


Table of Links
Abstract and 1. Introduction
-
Key Concepts
2.1 Append-Only Log and 2.2 Virtual Machine State
2.3 Transactions As Curried Functions
2.4 Natural Names of State
2.5 Ground Truth
2.6 Efficient Representations of State
2.7 Checkpoints
2.8 Execution Parameters: callData
2.9 Execution Ordering
2.10 Deciding on the Correct State
-
Ideal Layer 2 Design
3.1 VM Job Queue and Transaction Order Finality
3.2 Data Availability and Garbage Collection
3.3 State Finality
3.4 Checkpoint Finality
-
Conclusion and References
A. Discrepancy Detection Security Parameters
2.10 Deciding on the Correct State
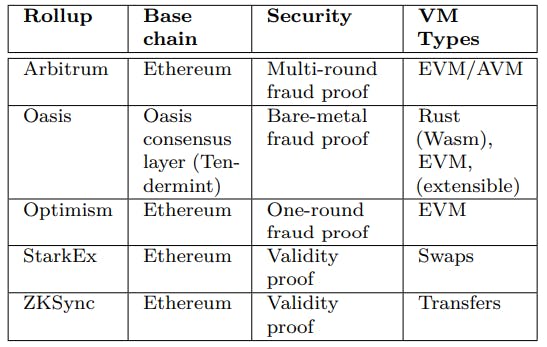
The mechanism by which the correct state is decided is security critical. There are many different design choices that have been explored, with different security assumptions and scaling efficiency. By security assumptions, we mean not only common cryptographic assumptions (e.g., one-way functions), but also compute resources such as hashing power and monetary resources such as control of some fraction of the total stake. By scaling efficiency, we mean both in terms of normal resource usage and in terms of resources needed to achieve a desired level of security. Table 1 shows several different rollups and their state transition security mechanisms.




