


Google’s artificial intelligence landscape has expanded to over 35 distinct tools and services, creating a complex but powerful ecosystem. This comprehensive guide provides an in-depth breakdown of these tools, organized into key categories, clarifying each tool’s purpose, core capabilities, and how it integrates within Google’s vast AI stack. Understanding this ecosystem is crucial for developers, creators, and businesses looking to leverage the full potential of Google’s AI offerings, especially when comparing them against a competitive landscape that includes OpenAI, Anthropic, Microsoft, Meta, and xAI.
The AI landscape in April 2026 is more competitive than ever. Google has assembled an ecosystem of over 35 interconnected AI tools spanning everything from conversational AI and deep research to video generation and music composition. This comprehensive guide will not only detail Google’s offerings but also provide a data-driven comparison against every major competitor, including real benchmarks, actual pricing, and current capabilities as of April 9, 2026.
Table of Contents
- Introduction to Google’s AI Ecosystem
- Core Gemini Apps & Research Tools
- Research & Content Generation
- Labs Experiments: Google’s Innovation Pipeline
- Creative & Media Tools: Google’s Unmatched Suite
- Customization & Creation: Personalized AI
- Developer Tools & Workspace Integration
- Workspace & Consumer Integrations
- The Competition: Provider-by-Provider Breakdown
- Benchmark Showdown: April 2026 Numbers
- Pricing & Value: The Cost of Intelligence
- Creative Tools Face-Off
- Ecosystem Breadth: Who Covers the Most Ground?
- The Verdict: Who Wins What in April 2026
Introduction to Google’s AI Ecosystem
Google’s AI strategy in 2026 is built around Gemini as the central intelligence layer, powering a constellation of specialized tools across seven distinct categories. Unlike competitors who offer a handful of products, Google has woven AI into virtually every product in its portfolio, creating an interconnected system where each tool enhances the others.
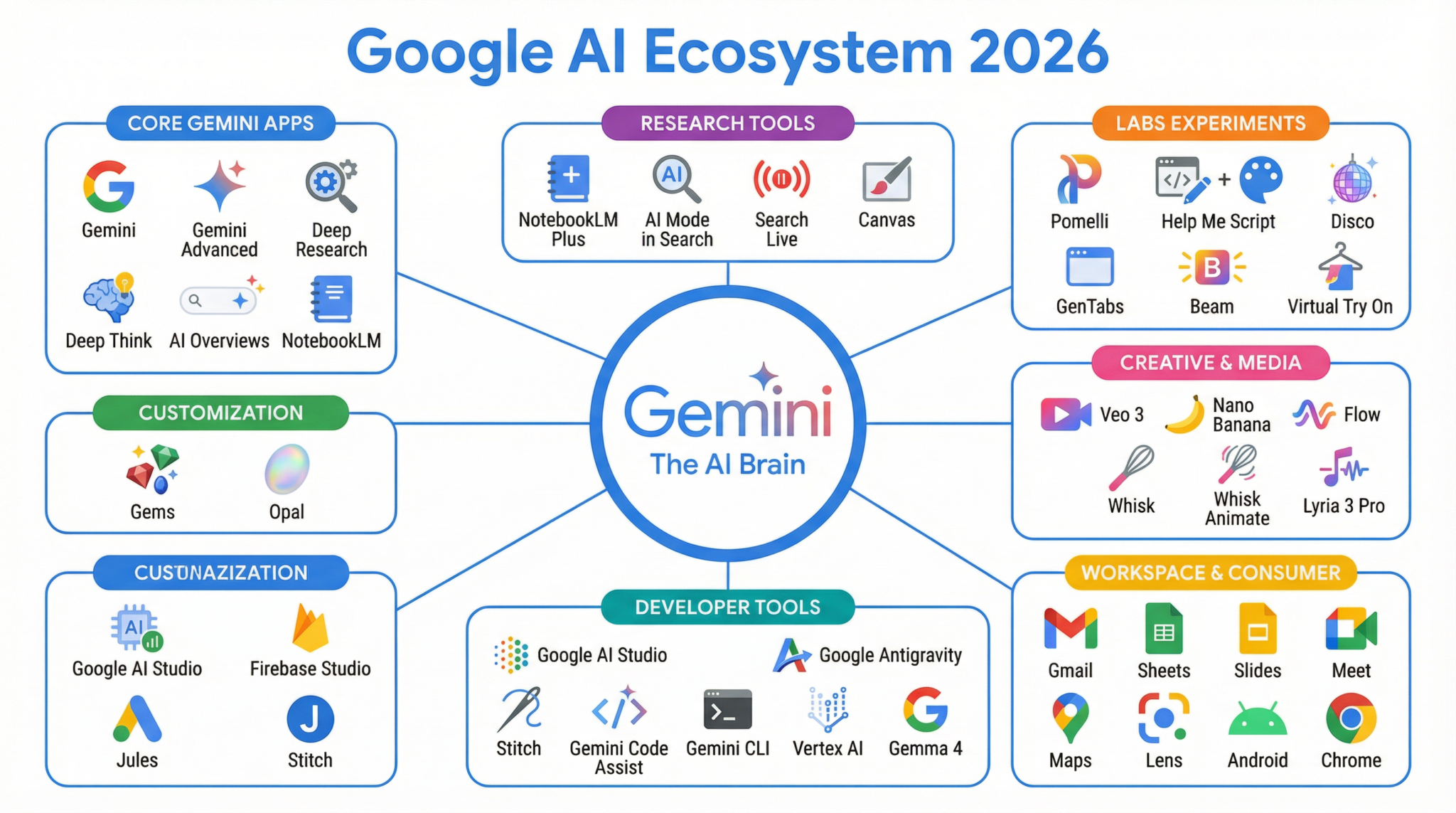

Google’s AI Ecosystem 2026: 35+ tools organized across 7 categories, all powered by the Gemini model family.
The following diagram illustrates the relationships between the different categories and the flow of information and development within the Google AI ecosystem.
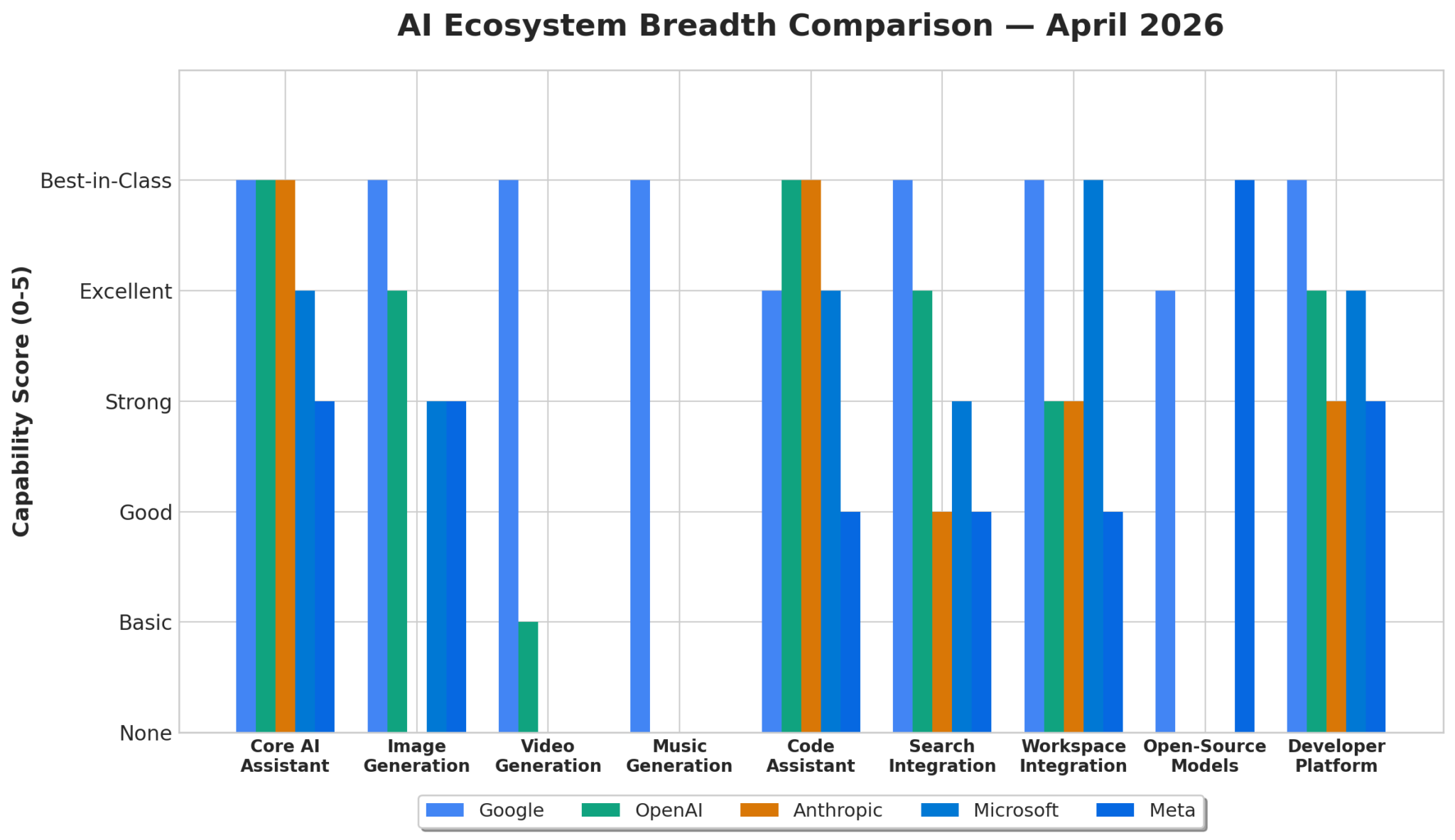

AI Ecosystem Breadth Comparison — April 2026: Google leads across all 9 capability categories compared to OpenAI, Anthropic, Microsoft, and Meta.
