiv-based datasets contain articles from different publication venues with various formats, styles and domain areas, making the learning difficult and recommendation challenging. Our reasoning is further supported by the fact that ArSyTa is the latest dataset, and thus

contains the maximum amount of diverse samples and is shown to be the toughest dataset for recommending citations. To summarise, we obtain performance gains in Recall@5 of 26.66%, 23.65%, 39.25%, 19.74%, 22.56% with respect to SOTA on ACL-200, FullTextPeerRead, RefSeer, arXiv(HAtten) and ArSyTa respectively. The results show that NDCG is a tough metric compared to the commonly used Recall, as it accounts for the relative order of recommendations. Since the taxonomy class attribute is only available for our proposed dataset, we intentionally designed SymTax to be highly modular for better generalisation, as evident in Table 2.
:::info
Authors:
(1) Karan Goyal, IIIT Delhi, India (karang@iiitd.ac.in);
(2) Mayank Goel, NSUT Delhi, India (mayank.co19@nsut.ac.in);
(3) Vikram Goyal, IIIT Delhi, India (vikram@iiitd.ac.in);
(4) Mukesh Mohania, IIIT Delhi, India (mukesh@iiitd.ac.in).
:::
:::info
This paper is available on arxiv under CC by-SA 4.0 Deed (Attribution-Sharealike 4.0 International) license.
:::
[9] https://github.com/kwang2049/easy-elasticsearch
[10] https://github.com/malteos/scincl
[11] https://tinyurl.com/yckhe7d6



{kind=link}