



One of the most important constructs in programming languages is parallelism. Without some form of parallel execution, programs would run considerably slower than they do today. In the industry, parallel execution units are not reserved exclusively for software; both legacy and modern hardware rely heavily on parallel execution units. From multithreading to multicores to clusters to GPU-accelerated systems, parallelism appears in many shapes and sizes. After all, it makes little sense to serialize solving problems that do not depend on each other.
While hardware execution units have parallelism built in, it is the role of system and application developers to fully exploit the machine by understanding its underlying architectures. The goal of this article is to show the fundamental differences between CPU threads and GPU threads, and how GPUs deliberately simplify per-thread control to pack in far more parallelism, which is vital for writing efficient application software targeting modern heterogeneous systems such as CPU–GPU platforms—especially in machine learning and other throughput‑heavy workloads.
Before that, this article will briefly review the basics of hardware and software threads and how programming languages and operating systems abstract them (i) to make life easier for developers and (ii) to hide architectural changes as hardware evolves across generations.
Hardware vs. Software Threads
A high-end CPU like the AMD Ryzen Threadripper PRO 7995WX features 96 cores and 192 threads (2 threads per core). In a multicore design, those 96 cores can each run an independent workload without interfering with one another’s execution resources (to some degree), while the two hardware threads on a core share many of that core’s internal execution units. The extra hardware thread primarily serves to hide latency: when hardware thread A stalls waiting on a memory access, hardware thread B can run and keep the core busy. This approach exists because compute throughput has grown far faster than main-memory latency improvements, even with deep cache hierarchies. Without such forms of concurrency, a large fraction of CPU execution units would sit idle while waiting for data. For simplicity (and as a gross oversimplification), this article will refer to any form of parallel hardware execution unit as a hardware (HW) thread.
While HW thread configurations are fixed in silicon, software (SW) threads are created and scheduled at multiple layers—from applications to language runtimes to operating systems. The goal of a SW thread is to create parallel execution flows in software so it can exploit the available HW threads. Even on hardware that exposes only a single HW thread (common in embedded systems), it is still beneficial to structure software with parallel execution flows for latency hiding: when SW thread A blocks waiting for data from some memory or I/O resource, the system can run SW thread B instead, keeping the CPU productively busy. Whether to preempt thread B or let it continue is a separate scheduling and prioritization question, and a full treatment of those policies lies outside the scope of this article.
A DMV Analogy for Threads
When you enter a DMV (Department of Motor Vehicles) to apply or renew a license or to register or transfer a vehicle title, there are DMV agents waiting to serve you and applicants arriving with different needs. In this analogy, a DMV agent corresponds to a hardware (HW) thread, and a DMV applicant corresponds to a software (SW) thread.
Each DMV agent is versatile enough to handle different tasks (like a general-purpose CPU core) and occasionally needs to query a centralized system to verify a person’s identity or a vehicle’s record (similar to fetching data from main memory into cache). While the social norm at the DMV is to make small talk, the agent would be more efficient if, while waiting for a slow response from the central system in Washington, DC, they temporarily switched to processing the next person in line. That, however, introduces complexity: correctly matching the returned documents to the original applicant (state and context management), potentially sending the second person back to the waiting area when the first person’s data finally arrives (preemption and rescheduling), and handling cases where the second person is a minor dependent on the first (dependency and ordering constraints). Suddenly, small talk feels a lot less stressful than building a correct scheduling and dependency-tracking system in real life.
Why CPU Cores Are So Complex
As you can see, having a single versatile agent perform many different tasks fully independently increases complexity and requires a complete toolkit at each station: printer, scanner, camera, imaging device, biometric reader, cash register, payment terminal, signature pad, and more. In much the same way, each CPU core integrates its own hardware structures to support execution, including arithmetic and logic units (ALUs), a control unit (CU), registers, a program counter, decoders, and other supporting components, and the picture becomes even more complex once superscalar pipelines, out-of-order execution, and branch prediction enter the scene.