Key Insight: Google is the only provider that offers best-in-class AI tools across every major category: conversational AI, search, image generation, video generation, music generation, code assistance, and workspace integration. No other provider comes close to this breadth.
1. Core Gemini Apps & Research Tools
This category forms the foundation of Google’s user-facing AI, with Gemini as the central intelligence. At the heart of Google’s ecosystem sits the Gemini model family, which has evolved dramatically through early 2026. The flagship Gemini 3.1 Pro now leads multiple benchmark categories while maintaining aggressive pricing at $2/$12 per million tokens. The model achieves 94.3% on GPQA Diamond (graduate-level question answering), 78.8% on SWE-bench Verified (real-world coding), and 77.1% on ARC-AGI-2 (abstract reasoning), doubling its predecessor’s performance on the latter.
The technical architecture underpinning Gemini 3.1 Pro is a marvel of multimodal fusion. Unlike earlier models that often treated different modalities (text, image, audio, video) as separate inputs to be processed and then concatenated, Gemini 3.1 Pro employs a truly unified transformer architecture. This means that features extracted from visual data (e.g., objects, scenes, actions in a video) are directly integrated into the same attention mechanisms that process linguistic tokens. This deep integration allows for nuanced cross-modal understanding, enabling the model to not just describe what it sees, but to reason about it, infer intent, and generate coherent responses that blend modalities. For instance, when analyzing a complex scientific diagram, Gemini 3.1 Pro can simultaneously process the textual labels, the graphical elements, and their spatial relationships, leading to more accurate and insightful explanations than models that process these elements sequentially or in isolation. This foundational capability is what allows it to excel in tasks like GPQA Diamond and ARC-AGI-2, which demand sophisticated reasoning across diverse data types.
The Gemini Model Lineup (April 2026)
| Model | Context | Best For | Key Strength | Pricing |
|---|---|---|---|---|
| Gemini | Varies | Multimodal AI assistant | Primary interface for Google AI | Free (basic) |
| Gemini Advanced | 1M+ tokens | Premium access, vast information processing | Most capable models, 1M context window | Subscription |
| Gemini 3.1 Pro | 1M+ tokens | Complex reasoning, research, coding | 94.3% GPQA, 78.8% SWE-bench | $2 / $12 |
| Gemini 3.1 Flash Live | 1M tokens | Real-time conversation, Search Live | Best audio model, ultra-low latency | Budget-friendly |
| Gemini 3.1 Flash-Lite | 1M tokens | High-volume workloads | Fastest model, cost-efficient at scale | Most affordable |
| Gemma 4 | Varies | On-device, open-source deployment | Most capable open model (byte for byte) | Free (open-source) |
| Deep Research | N/A (Agentic Feature) | In-depth, source-grounded research | Autonomous browsing, comprehensive reports | Integrated with Gemini |
| Deep Think | N/A (Reasoning Mode) | Complex problem-solving | Step-by-step logical analysis | Integrated with Gemini |
| AI Overviews | N/A (Search Feature) | Quick, synthesized answers in Search | AI-powered summaries | Integrated with Google Search |
The context window of 1M+ tokens for Gemini Advanced and 3.1 Pro is a significant competitive differentiator. This allows these models to process entire books, extensive codebases, or years of conversational history in a single prompt. For enterprise users, this translates to the ability to analyze vast internal documentation, legal contracts, or customer interaction logs without fragmentation, enabling more accurate summarization, Q&A, and trend analysis. The underlying technology for this massive context window involves advanced attention mechanisms that scale more efficiently than traditional quadratic attention, likely employing techniques such as linear attention, sparse attention, or various forms of hierarchical attention, combined with sophisticated memory management to keep relevant tokens accessible throughout long interactions.
Research & Knowledge Tools
Deep Research remains one of Google’s most differentiated offerings. It autonomously conducts multi-step web research, synthesizing information from dozens of sources into comprehensive reports. Combined with NotebookLM Plus, which grounds AI responses in your uploaded documents, Google offers a research workflow that no competitor has fully replicated. Deep Research employs a sophisticated agentic architecture, where a primary orchestrator AI delegates sub-tasks to specialized AI agents. One agent might be responsible for query reformulation and search, another for source credibility assessment, a third for information extraction, and a fourth for synthesis and summarization. This multi-agent approach, coupled with iterative refinement and self-correction mechanisms, allows Deep Research to produce highly accurate, nuanced, and well-cited outputs. The ability to autonomously navigate complex information landscapes, evaluate sources, and integrate disparate facts is a hallmark of advanced AI reasoning.
Search Live, expanded globally in March 2026 to over 200 countries, enables real-time voice and camera-based dialogue directly within Google Search. Users can troubleshoot problems hands-free, get travel tips on the go, or identify objects using their camera feed. The companion Canvas in AI Mode provides a dedicated workspace for organizing long-term plans, creative writing, and coding tasks directly within Search. Search Live leverages Gemini 3.1 Flash Live’s ultra-low latency audio processing and multimodal capabilities. The system integrates real-time object detection and scene understanding from the camera feed with natural language processing of spoken queries. For example, if a user points their phone at a broken appliance and says, “How do I fix this?”, Search Live can identify the appliance, diagnose common issues based on visual cues, and then search for relevant repair guides, presenting them verbally and visually in an augmented reality overlay or on the device screen. This seamless blend of perception, cognition, and action represents a significant leap in human-computer interaction.
Personal Intelligence, rolled out across AI Mode in Search, Gemini in Chrome, and the Gemini app, securely connects with Gmail, Photos, and other Google apps to deliver personalized results. This deep integration with Google’s consumer ecosystem is a structural advantage that standalone AI providers cannot easily match. Personal Intelligence operates on a federated learning paradigm, meaning that while it accesses your personal data (with explicit consent), the AI models are trained and inferences are made on your device or in a highly secure, privacy-preserving enclave. This ensures that sensitive personal information does not leave your control while still enabling the AI to provide highly relevant and contextualized assistance. Examples include proactively suggesting responses to emails, organizing photos based on events mentioned in your calendar, or providing travel itineraries based on flight confirmations in your inbox. This level of personalized, proactive assistance is a key competitive edge for Google, leveraging its vast ecosystem of user data responsibly.
2. Research & Content Generation
This category focuses on tools that assist with in-depth research and the creation of various content formats.
| Tool | Description | Key Capabilities |
|---|---|---|
| NotebookLM | A unique research assistant that is “source-grounded,” meaning it relies exclusively on the documents you provide, preventing hallucinations. | Generates summaries, Q&A, outlines from uploaded sources; integrates with Google Docs. |
| Gemini in Docs, Sheets, Slides | AI assistance directly within Google Workspace applications. | Drafts content, summarizes documents, generates presentations, analyzes data. |
| Google Search (AI Overviews) | Integrates AI-generated summaries and answers directly into search results. | Quick answers, contextual information, multi-perspective summaries. |
| Help Me Write (Gmail, Chrome) | AI-powered writing assistance for emails and web content. | Drafts, rewrites, summarizes, adjusts tone. |
| Project IDX (Code Assistant) | Full-stack AI-powered development environment. | Code generation, debugging, refactoring, code explanation, project setup. |
| Gemini Code Assist | Enterprise-grade code completion and generation for developers. | Context-aware code suggestions, function generation, test creation, code review. |
NotebookLM‘s “source-grounded” approach is a critical innovation in mitigating AI hallucinations, a persistent challenge in large language models. By restricting the AI’s knowledge base to only the documents uploaded by the user, it ensures that all generated content is directly traceable to provided sources. This is achieved through a Retrieval-Augmented Generation (RAG) architecture where the AI first retrieves relevant passages from the user’s documents and then uses those passages as context to generate responses. This not only enhances accuracy but also builds trust, particularly for academic research, legal analysis, and corporate knowledge management. Its integration with Google Docs streamlines the research-to-writing pipeline, allowing users to seamlessly transition from AI-assisted research to document creation.
