



Authors:
(1) Kinjal Basu, IBM Research;
(2) Keerthiram Murugesan, IBM Research;
(3) Subhajit Chaudhury, IBM Research;
(4) Murray Campbell, IBM Research;
(5) Kartik Talamadupula, Symbl.ai;
(6) Tim Klinger, IBM Research.
Table of Links
Abstract and 1 Introduction
2 Background
3 Symbolic Policy Learner
3.1 Learning Symbolic Policy using ILP
3.2 Exception Learning
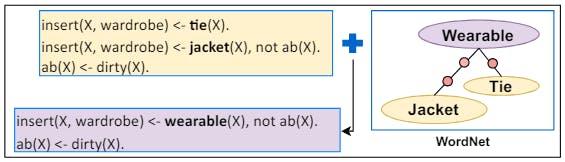
4 Rule Generalization
4.1 Dynamic Rule Generalization
5 Experiments and Results
5.1 Dataset
5.2 Experiments
5.3 Results
6 Related Work
7 Future Work and Conclusion, Limitations, Ethics Statement, and References
3.1 Learning Symbolic Policy using ILP
Data Collection: To apply an ILP algorithm, first, EXPLORER needs to collect the State, Action, and Reward pairs while exploring the text-based environment. In a TBG, the two main components of the state are the state description and the inventory information of the agent. The entities present in the environment are extracted by parsing the state description using the spaCy library, and only storing the noun phrases (e.g., fridge, apple, banana, etc.) in predicate form. We also extract the inventory information in a similar way. At each step of the game, the game environment generates a set of admissible actions, one among them being the best; as well as action templates (e.g., “insert O into S”, where O and S are entity types) which are predefined for the agent before the game starts. By processing these templates over the admissible actions, EXPLORER can easily extract the type of each entity present in the environment and then convert them to predicates. Figure 3 illustrates an instance of a predicate generation process. Along with this State description, EXPLORER also stores the taken Action and the Reward information at each step.




Data Preparation: To learn the rules, an ILP algorithm requires three things – the goal, the predicate list, and the examples. The goal is the concept that the ILP algorithm is going to learn by exploring the examples. The predicates give the explanation to a concept. In the learned theory formulated as logical rules, goal is the head and the predicate list gives the domain space for the body clauses. The examples are the set of positive and negative scenarios that are collected by the agent while playing.
Execution and Policy Learning: In our work, we have mainly focused on learning the hypothesis for the rewarded actions; however, we also apply reward shaping to learn important preceding actions (e.g., open fridge might not have any reward, although it is important to take an item from fridge and that has a reward). In both the TWCooking domain and TextWorld Commonsense (TWC), the action predicates mostly have one or two arguments (e.g., open fridge, insert cheese in fridge, etc.). In the one-argument setting, the action becomes the ILP goal and the examples are collected based on the argument. In the twoargument setting, we fix the second argument with the action and collect examples based on the first argument. The goal will hence be in the form of . We split the examples (i.e., state, entity types, inventory information



in predicate form) based on the stored rewards (positive and zero/negative). We use entity identifiers to identify each entity separately; this is important when there are two or more instances of the same entity in the environment with different features (e.g., red apple and rotten apple). Additionally, EXPLORER creates the predicate list by extracting the predicate names from the examples. After obtaining the goal, predicate list, and the example, the agent runs the ILP algorithm to learn the hypothesis, followed by simple string post-processing to obtain a hypothesis in the below form:



3.2 Exception Learning
As EXPLORER does online learning, the quality of the initial rules is quite low; this gradually improves with more training. The key improvement achieved by EXPLORER is through exception learning, where an exception clause is added to the rule’s body using Negation as Failure (NAF). This makes the rules more flexible and able to handle scenarios where information is missing. The agent learns these exceptions by trying the rules and not receiving rewards. For example, in TWC, the agent may learn the rule that – apple goes to the fridge, but fail when it tries to apply the rule to a rotten apple. It then learns that the feature rotten is an exception to the previously learned rule. This can be represented as:



It is important to keep in mind that the number of examples covered by the exception is always fewer than the number of examples covered by


the defaults. This constraint has been included in EXPLORER’s exception learning module.



{kind=link}