


Table of Links
Abstract and 1. Introduction
-
Related Work
2.1 Text to Vocal Generation
2.2 Text to Motion Generation
2.3 Audio to Motion Generation
-
RapVerse Dataset
3.1 Rap-Vocal Subset
3.2 Rap-Motion Subset
-
Method
4.1 Problem Formulation
4.2 Motion VQ-VAE Tokenizer
4.3 Vocal2unit Audio Tokenizer
4.4 General Auto-regressive Modeling
-
Experiments
5.1 Experimental Setup
5.2 Main Results Analysis and 5.3 Ablation Study
-
Conclusion and References
A. Appendix
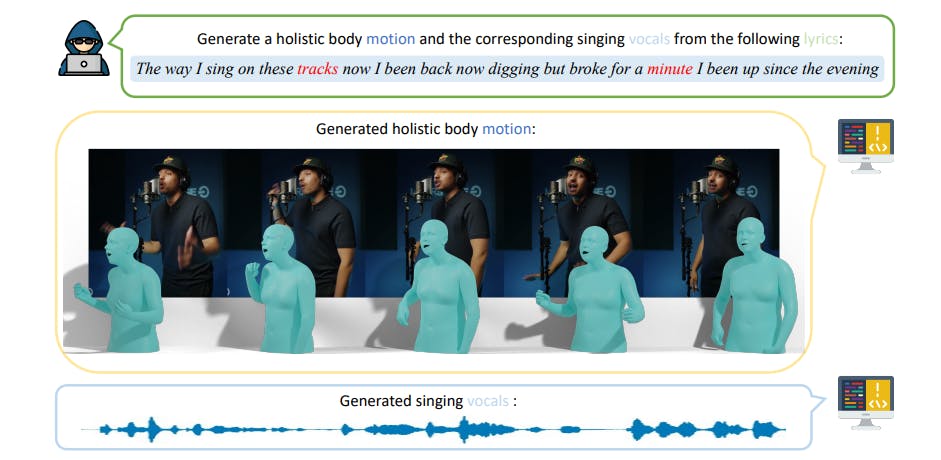
In this section, we introduce RapVerse, a large rap music motion dataset containing synchronized singing vocals, textual lyrics and whole-body human motions. A comparison of our dataset with existing datasets is shown at Table. 1. The RapVerse dataset is divided into two subsets to cater to a broad range of research needs: a Rap-Vocal subset and a Rap-Motion subset. The overall collection pipeline of RapVerse is shown at Fig. 2.
3.1 Rap-Vocal Subset
The Rap-Vocal subset contains 108.44 hours of high-quality English singing voice in the rap genre with paired lyrics. We will introduce each step in detail.
Data Crawling. In a bid to obtain a large number of rap songs and corresponding lyrics from the Internet, we utilize Spotdl and Spotipy to collect songs, lyrics, and metadata of different rap singers. To ensure the quality of the dataset, we perform cleaning on the crawled songs by removing songs with misaligned lyrics and filtering out songs that are too long or too short.
Vocal and Background Music Separation. Since the crawled songs are mixed with rapping vocals and background music, and we aim to synthesize singing vocals from separated clean data, we utilize Spleeter [18], the state-of-the-art open-source vocal-music source separation tool to separate and extract rap vocal voices and accompanying background music from the collected songs. Following [53], we normalize the loudness of the vocal voices to a fixed loudness level.
Vocal Data Processing. The raw crawled lyrics from the Internet are in inconsistent formats, we conduct data cleaning on the lyrics by removing meta information (singer, composer, song name, bridging words, and special symbols). To ensure that the lyrics are aligned with the singing vocals, we collect lyrics only with the correct timestamps of each sentence, and we separate each song into around 10-second to 20-second segments for model training.
3.2 Rap-Motion Subset
The Rap-Motion subset contains 26.8 hours of rap performance videos with 3D holistic body mesh annotations in SMPL-X parameters [42], synchronous singing vocals, and corresponding lyrics. We introduce the collection pipeline of this subset as follows.
Data Crawling. We crawled over 1000 studio performance videos from YouTube under the Common Creative License. We filter out low-quality videos manually to ensure the videos meet the following criteria: stable camera work, performers centered in the frame, clear visibility of the performer’s entire body to capture detailed motion data, and high-quality audio for accurate vocal analysis.
Audio Data Processing. Similar to the Rap-Vocal subset, we leverage Spleeter [19] to isolate singing vocals from accompanying music. Given that YouTube videos typically lack paired lyrics, we employ an ASR model, Whisper [47], to accurately transcribe vocals into corresponding text.
Video Data Processing. To ensure the collection of high-quality video clips for motion annotation, we implemented a semi-automatic process to filter out undesirable content, such as advertisements, transition frames, changes in shots, and flashing lights. Initially, we applied YOLO [50] for human detection to discard frames where no humans were detected. Subsequently, we utilized RAFT [60] to assess the motion magnitude, employing a threshold to eliminate frames affected by camera instability. We then perform meticulous manual curation on the extracted clips, retaining only those of the highest quality. Finally, we follow the pipeline of the optimized-based method Motion-X [30] to extract 3D whole-body meshes from monocular videos. Specifically, we adopt the SMPL-X [42] for motion representations, given a T-frame video clip, the corresponding pose states M are represented as:




Authors:
(1) Jiaben Chen, University of Massachusetts Amherst;
(2) Xin Yan, Wuhan University;
(3) Yihang Chen, Wuhan University;
(4) Siyuan Cen, University of Massachusetts Amherst;
(5) Qinwei Ma, Tsinghua University;
(6) Haoyu Zhen, Shanghai Jiao Tong University;
(7) Kaizhi Qian, MIT-IBM Watson AI Lab;
(8) Lie Lu, Dolby Laboratories;
(9) Chuang Gan, University of Massachusetts Amherst.



{kind=link}