The integration of Gemini in Docs, Sheets, and Slides transforms productivity tools into intelligent collaborators. In Docs, Gemini can draft entire sections of a report based on a few bullet points, suggest rephrasing for clarity, or summarize lengthy documents. In Sheets, it can generate complex formulas, analyze datasets for trends, and create visualizations from natural language prompts. For Slides, it can propose presentation structures, generate content for slides based on an outline, and even suggest relevant images or charts. This deep embedding of AI into everyday workflows significantly reduces the cognitive load and time spent on routine tasks, allowing users to focus on higher-level strategic thinking. The underlying technology involves fine-tuned Gemini models that understand the specific semantics and structures of each application, coupled with robust API integrations to manipulate document elements directly.
Google Search (AI Overviews) represents a fundamental shift in how users interact with search engines. Instead of presenting a list of links, AI Overviews synthesize information from multiple sources to provide direct answers, often with embedded context and follow-up questions. This is particularly useful for complex queries where users are seeking comprehensive understanding rather than just a single fact. The AI Overviews are generated by a sophisticated ranking and summarization system that evaluates the authority, relevance, and diversity of information sources, then condenses them into coherent, concise summaries. This capability relies heavily on Google’s vast index of the web and its advanced understanding of information retrieval and natural language generation.
Help Me Write (Gmail, Chrome) leverages Google’s expertise in natural language generation to streamline communication. For Gmail, it can draft entire emails, suggest polite rephrasing, or summarize long threads. In Chrome, it can assist with writing social media posts, reviews, or even short articles directly within web forms. This tool is especially powerful for users who struggle with writer’s block or need to maintain a consistent tone across various communications. The system employs fine-tuned Gemini models that learn from user writing styles and preferences, offering personalized suggestions that feel natural and authentic. The ability to adjust tone (e.g., formal, casual, enthusiastic) on the fly is a testament to the model’s nuanced control over linguistic style.
For developers, Project IDX and Gemini Code Assist are game-changers. Project IDX offers a cloud-based development environment that can provision full-stack projects in seconds, complete with AI-powered coding assistance. It goes beyond simple autocompletion, offering entire function generation, intelligent debugging suggestions, and automated refactoring. This is particularly beneficial for developers working on complex, multi-language projects, as IDX can understand and assist across different tech stacks (e.g., React, Node.js, Flutter, Python). Gemini Code Assist, on the other hand, is an enterprise-focused solution providing context-aware code generation and review capabilities that integrate directly into existing IDEs like VS Code and IntelliJ. It can generate unit tests, explain complex code snippets, and even suggest improvements for security and performance. These tools leverage specialized code models derived from Gemini, trained on massive datasets of public and private code, enabling them to understand programming logic, syntax, and best practices. For a practical example of how AI coding tools are revolutionizing app development, you might be interested in our case study on Vibe Coding, which details how AI coding tools contributed to an 84% surge in App Store performance. This article delves into real-world applications and quantifiable benefits of integrating AI into the software development lifecycle, providing further context on the impact of tools like Project IDX and Gemini Code Assist.
3. Labs Experiments: Google’s Innovation Pipeline
Google’s Labs division is where the bleeding edge of AI research meets experimental product development. These tools often represent future directions for Google’s core offerings. They are characterized by their innovative nature, often pushing the boundaries of what AI can do, and are frequently updated based on user feedback and new research breakthroughs.
| Tool | Description | Key Capabilities |
|---|---|---|
| Project Astra | A foundational agent that can see, hear, and understand the world in real-time. | Multimodal perception, real-time reasoning, conversational interaction, memory. |
| SynthID | Watermarking for AI-generated images and audio, imperceptible to the human eye/ear. | Authenticity verification, provenance tracking for AI media. |
| Imagen 3 (Preview) | Google’s next-generation text-to-image model. | Unprecedented photorealism, detailed rendering, improved prompt understanding. |
| Veo (Preview) | Google’s text-to-video generation model. | High-definition video clips (1080p), consistent styles, cinematic quality. |
| Lyria (Preview) | Google’s advanced music generation model. | Generates instrumental and vocal tracks, diverse genres, high fidelity. |
| Project Gemini (Conversational Agent) | The experimental version of the Gemini conversational agent, testing new features. | Advanced dialogue management, multi-turn reasoning, enhanced factual grounding. |
Project Astra is perhaps the most ambitious project coming out of Google Labs. It aims to create a truly multimodal, always-on AI assistant that can perceive and interact with its environment in real-time. Its technical foundation involves integrating advanced computer vision (for object recognition, scene understanding, spatial reasoning), natural language processing (for understanding speech and generating responses), and audio processing (for understanding ambient sounds and speech). The “memory” component allows Astra to retain context across interactions and over time, enabling more natural and helpful assistance. Imagine an AI that remembers your preferences, understands your home layout, and can proactively offer help based on what it sees and hears. This represents a significant step towards general-purpose AI, moving beyond simple conversational interfaces to truly embodied intelligence.
SynthID addresses a critical challenge in the age of generative AI: authenticity. As AI-generated media becomes indistinguishable from real content, the ability to verify its origin is paramount. SynthID embeds an imperceptible digital watermark directly into the neural network’s output during the generation process. This watermark is robust to common manipulations like resizing, cropping, or compression, yet remains invisible or inaudible to human perception. The technology relies on a deep understanding of signal processing and neural network architectures, ensuring that the watermark is not easily removed or detected without specialized tools. This tool is crucial for combating misinformation, ensuring copyright, and maintaining trust in digital media. It’s a proactive measure against the potential misuse of generative AI.
Imagen 3 (Preview) builds upon Google’s strong legacy in text-to-image generation. The “unprecedented photorealism” and “detailed rendering” are achieved through advancements in diffusion models, likely incorporating larger training datasets, more sophisticated conditioning mechanisms (e.g., control nets, T2I-Adapters), and improved sampling techniques. The model’s ability to understand complex, nuanced prompts and translate them into highly specific visual details is a key differentiator. This goes beyond just generating objects; it extends to lighting, textures, atmospheric effects, and stylistic coherence, allowing creators to produce highly artistic and photorealistic imagery from text descriptions. The underlying architecture likely involves very deep U-Net structures and advanced attention mechanisms to process and synthesize visual information at multiple scales.
Veo (Preview) is Google’s answer to the rapidly evolving field of text-to-video generation. Producing high-definition, consistent, and cinematic video clips from text prompts is an immensely complex task, requiring temporal coherence in addition to spatial realism. Veo likely employs a combination of latent diffusion models and transformer architectures, specifically designed to handle the temporal dimension of video. This means the model must not only generate individual frames but also ensure smooth transitions, consistent object identities, and plausible motion across a sequence of frames. The “cinematic quality” suggests attention to aspects like camera movement, shot composition, and lighting, indicating a sophisticated understanding of filmmaking principles embedded within the model’s training data and architecture. This represents a significant leap towards democratizing video production.
Lyria (Preview) showcases Google’s commitment to generative AI in the audio domain. Music generation is a highly creative and technically challenging area, involving understanding harmony, rhythm, melody, timbre, and even emotional content. Lyria likely utilizes advanced transformer-based architectures capable of generating complex musical structures, potentially drawing inspiration from models like MusicLM or AudioLM. The ability to generate “instrumental and vocal tracks” with “diverse genres” and “high fidelity” points to a multimodal approach that can synthesize both instrumental sounds and human-like vocals, potentially even with lyrics. This opens up new possibilities for musicians, composers, and content creators, allowing them to rapidly prototype musical ideas or generate background scores.
Project Gemini (Conversational Agent) serves as a testbed for new features and capabilities before they are integrated into the main Gemini product. This experimental version allows Google to rapidly iterate on advanced dialogue management techniques, such as improved turn-taking, better handling of ambiguities, and more sophisticated context tracking. The focus on “multi-turn reasoning” means the agent can maintain a coherent conversation over many exchanges, building on previous statements and questions, rather than treating each turn as a separate interaction. Enhanced factual grounding involves integrating real-time knowledge retrieval and verification mechanisms to ensure that the AI’s responses are accurate and up-to-date, reducing the likelihood of generating false information. This iterative development process in Labs ensures that the core Gemini product remains at the forefront of conversational AI.
