



Table of Links
Abstract and 1. Introduction
-
Related Work
-
Proposed Dataset
-
SymTax Model
4.1 Prefetcher
4.2 Enricher
4.3 Reranker
-
Experiments and Results
-
Analysis
6.1 Ablation Study
6.2 Quantitative Analysis and 6.3 Qualitative Analysis
-
Conclusion
-
Limitations
-
Ethics Statement and References
Appendix
4 SymTax Model
We discuss the detailed architecture of our proposed model – SymTax, as shown in Figure 2. It comprises a fast prefetching module, an enriching module and a slow and precise reranking module. We borrow an existing prefetching module from Gu et al. (2022) whereas an enriching module and a reranking module are our novel contributions in the overall recommendation technique. The subsequent subsections elaborate on the architectures of these three modules.
4.1 Prefetcher
The task of the prefetching module is to provide an initial set of high-ranking candidates by scoring all the papers in the database with respect to the query context. It uses cosine similarity between query embedding and document embedding to estimate the relevance between query context and the candidate document. Prefetcher comprises two submodules, namely, Paragraph Encoder and Document Encoder. Paragraph Encoder computes the embedding of a given paragraph, i.e. title, abstract or citation context, using a transformer layer followed by multi-head pooling. Document Encoder takes paragraph encodings as input along with paragraph types and passes them through a multi-head pooled transformer layer to obtain the final document embedding. We adopt the prefetching module from Gu et al. (2022) and use it as a plugin in our overall recommendation technique. For brevity, we refer readers to follow the source to understand the detailed working of the prefetcher.
4.2 Enricher
where {} represents a set operator. We then feed this enriched list as input to the reranker. The design notion of Enricher is inspired by Symbiosis, aka Symbiotic Relationship, a concept in Biology.
Symbiosis. The idea of including cited papers of identified candidates has been pursued in the literature (Cohan et al., 2020) but from the perspective of hard negatives. To the best of our knowledge, the concept of Enrichment has never been discussed earlier for citation recommendation to model the human citation behaviour. We identify two different types of citation behaviours that prevail in the citation ecosystem and draw a corresponding analogy with mutualism and parasitism that falls under the concept of Symbiosis. Symbiosis is a long-term relationship or interaction between two dissimilar organisms in a habitat. In our work, the habitat is
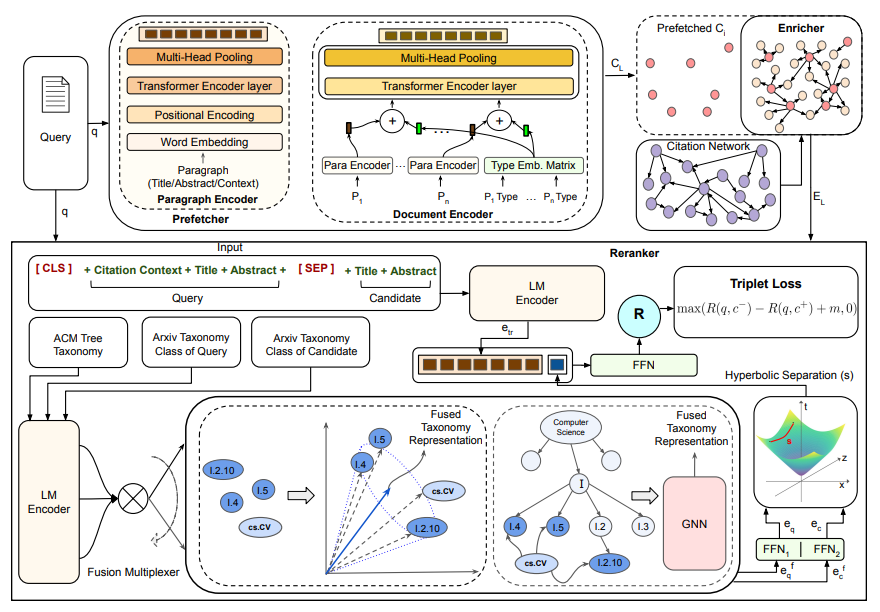

the citation ecosystem, and the two dissimilar organisms are the candidate article and its neighbourhood. We try to explain the citation phenomena through Symbiosis wherein the candidate and its neighbourhood either play the role of mutualism or parasitism. In mutualism, the query paper recommends either only the candidate paper under consideration or both the considered candidate paper and from its 1-hop outdegree neighbour network. On the other hand, in parasitism, the neighbour organism feeds upon the candidate to get itself cited, i.e., the query paper, rather than citing the candidate article, in turn, recommends from its outgoing edge neighbours. This whole idea, in practice, is analogous to human citation behaviour. When writing a research article, researchers often gather a few highly relevant prior art and cite highly from their references. We can interpret this tendency as a slight human bias or highly as utilising the research crowd’s wisdom. Owing to this, Enricher is only required at the inference stage. Nevertheless, it is a significantly important signal, as evident from the results in Table 2 and Table 3.
4.3 Reranker


Taxonomy Fusion. The inclusion of taxonomy fusion is an important and careful design choice. Intuitively, a flat-level taxonomy (arXiv concepts) does not have a rich semantic structure in comparison to a hierarchically structured taxonomy like ACM. In a hierarchical taxonomy, we have a semantic relationship in terms of generalisation, specialisation and containment. Mapping the flat concepts into hierarchical taxonomy infuses a structure into the flat taxonomy. It also enriches the hierarchical taxonomy as we get equivalent concepts from the flat taxonomy. Each article in our proposed dataset ArSyTa consists of a feature category that represents the arXiv taxonomy[7] class it belongs to. Since ArSyTa contains papers from the CS domain, so we have a flat arXiv taxonomy. e.g. cs.LG and cs.CV represents Machine Learning and Computer Vision classes, respectively. We now propose the fusion of flat-level arXiv taxonomy with ACM tree taxonomy[8] to obtain rich feature representations for the category classes. We mainly utilise the subject class mapping information mentioned in the arXiv taxonomy and domain knowledge to create a class taxonomy mapping from arXiv to ACM. e.g. cs.CV is mapped to ACM classes I.2.10, I.4 and I.5 (as shown in Fig. 2). Also, we release the mapping config file in the data release phase. We employ two fusion strategies, namely vector-based and graph-based. In vector-based fusion, the classes are passed through LM and their conical vector is obtained by averaging out class vectors in feature space. In graph-based fusion, we first form a graph by injecting arXiv classes into the ACM tree and creating directed edges between them. We initialise node embeddings using LM and run Graph Neural Network (GNN) algorithm to learn fused representations. We consider GAT(Velickovic et al., 2018) and APPNP(Gasteiger et al., 2019) as GNN algorithms and observe their performance as the same. The final representations of cs.{} nodes represent the fused representations learnt. Empirically, we can clearly observe that the fusion of concepts helps to attain significant performance gains (as shown in Table 3).




:::info
Authors:
(1) Karan Goyal, IIIT Delhi, India (karang@iiitd.ac.in);
(2) Mayank Goel, NSUT Delhi, India (mayank.co19@nsut.ac.in);
(3) Vikram Goyal, IIIT Delhi, India (vikram@iiitd.ac.in);
(4) Mukesh Mohania, IIIT Delhi, India (mukesh@iiitd.ac.in).
:::
:::info
This paper is available on arxiv under CC by-SA 4.0 Deed (Attribution-Sharealike 4.0 International) license.
:::
[7] https://arxiv.org/category_taxonomy
[8] https://tinyurl.com/22t2b43v


{kind=link}