



Anthropic has announced the release of its latest AI models, Claude Opus 4 and Claude Sonnet 4, which aim to support a wider range of professional and academic tasks beyond code generation.
According to Anthropic, Claude Opus 4 is optimized for extended, focused sessions that involve complex reasoning, context retention and tool use.
Internal testing suggests it can operate autonomously for up to seven hours, making it suitable for tasks that require sustained attention, such as project planning, document analysis and research.
Claude Sonnet 4, which replaces Claude 3.7 Sonnet, is designed to offer faster response times while improving on reasoning, instruction following, and natural language fluency.
It is positioned as a more lightweight assistant for users who need quick, accurate output across writing, marketing, and education workflows.
Key updates in Claude 4
Claude 4 introduces a hybrid reasoning system that allows users to toggle between rapid responses for simple queries and slower, more deliberate processing for in-depth tasks such as writing reports, reviewing documents or comparing research findings.
Both models also support dynamic tool use — including web search, code execution and file analysis — during extended reasoning, allowing for real-time data integration.
Notable upgrades include:
Improved memory: Claude can now remember and reference information across a session when permitted to access local files.
Parallel tool use: The model can multitask across different tools and inputs.
More accurate prompt handling: Claude better understands nuanced instructions, improving consistency for tasks like writing and planning.
Developer tools: Claude Code SDK continues to offer features for programming tasks, now positioned within a broader productivity suite.
Summarized reasoning: Instead of displaying raw output logs, users see clean, accessible summaries of the model’s decision-making process.
Performance and comparisons
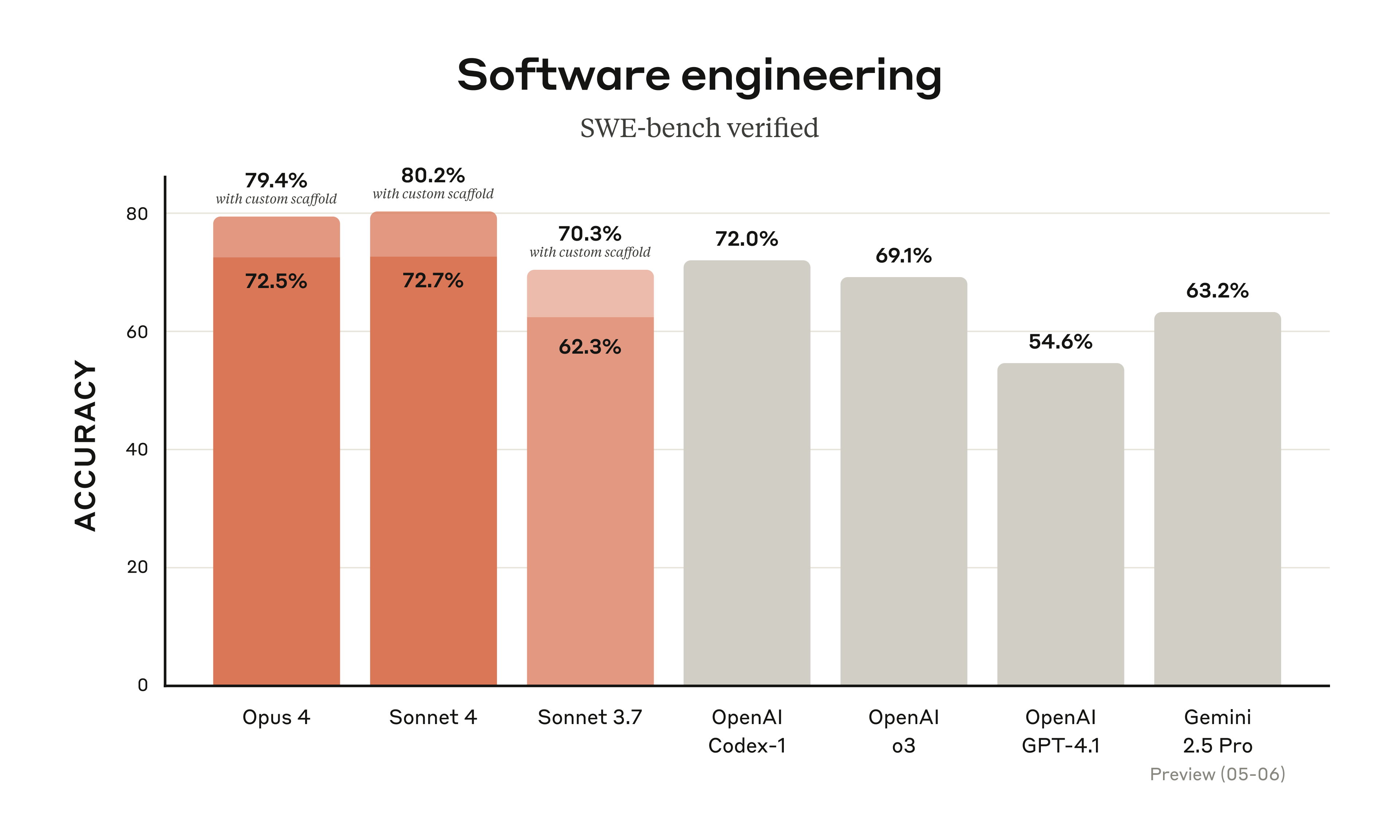

Anthropic reports that Claude Opus 4 scored 72.5% on the SWE-bench Verified coding benchmark, but the model’s focus extends beyond programming. Improvements in long-form writing, structured analysis, and overall task execution suggest it is designed as a general-purpose AI assistant.
Early benchmarks suggest Claude 4 outperforms OpenAI’s GPT-4.1 and Google’s Gemini 1.5 Pro in specific enterprise scenarios, particularly in factual consistency and reliability.
A broader push for utility
Claude 4 appears to be targeting users across multiple fields, including knowledge workers, writers, researchers and students. With support for extended memory, parallel tool use and improved contextual understanding, the new models are intended to function more like collaborative digital assistants than traditional chatbots.
We’ve started putting Claude 4 through its paces, so stay tuned for our hands-on tests.
More from Tom’s Guide

Back to Laptops



{kind=link}