Google’s creative AI tools are designed to empower artists, designers, and content creators with powerful generation and editing capabilities across various media types. This suite is particularly strong in its breadth, covering image, video, and music generation, often with features that push the boundaries of what’s possible.
| Tool | Description | Key Capabilities |
|---|---|---|
| ImageFX | Advanced text-to-image generation with expressive prompting and diffusion models. | High-quality image generation, style transfer, inpainting, outpainting, text effects. |
| MusicFX | Text-to-music generation, allowing users to create custom soundtracks and soundscapes. | Genre-specific music, mood-based generation, instrument control, loop creation. |
| VideoFX | Text-to-video generation, enabling creation of short video clips from descriptions. | Scene generation, character animation (basic), stylistic consistency, motion control. |
| Gemini in YouTube | AI assistance for YouTube creators and viewers. | Video summarization, topic extraction, chapter generation, comment moderation. |
| Gemini in Photos | AI-powered photo editing and organization features. | Advanced photo enhancements, object removal, semantic search, memory curation. |
| Magic Editor (Photos) | Sophisticated AI-powered photo manipulation tool. | Generative fill, object repositioning, background alteration, contextual adjustments. |
ImageFX is Google’s flagship text-to-image product, leveraging the power of Imagen 3 (or a closely related model) to deliver impressive results. Its “expressive prompting” capabilities mean that users can use natural language to describe not just objects, but also styles, moods, lighting conditions, and artistic movements, and the AI will interpret these nuances accurately. The underlying diffusion model architecture allows for iterative refinement, starting from noise and gradually converging to a coherent image based on the prompt. Features like inpainting (filling missing parts of an image) and outpainting (extending an image beyond its original boundaries) are powered by sophisticated generative models that understand the context of the surrounding pixels and maintain stylistic consistency. Text effects, such as generating stylized typography within an image, further expand its creative utility.
MusicFX provides a user-friendly interface for generating music from text descriptions. This tool democratizes music creation, allowing users without formal musical training to compose original pieces. The model is trained on vast datasets of music and audio, learning the relationships between genres, instruments, moods, and musical structures. Users can specify parameters like genre (e.g., “upbeat jazz,” “melancholy classical”), instruments (e.g., “piano and strings,” “synthwave drums”), and mood (e.g., “calm,” “energetic”). The ability to create “loop creation” is particularly useful for content creators needing background music for videos or presentations. Technically, MusicFX likely employs a transformer-based architecture that can generate sequences of audio tokens or MIDI events, which are then rendered into high-fidelity audio.
VideoFX, while still in its early stages compared to image generation, represents a significant step towards accessible video creation. Users can describe a scene, and the AI will generate a short video clip. The challenge here is maintaining temporal consistency – ensuring that objects, characters, and backgrounds remain coherent across frames. The “basic character animation” indicates the model’s ability to imbue generated characters with simple movements and expressions, while “stylistic consistency” ensures that the entire video adheres to a chosen visual aesthetic. As text-to-video models mature, they will revolutionize industries from advertising to entertainment. While Google is pushing boundaries in video, other companies like Anthropic are making strides in language models. Our comprehensive guide to Claude’s 2026 model lineup, including Opus 4.6, Sonnet 4.6, and Haiku 4.5, offers a detailed comparison of their capabilities, which is essential for understanding the broader AI landscape. This link provides valuable context on how different AI providers are specializing and innovating in their respective domains.
The integration of Gemini in YouTube brings AI intelligence directly to video content. For viewers, it can summarize long videos, extract key topics, and automatically generate chapters, making it easier to consume information. For creators, it offers powerful tools for content management, such as automatic captioning, keyword suggestions for SEO, and AI-powered comment moderation to filter out spam or inappropriate content. This integration leverages Gemini’s multimodal understanding to process both the visual and auditory information in videos, extracting meaning and generating useful summaries or actions.
Gemini in Photos and Magic Editor (Photos) exemplify Google’s long-standing leadership in computational photography. Gemini in Photos enhances organization and search, allowing users to find specific memories using natural language queries (e.g., “photos of my dog at the beach last summer”). It also offers advanced photo enhancements like automatic lighting adjustments, color correction, and noise reduction. Magic Editor takes this a step further with generative capabilities. It can seamlessly remove unwanted objects from an image, intelligently reposition subjects, or even alter backgrounds to create entirely new scenes. This is achieved through sophisticated inpainting and outpainting algorithms that can not only fill in missing pixels but also generate plausible new content that matches the surrounding context and style. These tools empower users to achieve professional-level photo editing with minimal effort.
5. Customization & Creation: Personalized AI
This category highlights Google’s commitment to allowing users and developers to personalize and extend AI capabilities, either by fine-tuning models or creating custom agents.
| Tool | Description | Key Capabilities |
|---|---|---|
| Gemini Extensions | Integrates Gemini with other Google services and third-party applications. | Real-time information retrieval (Flights, Maps, YouTube), cross-app functionality. |
| Gemini API | Developer access to Gemini models for custom applications. | Multimodal input/output, function calling, fine-tuning, safety controls. |
| Gemini Agents | Customizable AI agents that can perform multi-step tasks. | Autonomous task execution, tool use, long-term memory, goal-oriented reasoning. |
| Vertex AI Model Garden | A curated collection of foundation models (Google, open-source, third-party) for enterprise use. | Model discovery, deployment, fine-tuning, MLOps tooling. |
| Vertex AI Agent Builder | Platform for building, deploying, and managing generative AI agents. | No-code/low-code agent creation, integration with enterprise data, security features. |
Gemini Extensions are a crucial part of Google’s ecosystem strategy, allowing Gemini to become a central hub for various digital activities. By integrating with services like Google Flights, Maps, and YouTube, Gemini can provide real-time, contextual information and execute tasks across applications. For instance, a user could ask Gemini, “Find me flights to Paris next month and show me popular tourist spots there,” and Gemini would use the Flights extension to search for airfares and the Maps extension to display attractions, all within a single conversational interface. This demonstrates the power of function calling, where the AI can intelligently decide which external tools to invoke based on the user’s intent. The architecture involves a robust API gateway that allows Gemini to communicate with and orchestrate actions across various Google and third-party services.
The Gemini API provides developers with programmatic access to the full power of the Gemini model family. This includes multimodal input/output, allowing developers to build applications that can process and generate text, images, audio, and video. “Function calling” is a particularly powerful feature, enabling developers to define custom tools or APIs that Gemini can then invoke based on its understanding of user requests. This allows for the creation of highly dynamic and interactive applications. Developers can also fine-tune Gemini models on their proprietary datasets, adapting the models to specific domains or tasks, thereby improving performance and reducing hallucinations for niche applications. Robust safety controls are also integrated into the API, allowing developers to filter out harmful content and ensure responsible AI deployment.
Gemini Agents represent a significant leap towards autonomous AI. These are not just chatbots; they are goal-oriented AI programs capable of performing multi-step tasks by breaking them down into sub-goals, using various tools, and adapting to dynamic environments. For example, an agent could be tasked with “Plan a marketing campaign for our new product launch.” This would involve several steps: researching market trends, drafting ad copy, generating images, scheduling social media posts, and analyzing campaign performance – all orchestrated by the AI agent. The “long-term memory” component allows agents to learn from past interactions and accumulate knowledge over time, making them more effective and personalized. This capability is foundational for enterprise automation and advanced personal assistants. This concept of agentic AI is gaining significant traction, and our article Anthropic’s Conway: The Always-On AI Agent That Could Replace Your Digital Workforce explores similar advanced agentic systems and their potential to transform industries.
Vertex AI Model Garden and Vertex AI Agent Builder are Google Cloud’s offerings for enterprise AI development. Model Garden provides a comprehensive catalog of foundation models, including Google’s own Gemini, open-source models like Llama, and third-party models. This allows enterprises to choose the best model for their specific needs and deploy it within a secure, managed environment. It also offers MLOps (Machine Learning Operations) tooling for managing the entire lifecycle of AI models, from experimentation to deployment and monitoring. Agent Builder, complementing Model Garden, simplifies the creation of generative AI agents for enterprise use cases. It offers no-code and low-code interfaces, enabling business users and developers to build agents that can interact with internal databases, CRM systems, and other enterprise applications, all while adhering to strict security and compliance standards. These tools are crucial for businesses looking to integrate advanced AI into their operations at scale.
