



Table of Links
Abstract and 1. Introduction
-
Related Work
-
Proposed Dataset
-
SymTax Model
4.1 Prefetcher
4.2 Enricher
4.3 Reranker
-
Experiments and Results
-
Analysis
6.1 Ablation Study
6.2 Quantitative Analysis and 6.3 Qualitative Analysis
-
Conclusion
-
Limitations
-
Ethics Statement and References
Appendix
6 Analysis
We conduct extensive analysis to assess further the modularity of SymTax, the importance of different modules, combinatorial choice of LM and taxonomy fusion, and the usage of hyperbolic space over Euclidean space. Furthermore, we analysed the effect of using section heading as an additional signal (shown in Appendix A).
6.1 Ablation Study
We perform an ablation study to highlight the importance of Symbiosis, taxonomy fusion and hyperbolic space. We consider two variants of SymTax, namely SciBERTvector and SPECTERgraph. For each of these two variants, we further conduct three experiments by (i) removing the Enricher module that works on the principle of Symbiosis, (ii) not considering the taxonomy attribute associated with the citation context and (iii) using Euclidean space to calculate the separation score.
As evident from Table 3, Symbiosis exclusion results in a drop of 21.40% and 24.45% in Recall@5 and NDCG respectively for SciBERTvector whereas for SPECTERgraph, it leads to a drop of 17.84% and 20.32% in Recall@5 and NDCG respectively. Similarly, taxonomy exclusion results in a drop of 34.94% and 27.88% in Recall@5 and NDCG respectively for SciBERTvector whereas for SPECTERgraph, it leads to a drop of 14.81% and 12.51% in Recall@5 and NDCG respectively. It is clear from Table 3 that the use of Euclidean space instead of hyperbolic space leads to performance drop across all metrics in both variants. Exclusion of Symbiosis impacts higher recall metrics more in comparison to excluding taxonomy fusion and hyperbolic space.
6.2 Quantitative Analysis
We consider two available LMs, i.e. SciBERT and SPECTER, and the two types of taxonomy fusion, i.e. graph-based and vector-based. This results in four variants, as shown in Table 4. As evident from the results, SciBERTvector and SPECTERgraph are the best-performing variants. So, the combinatorial choice of LM and taxonomy fusion plays a vital role in model performance. The above observations can be attributed to SciBERT being a LM trained on plain scientific text. In contrast, SPECTER is a LM trained with Triplet loss using 1-hop neighbours of the positive sample from the citation graph as hard negative samples. So, SPECTER embodies graph information inside itself, whereas SciBERT does not.
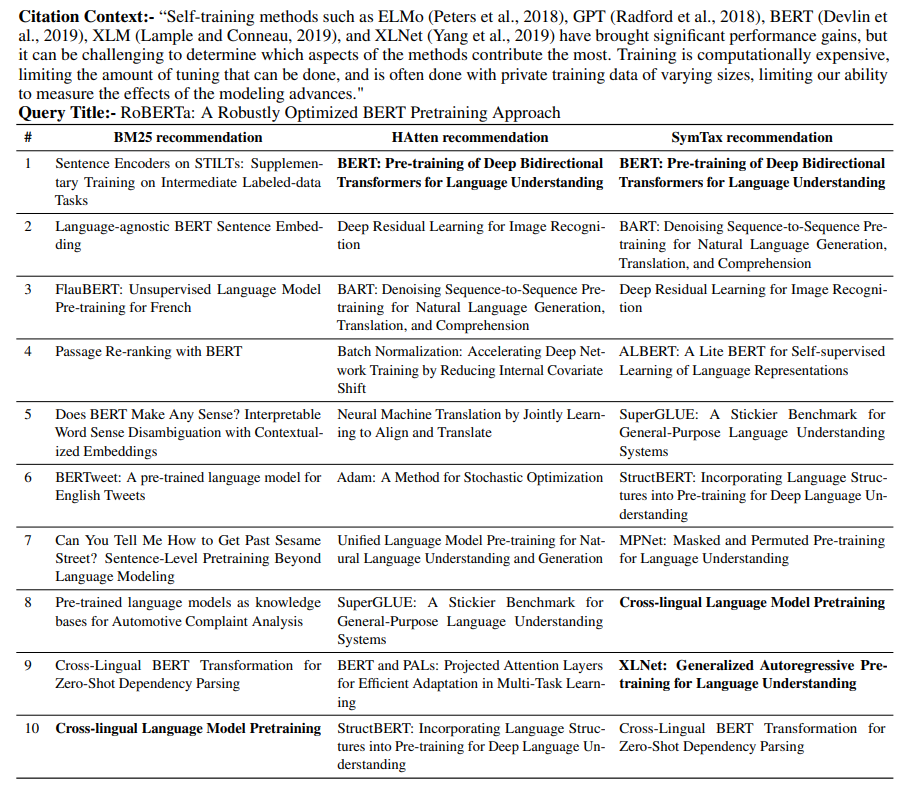
6.3 Qualitative Analysis
We assess the quality of recommendations given by different algorithms by randomly choosing an example. Though random, we choose the example that has multiple citations in a given context so that we can present the qualitative analysis well by investigating the top-10 ranked predictions. As shown in Table 5, we consider an excerpt from Liu et al. (2020) that contains five citations. As we can see that Symtax correctly recommend three citations in the top-10, whereas HAtten only recommend one citation correctly at rank 1 and BM25 only suggest one correct citation at rank 10. The use of title is crucial to performance, as we can see that many recommendations consist of the words “BERT” and “Pretraining”, which are the keywords present in the title. One more observation is that the taxonomy plays a vital role in recommendations. The taxonomy category of the query is ‘Computation and Language‘, and most of the recommended articles are from the same category. SymTax gives only one recommendation (Deep Residual Learning for Image Recognition) from a different category, i.e.“Computer Vision”, whereas HAtten recommends three citations from different categories, i.e. (Deep Residual Learning for Image Recognition) from “Computer Vision” and (Batch Normalization, and Adam) from “Machine Learning”.

:::info
Authors:
(1) Karan Goyal, IIIT Delhi, India (karang@iiitd.ac.in);
(2) Mayank Goel, NSUT Delhi, India (mayank.co19@nsut.ac.in);
(3) Vikram Goyal, IIIT Delhi, India (vikram@iiitd.ac.in);
(4) Mukesh Mohania, IIIT Delhi, India (mukesh@iiitd.ac.in).
:::
:::info
This paper is available on arxiv under CC by-SA 4.0 Deed (Attribution-Sharealike 4.0 International) license.
:::



{kind=link}