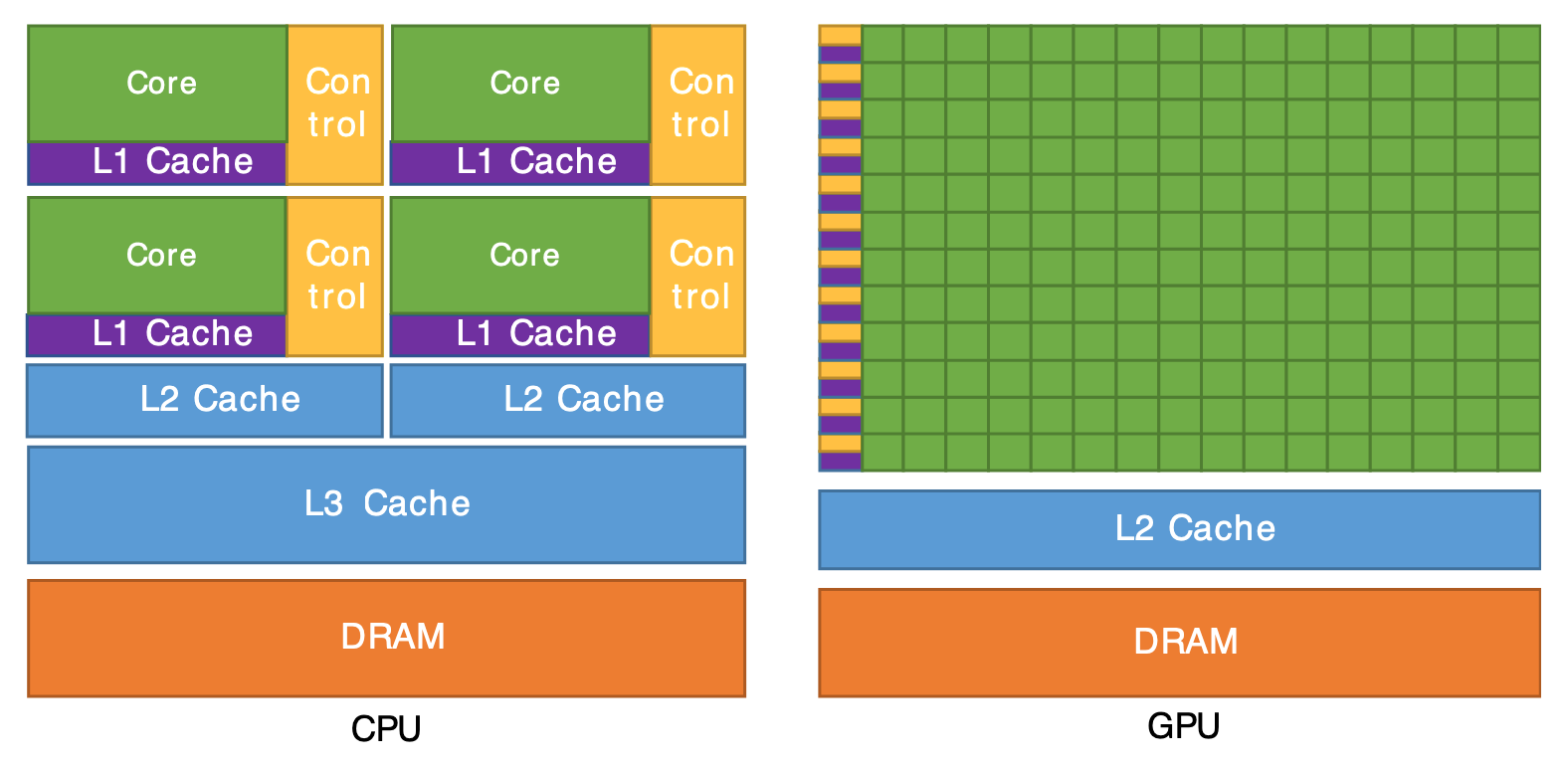
How GPU Threads Avoid This Complexity
The most common resolution used on desktop screens is 1920 × 1080, which works out to a little over 2 million pixels per frame. At even a modest 12 frames per second—the point where the human eye starts to reliably perceive motion rather than a slideshow—that already implies updating roughly 24 million pixels per second. Now imagine trying to do that purely on a general-purpose CPU: even with all 192 hardware threads on a high‑end part, you are asking it to iterate over that pixel stream on the order of 100,000+ times per second on hardware that was never optimized for this style of massively data-parallel, bandwidth-heavy work.
CPUs invest enormous silicon budget in superscalar issue, out-of-order execution, register renaming, and branch prediction to squeeze more instruction-level parallelism out of irregular control flow. Those mechanisms are fantastic for general-purpose code with lots of branches and data reuse, but they do almost nothing for a workload that simply needs to push billions of mostly independent pixels or activations through a fixed pipeline every second. In that regime, GPUs win by trading these complex control features for many more simple arithmetic units and much higher memory bandwidth.”

From 192 CPU Threads to 20K GPU Threads
Going back to the DMV analogy: a 192‑thread CPU is like having 192 very smart, overqualified DMV agents in one building. Each agent is great at juggling odd cases, reordering subtasks, and guessing which form you will need next, but there are still only 192 of them, and each one is running their own personal workflow.
A GPU, by contrast, is like building a giant hall with something like 20,000 junior agents. They are not nearly as clever individually, but they all work in lockstep rows, following the same instruction at the same time: ‘everyone check box A on your form now, everyone stamp field B now, everyone move your form to the next station now.’ Because there are so many of them doing the same simple steps on different forms, the total number of applications they can push through the system dwarfs what the 192 genius agents can do, even though each junior agent is much simpler.
Instead of burning transistors on out‑of‑order schedulers, big branch predictors, and per‑thread book‑keeping, a GPU spends most of its area on lots of very simple lanes and the hardware to march them forward together. You still have control logic, of course, but it is much more “everyone in this warp does this instruction now” than “let each thread speculate and reorder on its own.” That makes each thread pretty dumb compared to a CPU thread, but because you can afford to run tens or hundreds of thousands of them at once, you hide latency by always having another warp ready to go, rather than by building a tiny superscalar brain that tries to be clever about a handful of instructions.
What This Means for Machine Learning Engineers
For machine learning engineers, this boils down to choosing the right mental model for the hardware being targeted. CPU threads are few, powerful, and optimized for complex, branchy logic, so they shine on orchestration, preprocessing, and latency-sensitive control paths. GPU threads are tiny, numerous, and designed to run in lockstep on simple kernels, so they excel at the dense, regular math that dominates training and inference. Writing fast ML code means structuring workloads so that CPUs handle the “clever” coordination work and GPUs chew through the massive, uniform tensor operations—aligning your threading model, memory access patterns, and kernel design with the radically different way GPU threads extract parallelism.
References
- https://www.amd.com/content/dam/amd/en/documents/partner-hub/ryzen/ryzen-consumer-master-quick-reference-competitive.pdf
- Superscalar Architecture – Scaler Topicshttps://www.scaler.com/topics/superscalar-architecture/
- https://cvw.cac.cornell.edu/gpu-architecture/gpu-characteristics/design n



{kind=link}