Google provides a robust set of tools for developers to build with AI, alongside deep integrations within its Workspace ecosystem for enhanced productivity.
| Tool | Description | Key Capabilities |
|---|---|---|
| Google Cloud AI Platform | Comprehensive suite of services for building, deploying, and managing AI/ML models. | Managed notebooks, custom training, prediction, MLOps, explainable AI. |
| TensorFlow / Keras | Open-source machine learning framework. | Deep learning model development, distributed training, deployment to various platforms. |
Google’s developer tools ecosystem is rounded out by TensorFlow/Keras, the industry-standard open-source machine learning framework, and the Google Cloud AI Platform, which provides managed infrastructure for training, deploying, and monitoring ML models at enterprise scale. Together, these tools form a comprehensive development environment that supports the entire AI lifecycle, from research and experimentation to production deployment.
7. Workspace & Consumer Integrations
Google’s strategic advantage in the AI race is undeniably its vast ecosystem of widely adopted consumer and enterprise products. The integration of Gemini across these platforms is not merely an add-on but a fundamental rethinking of user interaction and productivity. In Gmail, Gemini acts as an intelligent co-writer, drafting emails, summarizing long threads, and even suggesting follow-up actions, significantly reducing the time spent on correspondence. For Sheets, Gemini can analyze complex datasets, generate formulas, create visualizations, and extract insights from natural language queries, democratizing data analysis for a broader user base. Slides benefits from Gemini’s ability to generate entire presentations from outlines, suggest layouts, and even create custom imagery based on content, transforming the presentation creation process.
Beyond productivity suites, Gemini’s reach extends into everyday consumer experiences. Google Meet now leverages Gemini for real-time transcription, translation, and intelligent meeting summaries, enhancing collaboration across diverse teams. Google Maps is becoming more intuitive, with Gemini-powered search understanding nuanced requests and providing personalized recommendations based on real-time conditions and user preferences. Google Lens, already a powerful visual search tool, is supercharged by Gemini’s multimodal capabilities, allowing for more accurate object identification, detailed information retrieval, and even interactive problem-solving directly from images. On Android devices, Gemini is deeply embedded, offering proactive assistance, intelligent notifications, and a more personalized user interface experience. Chrome AI integrations, such as intelligent tab organization, summarized web pages, and enhanced search capabilities, streamline browsing and information consumption. This pervasive integration strategy ensures that Google’s AI is not just a standalone product but an invisible, yet powerful, assistant woven into the fabric of daily digital life, providing a cohesive and continuously improving user experience across its entire product portfolio.
8. The Competition: Provider-by-Provider Breakdown
The AI landscape in April 2026 is fiercely competitive, with several tech giants and specialized AI labs vying for dominance. Each player brings a unique strategy and set of strengths to the table, pushing the boundaries of what’s possible with artificial intelligence.
OpenAI: Still a formidable force, OpenAI continues to innovate with its GPT series. While perhaps no longer the undisputed leader in raw benchmark scores for all categories, their models, particularly GPT-5.4, remain highly capable and widely adopted. OpenAI’s focus on developer accessibility, robust API offerings, and a strong brand presence keeps them at the forefront. Their investment in frontier research, safety, and alignment remains a core tenet, albeit with increasing scrutiny regarding practical implementation versus theoretical commitments. OpenAI’s strength lies in its broad ecosystem of integrations and a developer community that has grown accustomed to its models.
Anthropic: Anthropic, with its Claude series (Opus 4.6 and Sonnet 4.6), has carved out a significant niche, particularly emphasizing safety, interpretability, and ethical AI development. Their “Constitutional AI” approach resonates with enterprises and researchers prioritizing responsible deployment. Claude models often excel in long-context understanding and complex reasoning tasks, making them highly valuable for specific applications requiring deep textual analysis and nuanced interaction. While their overall ecosystem might not be as broad as Google’s or Microsoft’s, their model performance and commitment to safety make them a critical contender, especially in regulated industries.
Microsoft: Microsoft’s strategy is deeply integrated with OpenAI, leveraging their models across its Azure cloud platform and Copilot suite. This partnership provides Microsoft with cutting-edge AI capabilities, which it then seamlessly embeds into its enterprise products like Microsoft 365, Dynamics, and Power Platform. Microsoft’s strength lies in its unparalleled enterprise reach and its ability to deliver AI solutions at scale to businesses worldwide. Their focus is on empowering professional productivity and automating complex business workflows, making AI a core component of their cloud services.
Meta: Meta’s approach is dual-pronged: advancing open-source AI research with models like Llama and integrating AI heavily into its consumer social media platforms. While Llama models have significantly impacted the open-source community, fostering rapid innovation, Meta’s consumer-facing AI is focused on enhancing user experience, content moderation, and advertising effectiveness across Facebook, Instagram, and WhatsApp. Their vast data resources provide a unique training ground, but their primary competitive advantage lies in the sheer scale of their user base and the potential for AI-driven personalization and interaction within their apps.
xAI: Elon Musk’s xAI, with Grok, represents a disruptive force. While still a newer entrant, xAI aims for “maximal truth-seeking AI,” often with a more irreverent and unfiltered persona. Grok’s integration with the X platform (formerly Twitter) provides it with real-time information access, making it particularly adept at current events and trending topics. While its market share is smaller, its unique approach and direct integration with a major social platform present a distinct competitive angle, appealing to users seeking a different kind of AI interaction. Its long-term impact will depend on its ability to scale and refine its core capabilities beyond its initial niche.
9. Benchmark Showdown: April 2026 Numbers
The performance of frontier AI models is rigorously measured across a suite of benchmarks designed to test various facets of intelligence, reasoning, and practical application. As of April 2026, the competitive landscape reveals distinct strengths and weaknesses among the leading models.
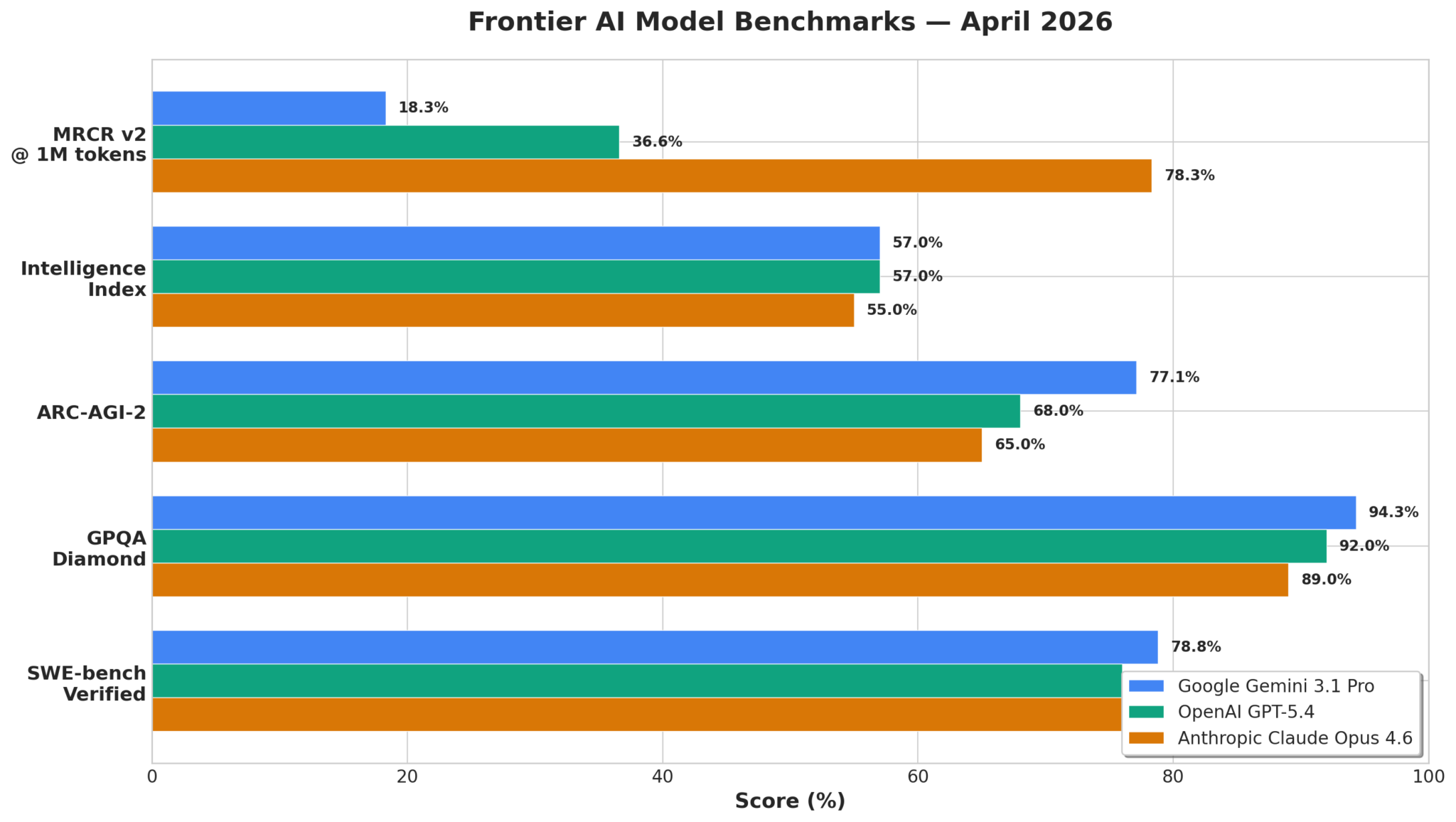
GPQA Diamond: This benchmark assesses general knowledge and reasoning in highly specialized academic domains. Google’s Gemini 3.1 Pro stands out, achieving an impressive 94.3%. OpenAI’s GPT-5.4 follows closely with 92.0%, demonstrating strong capabilities in this area. Anthropic’s Claude Opus 4.6, while very capable, trails slightly at 89.0%. This indicates Gemini’s superior ability to synthesize and apply complex information across a broad range of challenging academic questions.
