



In 2017, the Paper “Attention Is All You Need” of Google changed the technical basis of language generation: the transformers allowed to process long sequences in parallel and climb models to sizes that were previously unfeasible. That climbing route has driven architectures such as GPT and Bert and has converted self -acting into The central piece of generative AI contemporary.
But this new approach was accompanied by growing costs in memory and energy when the context lengthens, a limitation that has motivated research to develop alternatives. Spikingbrain-1.0 aims to break molds.
Of the “attention is all you need” to the brain: the new commitment to break limits in the
A team from the Chinese Academy of Sciences Automation has just presented Spikingbrain-1.0. We are talking about a family of spiky models aimed at reducing data and computation necessary for tasks with very long contexts. The experts propose two approaches: Spikingbrain-7B, of linear architecture focused on efficiency, and spikingbrain-76b, which combines linear attention with Mixture of Experts (MOE) mechanisms of greater capacity.
The authors detail that much of the development and the tests were carried out in clusters of GPU Metax C550, with libraries and operators specifically designed for that platform. This makes the project not only a promising advance at the software level, but also a demonstration of own hardware capabilities. An especially relevant aspect if China’s effort is taken into account to reduce his dependence on Nvidia, a strategy that we have already seen with Deepseek 3.1.


Spikingbrain-1.0 is directly inspired by how our brain works. Instead of having neurons that are always “burning” by calculating numbers, uses spiky neurons: units that accumulate signals until they exceed a threshold and trigger a peak (spike). Between peak and peak they do nothing, which saves operations and, in theory, energy. The key is that not only does it matter how many peaks there are, but when they occur: the exact moment and the order of these peaks carry information, as in the brain.
For this design to work with the current ecosystem, the team developed methods that convert traditional self -acting blocks into linear versions, easier to integrate into its spiky system, and created a kind of “virtual time” that simulates temporal processes without stopping the yield in GPU. In addition, the Spikingbrain-76B version includes Mixture of Experts (MOE), a system that “awakens” only certain submodels when we need, which we have also seen in GPT-4O and GPT-5.

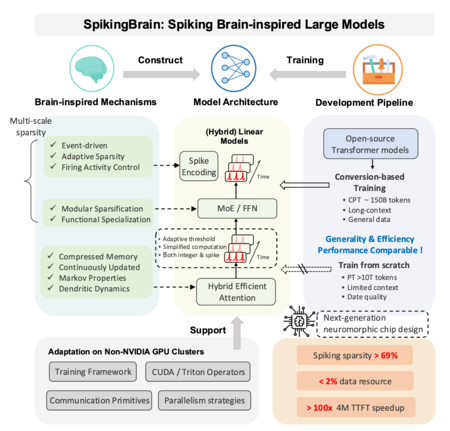

The authors suggest applications where the context length is decisive: analysis of large legal files, complete medical records, DNA sequencing and massive experimental data sets in high energy physics, among others. That lace appears reasoned in the document: if the architecture maintains efficiency in contexts of millions of tokens, would reduce costs and open possibilities in domains today limited by access to very expensive computer infrastructure. But validation in real environments is pending outside the laboratory.


The team has released in Github the code of the 7,000 million parameters version next to a detailed technical report. It also offers a web interface similar to chatgpt to interact with the model, which according to the authors is deployed entirely in national hardware. Access, however, is limited to Chinesewhich complicates its use outside that ecosystem. The proposal is ambitious, but its true scope will depend on the community to reproduce the results and make comparisons in homogeneous environments that evaluate precision, latencies and energy consumption in real conditions.
Imagenes | XATAK CON GEMINI 2.5 | ABOODA VESAKARAN
In WorldOfSoftware | Openai believes having discovered why the IAS hallucinates: they don’t know how to say “I don’t know”



{kind=link}