



Table Of Links
Abstract
1 Introduction
2 Background
3 Privacy-Relevant Methods
4 Identifying API Privacy-relevant Methods
5 Labels for Personal Data Processing
6 Process of Identifying Personal Data
7 Data-based Ranking of Privacy-relevant Methods
8 Application to Privacy Code Review
9 Related Work
Conclusion, Future Work, Acknowledgement And References
Data-based Ranking of Privacy-Relevant Methods
Our data-based ranking is designed to identify and prioritize privacy-relevant methods in Java and JavaScript applications. This ranking process comprises several stages, as depicted in Fig. 3, using
the Java ranking as an example. By analyzing data from real-world applications, we aim to provide a practical guide for identifying methods that are most relevant for privacy concerns.
7.1 Library Selection for Data-based Ranking
To focus our data-based ranking on the most relevant libraries, we selected the top 25 libraries from NPM for JavaScript and Maven for Java, shown below in Table 2. Our selection criteria were based on the libraries’ relevance to personal data processing, as aligned with our set of labels for personal data processing activities. This selection was made through a systematic review of each library’s documentation, specifically targeting functionalities that are related to personal data processing.
7.2 Method Invocation Analysis
We employed static analysis tools to identify method invocations and analyze data flows within the code. For Java, we used Soot [14] to construct call graphs and trace method invocations. In the case of JavaScript, we used ESLint 1 for its capabilities in Abstract Syntax Tree (AST) analysis. Our analysis matched these invocations to our list of native privacy-relevant methods, providing a view of how these methods are used in practice.
7.3 Selecting Open-source Applications
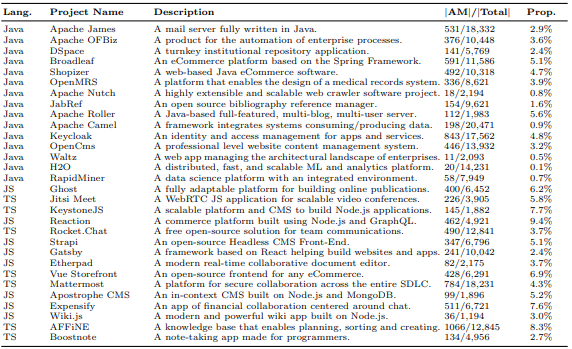
To rank privacy-relevant methods, we selected 30 popular open-source GitHub projects with over 100 stars in Java and JavaScript. We focused on applications processing personal data rather than frameworks and libraries. The selection included 15 Java applications such as the e-commerce software Shopizer, and 15 JavaScript applications like the chat application RocketChat. We also included projects predominantly in Java/JavaScript that use other languages like TypeScript for some modules.
Criteria were: popularity (applications with high stars, indicating broader relevance), data sensitivity (applications processing personal or sensitive data, highly relevant for privacy reviews), diversity (applications from different domains and languages, showing wide applicability), and public availability (open source code enables reproducibility and transparency). The details of these selected projects are provided in Table 4. 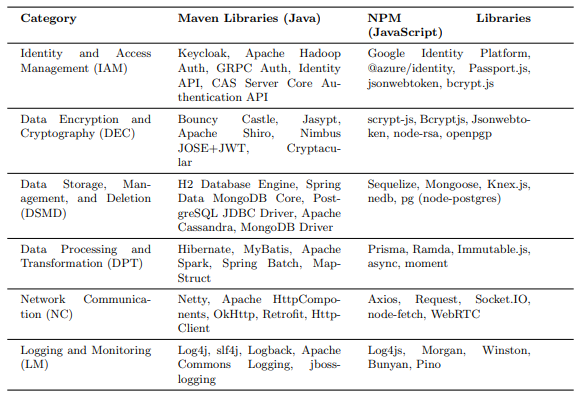

7.4 Efficient Analysis of Library Imports
To make the analysis efficient, we first identified the libraries imported by each application. For standard libraries, we assumed their presence in most applications. For API libraries, we examined import statements and configuration files to narrow down our focus to the top 50 pre-selected libraries, 25 each for Java and JavaScript.
7.5 Ranking Privacy-relevant Methods in Top 30 Applications
We employed Semgrep to monitor the flow of personal data into privacy-relevant methods invoked by application code. Utilizing Semgrep’s DeepSemgrep 2 capability for cross-file analysis, we were able to comprehensively analyze data flows across entire applications, as opposed to only examining isolated code snippets. This provided a holistic perspective of how personal data propagates across different components. Using Semgrep’s taint analysis and the rules outlined in Section 6, we traced personal data flows to privacy-relevant methods.
To assess the practical relevance of our identified privacy-relevant methods, we introduce the following usage-based metrics, presented in Table 3: We ranked privacy-relevant methods by analyzing their usage in the 30 popular GitHub projects introduced above, with an average of 358 application methods processing personal data per application. This varied by language and type: Java applications averaged 288 methods, while JavaScript had 363. The higher average in JavaScript was likely due to its more diverse front-end processing, reflecting the complexity and multifaceted nature of these applications. 

To better focus our approach, we calculated the proportion of application methods that both invoke a privacy-relevant method and process a concrete flow of personal data (there is confirmed personal data flow into the method). This is relative to the total number of methods in the application. This metric indicates the level of focus in identifying privacy-relevant methods, allowing developers to narrow their efforts to a more relevant subset of the code. In essence, our approach aims to minimize the code sections that need scrutiny, saving both time and resources. For more details on these proportions in selected open-source Java and JavaScript/TypeScript applications, see Table 4.

7.6 Findings
Our study reveals that, on average, only 4.2% of the total codebase is made up of methods that are privacy-relevant and involved in personal data processing. This result highlights the precision of our approach in pinpointing privacy-relevant methods in applications.
Usage Patterns of Privacy-Relevant Methods In Java applications, we observed a more conservative use of privacy-relevant methods, particularly those from popular Maven libraries. Native Java methods, along with methods from Apache Commons and the Spring framework, were frequently used for handling personal data. Libraries such as slf4j for logging and auth0 for authentication were also commonly used, indicating their importance in the flow and protection of personal data.
In contrast, JavaScript applications exhibited a diverse range of library usage. While lodash was commonly used, frameworks like Angular, React, and Vue.js played a significant role in personal data processing, particularly in front-end applications. Table 5 presents the top five packages in both Java and JavaScript that contain methods relevant to privacy concerns.


Categories of Privacy-relevant Methods We categorized privacy-relevant methods into types to gain insights into their roles in personal data processing. Our analysis identified several Java classes and categories that are frequently involved in personal data processing. For example, common Java classes like org.slf4j.Logger and auth0.client.Auth0Client are often used in operations that handle personal data.
In terms of categories, Data Processing and Transformation, Network Communication, and Logging Methods were most prevalent. These categories indicate areas where privacy-relevant methods are most commonly used, suggesting that they are key to understanding how personal data is processed in codebases (Table 6). Identity and Access Management, Data Encryption and Cryptography, and Data Storage and Database Management were also highly involved in personal data flows, with involvement percentages of 92%, 78%, and 85%, respectively.
Conversely, categories like Data Processing and Transformation, Network Communication, and Logging Methods were less involved, with percentages of 67%, 44%, and 28%. Table 7 lists Java classes that are frequently involved in personal data processing, serving as key indicators for identifying privacy-relevant methods in applications.
:::info
Authors:
- Feiyang Tang
- Bjarte M. Østvold
:::
:::info
This paper is available on arxiv under CC BY-NC-SA 4.0 license.
:::



{kind=link}