SWE-bench Verified: This benchmark evaluates a model’s ability to resolve real-world software engineering issues from GitHub repositories. The top models are extremely close here, highlighting a significant advancement in code generation and debugging. Gemini 3.1 Pro leads marginally with 78.8%, closely followed by Claude Opus 4.6 at 78.3%, and GPT-5.4 at 78.0%. This near parity suggests that all three models have reached a very high level of proficiency in understanding, diagnosing, and fixing code.
ARC-AGI-2: Designed to test abstract reasoning and generalization, this benchmark is crucial for evaluating a model’s ability to learn from limited examples and apply principles to novel situations. Gemini 3.1 Pro demonstrates a clear lead here with 77.1%, significantly outperforming GPT-5.4 at 68.0% and Claude Opus 4.6 at 65.0%. This performance underscores Gemini’s advanced capabilities in complex problem-solving and adaptive intelligence, crucial for tasks requiring true “understanding” beyond pattern matching.
MRCR v2 (Massive Reading Comprehension and Reasoning): This benchmark measures deep reading comprehension and multi-hop reasoning. Interestingly, the results show a more distributed leadership. Claude Opus 4.6 excels here with 78.3%, indicating its strong ability to process and reason over vast amounts of text. GPT-5.4 also performs well at 36.6%, while Gemini 3.1 Pro shows a score of 18.3%. This suggests that while Gemini excels in abstract reasoning, Claude Opus 4.6 maintains an edge in tasks requiring extensive textual analysis and synthesis.
Intelligence Index: This composite score provides an overall snapshot of a model’s general intelligence across various tasks. Both Gemini 3.1 Pro and GPT-5.4 achieve an identical Intelligence Index of 57.0%, reflecting their balanced capabilities across a wide spectrum of AI tasks. Claude Opus 4.6 is a close third with 55.0%. This metric confirms that while individual benchmarks highlight specific strengths, the top models are converging on a high level of generalized intelligence.
The April 2026 benchmarks illustrate Google’s robust position with Gemini 3.1 Pro, particularly in abstract reasoning and generalized intelligence. However, the competition, especially from Claude Opus 4.6 in reading comprehension and GPT-5.4 across multiple metrics, remains fierce, ensuring continued innovation in the field.

10. Pricing & Value: The Cost of Intelligence
The cost-effectiveness of large language models is a critical factor for developers and businesses integrating AI into their applications. As of April 2026, API pricing strategies vary significantly across providers, reflecting differences in model capabilities, infrastructure costs, and market positioning. The primary pricing model revolves around the number of tokens processed, often distinguishing between input (prompt) and output (completion) tokens.
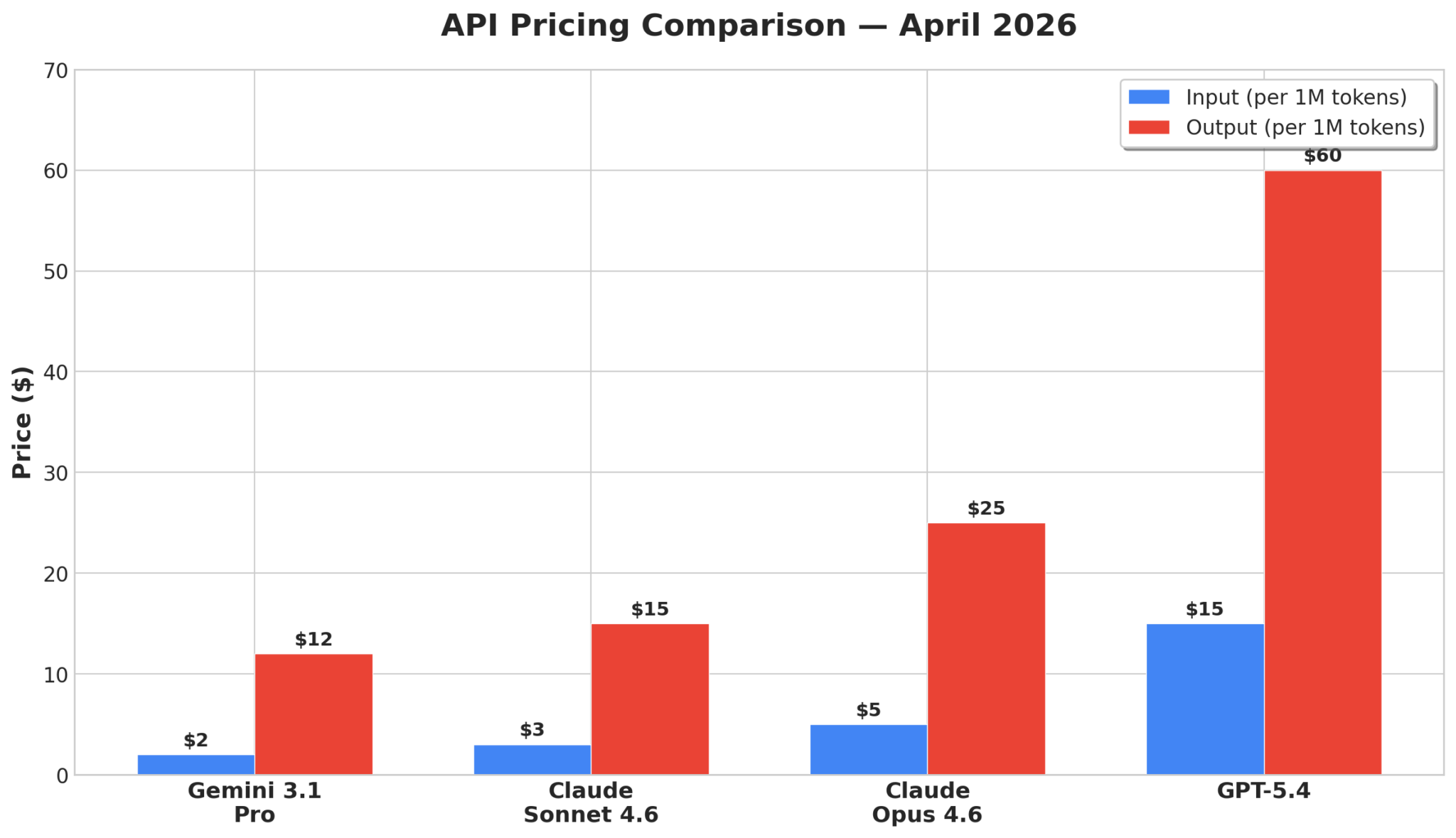
API Pricing Comparison:
Google’s Gemini 3.1 Pro currently offers a highly competitive pricing structure at $2 per million input tokens and $12 per million output tokens. This aggressive pricing positions Gemini 3.1 Pro as a leader in value, especially considering its strong benchmark performance across many categories. This strategy aims to encourage widespread adoption and integration into a multitude of applications.
Anthropic’s Claude models present a tiered pricing approach. Claude Sonnet 4.6, designed for everyday tasks, is priced at $3 per million input tokens and $15 per million output tokens, making it a competitive option for less demanding workloads. The more powerful Claude Opus 4.6, tailored for complex reasoning, is priced higher at $5 per million input tokens and $25 per million output tokens. While more expensive, its superior performance in specific areas like MRCR v2 might justify the cost for specialized applications.
OpenAI’s GPT-5.4, a top-tier model, comes with a premium price tag of $15 per million input tokens and $60 per million output tokens. This reflects OpenAI’s established market position and the perceived value of their flagship model, though it is significantly pricier than its direct competitors. For businesses with ample budget and a need for the latest OpenAI technology, this might still be a viable option.