2.10.1 Proof of Work
While Bitcoin uses a PoW-based log, there is no explicit decision to be made about the correct state since no state is recorded.
In Ethereum v1, PoW is used and hashing is the resource bottleneck. All miners are validators, and the security assumption is that malicious actors cannot control more than half of the hashing power or mount a “51% attack.” Here, validation means re-executing the transactions to verify that the new stateRoot matches. Invalid blocks are ignored and not considered as extending the chain.
One issue is that even though it appears that all miners independently validate transactions, the incentives for rational miners are to behave otherwise. Because the execution order and stateRoot must be placed in the same block and thus are tightly coupled, there is a performance advantage for small miners to join together and form a mining pool/cooperative. Rather than individual miners re-executing transactions from the block to compute the stateRoot, a mining pool could compute the stateRoot once on the pool’s fastest machine, and then devotes all of their compute power to solving the hash puzzle. This obviously also centralizes what would have been replicated transaction executions, robbing the system of the degree of independent verification represented by the mining pool members.
This is not (yet) an acute problem, since hashing costs dominate that of VM execution to process the transactions, and the savings from sharing stateRoot is not significant. The incentive to do so increases if/when the gas limit becomes high enough so that VM execution cost becomes noticeable.
2.10.2 Proof of Stake
Ethereum v2, Cosmos, etc are PoS based blockchains.
All consensus committee members are also validators, and the security assumption is that malicious actors cannot amass more than a supermajority (usually 2/3) of the total stake. Validators earn block rewards. Stake-based voting and reward distribution remove most of the incentives to mount Sybil attacks, but does not address other attacks such as exploiting zero days, which are common-mode faults.
2.10.3 ZK Rollups
Zero-knowledge (ZK) rollups use zkSNARKs to prove the correctness of the rollup virtual machine execution. Because security proof verification is involved, a single honest verifier is enough to keep the executor/prover honest.
The key idea is that proof verification is very cheap; thus, the security parameter for the number of validator—proof verifiers—can be easily increased. Unfortunately, proof generation is relatively expensive, so while payment transactions are feasible (ZCash [7]), the case for general smart contract computation is more difficult. Proof generation for Ethereum-style computation is being developed/researched (zkEVM [11]). It remains to be seen how good a scaling solution this represents, since the rollup where the proof generation occurs may be slow/resource intensive, so even though the underlying blockchain might be able to run bridge contracts for many ZK rollup rollups, the aggregate throughput and efficiency may still be insufficient for general, complex applications.
The proof verification algorithm takes time to run. This should be done within the bridge contract, and the typical description of ZK rollups is that an invalid proof is treated as if no proof were submitted, i.e., bridge contract aborts the faux proof submission transaction. As long as there is enough replication in the underlying blockchain so that the consensus there reflects the correct execution of proof verification, the security of the rollup is guaranteed.
2.10.4 Optimistic Rollups
In optimistic rollups, validators are any entity that can re-execute the transactions and compare the resultant state. An executor commits its result as a Disputable Assertion (DA) to the underlying blockchain, and any validator that finds a discrepancy can issue a challenge (and the validator becomes a challenger). After dispute resolution, if the DA is found to be incorrect, the executor is slashed and the successful challenger earns a reward. This means a single honest validator is enough to keep the executor honest.
Validators must be given time to re-execute the transactions and to generate challenges. Because reexecution is more expensive, this can create a significant delay for state finality: a DA is only considered accepted when the disputation period has passed. The appropriate length of the disputation period depends on the maximum gas allowed in a rolled up batch of transactions and other factors; current designs allow as much as a week.
In Arbitrum, users are expected to not have to wait for the disputation period, based on the notion of “trustless finality”. The scenario is that a user has submitted a transaction and it is in-flight: a DA includes it, but the disputation period has not yet passed. The user wishes to propose a new transaction that depends on its result. If there are doubts about the DA, the user might be hesitant to propose the new transaction. The argument is that since the user could act as a validator and re-execute all the transactions leading up to the DA and thus independently validate their mental model of system state, they should be able to freely submit their new transaction proposal. This is essentially using transaction order finality: users trust the underlying blockchain’s recording of the rollup transaction order and that the VM is defined and implemented correctly to be deterministic.
Another argument is because having multiple executors/validators is feasible. Here, they can post additional DAs (for new transactions) that depend on earlier DAs that have not yet reached state finality. These additional DAs provide additional assurance that the earlier DAs are correct, since presumably the new dependent DAs have validated the earlier DAs. Currently, Arbitrum has a single centralized executor, though anyone can be a validator/challenger.
Verifiers suffer from the verifier’s dilemma [10, 5]. Even though proof verification might be cheap, it is cheaper still to assume that somebody else has done the verification, when the odds that an executor will try to cheat appears to be low.
2.10.5 Bare-Metal Fraud Proofs
The bare-metal fraud proof approach is a traditional fast-path / slow-path approach seen in systems design, where the fast path efficiently handles the common case, with a slower path that acts as a fallback for the uncommon case(s). Here, a single honest node in the fast path suffices to trigger slow-path verification. It as agnostic with respect to the rollup VM, since there is no need to single-step VM execution to find exactly where an error occurred. To understand the bare-metal fraud proof approach, it is useful to understand the system architecture.
The bare-metal fraud proof approach can be viewed as a form of optimistic rollup, but with a committee of nodes executing in parallel verifying each other rather than taking the executor vs challenger view. The VM execution of smart contracts is separated from consensus. There are two types of committees: a consensus committee executing a consensus protocol, and one or more compute committees executing the VM—similar to rollup executors running smart contracts off-chain—doing the heavier lifting of general smart contract execution. The consensus layer records the resultant VM state from the compute committee.
Unlike the consensus committee which runs a single consensus protocol, we view the compute layer as running two protocols: the fast-path protocol of discrepancy detection (DD), where we can use a smaller sized primary committee; and the slow-path protocol of discrepancy resolution (DR), where a (much) larger backup committee would be used. The goal, which is justified by the security parameter calculations (see Appendix A), is to use small primary committees without compromising security. This is the source of the efficiency improvement of the bare-metal fraud proof approach: the amount of replicated computation is significantly reduced in the fast path, with an incentive design such that the slow path should never be used.
Note that transaction ordering is an orthogonal design decision from the use of DD/DR. It can be decoupled and committed to the consensus layer as separate log entries prior to smart contract execution, or a leader from the compute committee could be selected (possibly rotating) to choose an execution order from the available transaction proposals.
However execution schedules are determined, all members of the compute committee run in parallel and determines the state that would result from the execution of a batch of transactions. Compute committee members sign their computed output states. Equivocation is punished by slashing stake like in many consensus designs, and we will assume that each committee member will sign at most one state as the result from the execution of a batch of transactions henceforth.
The key idea behind DD is that when all compute committee members agrees on the resultant state, we can commit it to the log, and this is secure as long as the size of the primary compute committee has enough members so that the probability that none of the reporting members are honest is negligibly small. If there is any disagreement among the primary committee member, we do not know which of the reported output states is correct—this is the key difference from other state validation schemes: DD only performs error detection and not error correction. Instead, we switch to the DR protocol with the larger backup committee, and that output state is deemed to be the correct one. In essence, the DR protocol is a parameter to the bare-metal fraud proof approach: the DR protocol can use a much larger committee—even all available nodes—and use much more resources. Because those DD nodes that reported a differing output state from that determined by DR will have their stake slashed, there is no incentive to deviate from the protocol unless the adversary can either control the entire DD committee or enough of the backup committee for DR to fail.
Note that the choice of DR does not have to only involve larger committees: we could use a bisection algorithm to find the single VM instruction at which the computation of the two (or more) resultant states first diverged [14, 8]. While this approach is great from an algorithmic standpoint, it is challenging to implement since the entire VM instruction set must be re-implemented in the bridge contract to see which instruction executed incorrectly and thus resolve the discrepancy. Maintaining VM agnosticism allows the system greater flexibility: a VM can be designed to allow the VM programs to be compiled to (sandboxed) native code, allowing applications such as data analysis that is not currently feasible on blockchains or rollups.
The consensus layer accepting and committing a state from DD/DR yields state finality. Just as an exploit using zero-day vulnerability/bug in implementation would be a common-mode failure in all blockchains is handled using replaying transactions from checkpoints, external challengers can provide evidence of malfeasance even when DD/DR fails. In such a scenario, the transactions since the last checkpoint (or the disputed point) is replayed in the same order, using software with bug fixes applied, to compute the correct state.
The Oasis network is a blockchain system that utilizes the bare-metal fraud proof approach. Multiple rollup VMs or “ParaTimes” are supported. Transaction ordering is handled via a mempool, and a rotating leader in the compute committee chooses the transaction order in its transaction batch. This reduces the number of consensus transactions since transaction order finality is not critical when the rollup execution is fast, though decoupling can be introduced in later iterations as needed. The Oasis ParaTime architecture, where the compute layer results are subject to DD/DR before being committed to the consensus layer, is a minimal rollup design: the bridge contract that validates the rollup VMs is baked-in and only supports DD/DR validation, keeping the consensus layer simple.
Authors:
(1) Bennet Yee, Oasis Labs;
(2) Dawn Song, Oasis Labs;
(3) Patrick McCorry, Infura;
(4) Chris Buckland, Infura.



{kind=link}