The pricing comparison reveals a clear trend: Google is aggressively undercutting competitors on price while maintaining high performance, aiming for market share and broad developer adoption. Anthropic offers a balanced approach with a more affordable “Sonnet” model and a premium “Opus” for specialized needs. OpenAI maintains a premium pricing strategy, likely banking on its brand and existing ecosystem.

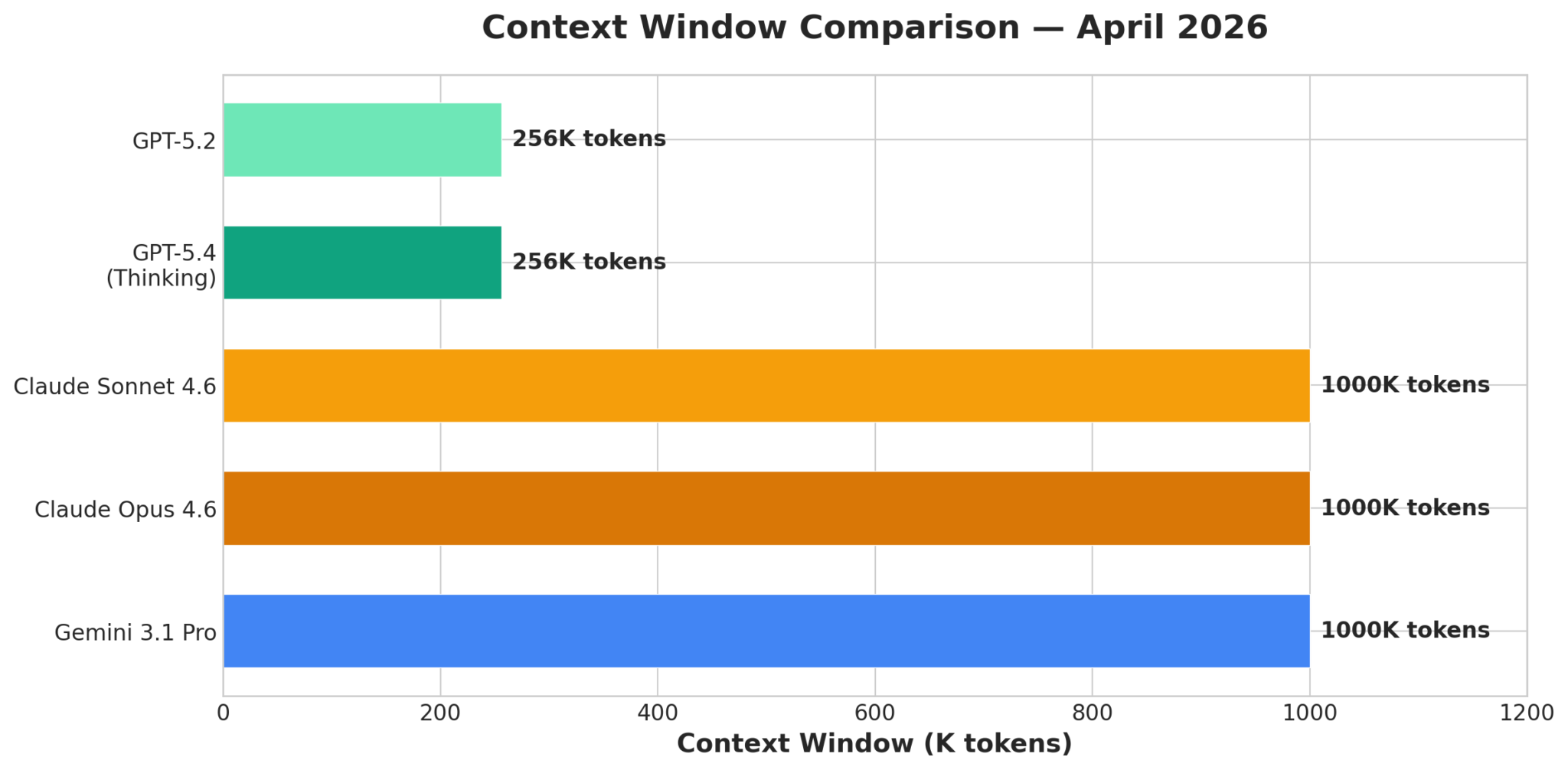
Context Window Comparison:
Another crucial aspect of value is the context window size, which dictates how much information a model can process and retain in a single interaction. A larger context window allows for more complex instructions, longer documents, and more coherent multi-turn conversations without losing track of the conversation history.
As of April 2026, Google’s Gemini 3.1 Pro leads the pack with an impressive 1 million token context window. This massive capacity allows it to handle entire books, extensive codebases, or protracted dialogues, making it incredibly versatile for enterprise applications requiring deep understanding of large documents. Anthropic’s Claude Sonnet 4.6 and Claude Opus 4.6 also boast a 1 million token context window, matching Gemini’s capability in this regard. This shared strength makes both Google and Anthropic models highly attractive for tasks like legal document analysis, comprehensive research, and long-form content generation.
In contrast, OpenAI’s GPT-5.2 and GPT-5.4 models are limited to a 256,000 token context window. While still substantial, this is significantly smaller than the 1 million token offerings from Google and Anthropic. This limitation means that for extremely long documents or very extended conversations, developers using OpenAI models might need to implement more complex retrieval-augmented generation (RAG) strategies or break down inputs, potentially increasing latency and cost. The smaller context window for OpenAI models represents a competitive disadvantage for applications that are inherently context-heavy.
In summary, while OpenAI’s models remain powerful, Google and Anthropic are offering superior value in terms of both raw API pricing and the crucial context window size, positioning them strongly for a wide range of demanding AI applications.

11. Creative Tools Face-Off
The realm of generative AI for creative endeavors—image, video, and music generation—is a battleground of innovation, with each major player pushing the boundaries of what machines can produce. As of April 2026, the capabilities have become remarkably sophisticated, moving beyond mere novelty to genuinely useful tools for artists, designers, and content creators.
Image Generation:
Google’s Imagen 3, powered by Gemini’s multimodal understanding, excels in generating photorealistic images and intricate artistic styles with high fidelity and contextual accuracy. Its ability to understand complex prompts, incorporate diverse visual elements, and maintain compositional coherence is a significant strength. Google’s deep integration with its existing creative suite and cloud services also provides a seamless workflow for professional artists.
OpenAI’s DALL-E 4 continues to be a strong contender, particularly known for its imaginative and often surreal outputs. DALL-E’s strength lies in its ability to interpret abstract concepts and generate unique visual interpretations, making it a favorite for conceptual art and brainstorming. However, its photorealism can sometimes lag behind Imagen 3 in terms of subtle details and nuanced lighting.
Midjourney V7, while not directly tied to a large language model ecosystem in the same way, remains a dominant force for artistic and stylistic image generation. Its community-driven development and focus on aesthetic quality often yield stunning results, particularly in specific artistic styles. However, its integration into broader workflows might require more manual effort compared to Google’s or OpenAI’s offerings.
Video Generation:
Google’s Lumiere, a text-to-video and image-to-video model, has made significant strides, generating high-quality, consistent video clips up to several seconds long. Its unique Space-Time U-Net architecture allows for more coherent motion and temporal consistency, addressing a major challenge in earlier video generation models. Google’s research in this area is deeply integrated with Gemini’s understanding of narrative and scene composition.
OpenAI’s Sora, while still in limited access, has demonstrated groundbreaking capabilities in generating highly realistic and complex video scenes from text prompts. Its ability to simulate physical world interactions and maintain object permanence over longer durations is particularly impressive. Sora’s potential impact on film and media production is immense, though its widespread availability and cost-effectiveness remain to be seen.
Meta’s Make-A-Video and other research efforts are also contributing to the video generation space, often focusing on shorter, social media-optimized clips and exploring various animation styles. While perhaps not yet matching the photorealism of Sora or the consistency of Lumiere, Meta’s open-source contributions are fostering rapid advancements in the field.
Music Generation:
Google’s MusicLM, leveraging Gemini’s understanding of musical structure, genre, and emotion, can generate high-fidelity music from text descriptions. Its ability to create instrumental pieces, soundscapes, and even short jingles with specific instrumentation and mood is quite advanced. Integration with YouTube’s vast music library provides a rich training ground and potential for future applications.
OpenAI’s Jukebox, while an earlier entrant, showcased the potential of neural networks for music generation, producing diverse styles with vocal capabilities. More recent models from OpenAI continue to refine this, focusing on longer compositions and greater control over musical parameters. Their research often explores the intersection of music and language, allowing for more nuanced prompt-to-music translation.
Other players like Stability AI with Harmonai are also making significant contributions to open-source music generation, often focusing on specific genres or instrumentations. The music generation landscape is rapidly evolving, with a strong focus on empowering musicians and content creators with new compositional tools. The competition is driving models towards greater coherence, longer generation lengths, and more granular control, transforming how music can be created and consumed.
12. Ecosystem Breadth: Who Covers the Most Ground?
When evaluating the leading AI providers in April 2026, the breadth of their respective ecosystems is as crucial as the raw performance of their flagship models. An expansive ecosystem signifies not only technological prowess but also strategic integration, market penetration, and the ability to deliver AI solutions across diverse industries and consumer needs.
Google: Google’s AI ecosystem is arguably the broadest and most deeply integrated. Its strength lies in the pervasive embedding of Gemini across its core products: Search, Android, Chrome, Gmail, Google Workspace (Docs, Sheets, Slides), Maps, Photos, YouTube, and its extensive cloud platform, Google Cloud. This means AI is not an add-on but a fundamental layer enhancing user experience and productivity in billions of daily interactions. From consumer-facing features like intelligent search and personalized recommendations to enterprise solutions for data analytics and workflow automation, Google covers a vast spectrum. Its research arm (DeepMind, Google Brain) consistently pushes frontier AI, which then feeds directly into its product development. The open-source contributions (e.g., TensorFlow) also foster a massive developer community, further extending its reach.
Microsoft (with OpenAI): Microsoft’s ecosystem breadth is formidable, largely powered by its strategic partnership with OpenAI. Through Azure AI, Microsoft offers OpenAI’s advanced models (GPT-5.4, DALL-E 4, Sora) to its vast enterprise customer base. The “Copilot” initiative integrates AI across Microsoft 365 (Word, Excel, PowerPoint, Outlook), Windows, GitHub, and its Dynamics 365 suite. This provides a powerful, enterprise-grade AI solution that leverages Microsoft’s existing dominance in business software. While the core AI models are from OpenAI, Microsoft’s ability to productize and deliver them at scale to businesses worldwide is its unique advantage. Their consumer AI presence is growing, but their primary focus remains the enterprise.
OpenAI: While OpenAI leads in cutting-edge model development and has a strong developer community through its APIs, its ecosystem is primarily centered around its core models and the applications built directly on them. Its direct consumer products are fewer compared to Google or Microsoft, relying more on third-party integrations and partnerships. However, its influence on the broader AI landscape through its research and model releases is immense, driving innovation across the industry. Their ecosystem strength is in being the foundational model provider for many applications.
Anthropic: Anthropic’s ecosystem is more specialized, focusing on enterprise clients and applications that prioritize safety, interpretability, and long-context reasoning. While their models (Claude Opus/Sonnet 4.6) are highly capable, their direct consumer integrations are limited. Their strength lies in their appeal to regulated industries and those building highly reliable and ethical AI systems. Their ecosystem is growing, but it’s more concentrated on specific high-value use cases rather than broad consumer reach.
Meta: Meta’s ecosystem is centered around its vast social media platforms (Facebook, Instagram, WhatsApp) and its open-source AI initiatives (Llama). AI is deeply integrated into content recommendation, moderation, advertising, and user engagement across its consumer apps. Its open-source Llama models contribute significantly to the broader AI community, fostering innovation that indirectly benefits Meta. However, its enterprise offerings are less developed compared to Google or Microsoft, and its consumer AI is primarily confined to its own platforms.
xAI: xAI’s ecosystem is currently nascent, primarily revolving around its Grok model and its integration with the X platform. While providing unique real-time insights from X data, its broader ecosystem reach into diverse applications or enterprise solutions is still in its early stages. Its strength is its niche integration and distinctive persona, but it lacks the widespread product integration or developer ecosystem of the larger players.
In conclusion, Google holds the lead in ecosystem breadth due to its unparalleled integration across consumer and enterprise products. Microsoft, leveraging OpenAI, offers a strong enterprise-focused ecosystem. OpenAI and Anthropic excel as foundational model providers, while Meta and xAI focus on their respective platform-specific applications and open-source contributions.
13. The Verdict: Who Wins What in April 2026
As of April 2026, the AI landscape is characterized by intense competition and rapid innovation. While no single company dominates every facet, specific strengths and strategic advantages have emerged, leading to distinct winners in various categories. Here’s a breakdown of who leads where:
Overall AI Leadership (Generalized Intelligence & Ecosystem): Google
Google, with its Gemini 3.1 Pro, emerges as the overall leader in generalized AI intelligence, evidenced by its top performance in GPQA Diamond, ARC-AGI-2, and a shared lead in the Intelligence Index. Combined with its unparalleled ecosystem breadth—embedding AI across Search, Android, Workspace, Maps, and Chrome—Google offers the most comprehensive and deeply integrated AI experience for both consumers and enterprises. Its aggressive pricing and leading context window further solidify its position as the most accessible and powerful general-purpose AI provider.
Raw Model Performance (Specific Benchmarks):
- Abstract Reasoning (ARC-AGI-2): Google Gemini 3.1 Pro (77.1%)
- General Knowledge & Reasoning (GPQA Diamond): Google Gemini 3.1 Pro (94.3%)
- Software Engineering (SWE-bench Verified): Google Gemini 3.1 Pro (78.8%) – (a very narrow lead over Claude Opus 4.6)
- Deep Reading Comprehension (MRCR v2): Anthropic Claude Opus 4.6 (78.3%)
- Overall Intelligence Index: Google Gemini 3.1 Pro & OpenAI GPT-5.4 (tied at 57.0%)
Value & Accessibility (API Pricing & Context Window): Google & Anthropic (Shared Win)
Google’s Gemini 3.1 Pro offers the best overall value with its $2/$12 per million token pricing and a leading 1M token context window. Anthropic’s Claude Sonnet 4.6 provides excellent value at $3/$15 per million tokens and also boasts a 1M token context window, making both Google and Anthropic strong contenders for developers seeking cost-effective and context-rich solutions. OpenAI’s GPT-5.4, while powerful, is significantly more expensive and has a smaller context window, making it less competitive on pure value metrics.
Enterprise Integration & Productivity: Microsoft (with OpenAI)
Leveraging OpenAI’s models through Azure AI and the comprehensive Copilot suite, Microsoft remains the undisputed leader in bringing AI to the enterprise. Its deep integration into Microsoft 365, Windows, and Dynamics 365 provides unparalleled productivity enhancements and workflow automation for businesses of all sizes. Microsoft’s existing enterprise relationships and robust cloud infrastructure make it the go-to for large-scale business AI adoption.
Creative Generative AI (Image & Video): OpenAI & Google (Shared Win)
In creative generative AI, it’s a neck-and-neck race. OpenAI’s Sora has demonstrated groundbreaking video generation capabilities, while DALL-E 4 remains a strong image generator. However, Google’s Imagen 3 for photorealistic images and Lumiere for consistent video generation are equally impressive and often offer better integration with existing creative workflows. The rapid pace of innovation in this sector means leadership can shift quickly, but both are pushing the boundaries significantly.
Ethical & Safety-Focused AI: Anthropic
Anthropic, with its “Constitutional AI” and strong emphasis on safety and interpretability, continues to lead in the domain of ethical AI development. For organizations where responsible AI deployment and mitigating risks are paramount, Claude Opus 4.6 is the preferred choice, offering a transparent and controllable approach to AI behavior.
Open Source & Community Impact: Meta
Meta’s commitment to open-sourcing its Llama models has profoundly impacted the broader AI community, accelerating research and development across countless startups and academic institutions. While its consumer AI is platform-specific, its open-source contributions foster innovation across the entire ecosystem.
Real-Time Information & Niche Integration: xAI
xAI’s Grok, with its direct integration into the X platform, holds a unique advantage in accessing and processing real-time information and trending topics. While a niche player, its ability to provide immediate, contextually relevant responses based on live data is a distinct strength.
In conclusion, while Google shows a strong overall lead due to its balanced performance, aggressive pricing, and unparalleled ecosystem integration, the AI landscape remains dynamic. Each major player has carved out significant strengths, ensuring continued innovation and a diverse range of powerful AI solutions for various needs.
Unlock the Power of AI
Ready to integrate cutting-edge AI into your projects and elevate your productivity? Explore Google’s Gemini ecosystem today and discover how its advanced capabilities, competitive pricing, and vast context window can transform your work.
Explore More AI Guides & Tutorials
Join thousands of AI enthusiasts and professionals who rely on ChatGPT AI Hub for the latest insights.


