



Table of Links
Abstract and 1. Introduction
-
Methodology
-
Experiments and Results
3.1 Language Modeling on vQuality Data
3.2 Exploration on Attention and Linear Recurrence
3.3 Efficient Length Extrapolation
3.4 Long-Context Understanding
-
Analysis
-
Conclusion, Acknowledgement, and References
A. Implementation Details
B. Additional Experiment Results
C. Details of Entropy Measurement
D. Limitations
A Implementation Details
For the GLA layer in the Sliding GLA architecture, we use the number of heads dm/384, a key expansion ratio of 0.5, and a value expansion ratio of 1. For the RetNet layer we use a number of head that is half of the number of attention query heads, key expansion ratio of 1 and value expansion ratio of 2. The GLA and RetNet implementations are from the Flash Linear Attention repository[3] [YZ24]. We use the FlashAttention-based implementation for Self-Extend extrapolation[4]. The Mamba 432M model has a model width of 1024 and the Mamba 1.3B model has a model width of 2048. All models trained on SlimPajama have the same training configurations and the MLP intermediate size as Samba, unless otherwise specified. The training infrastructure on SlimPajama is based on a modified version of the TinyLlama codebase[5].
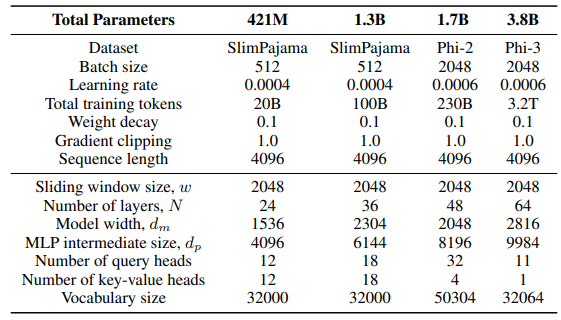

In the generation configurations for the downstream tasks, we use greedy decoding for GSM8K, and Nucleus Sampling [HBD+19] with a temperature of τ = 0.2 and top-p = 0.95 for HumanEval. For MBPP and SQuAD, we set τ = 0.01 and top-p = 0.95.
B Additional Experiment Results
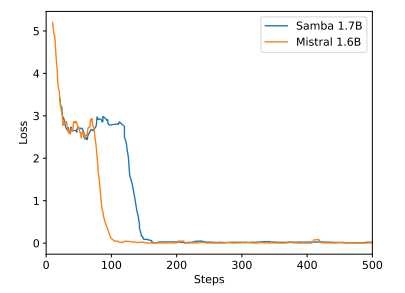



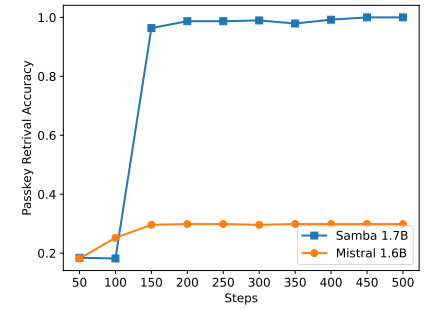

C Details of Entropy Measurement


D Limitations
Although Samba demonstrates promising memory retrieval performance through instruction tuning, its pre-trained base model has retrieval performance similar to that of the SWA-based model, as shown in Figure 7. This opens up future direction on further improving the Samba’s retrieval ability without compromising its efficiency and extrapolation ability. In addition, the hybridization strategy of Samba is not consistently better than other alternatives in all tasks. As shown in Table 2, MambaSWA-MLP shows improved performance on tasks such as WinoGrande, SIQA, and GSM8K. This gives us the potential to invest in a more sophisticated approach to perform input-dependent dynamic combinations of SWA-based and SSM-based models.
:::info
Authors:
(1) Liliang Ren, Microsoft and University of Illinois at Urbana-Champaign (liliangren@microsoft.com);
(2) Yang Liu†, Microsoft (yaliu10@microsoft.com);
(3) Yadong Lu†, Microsoft (yadonglu@microsoft.com);
(4) Yelong Shen, Microsoft (yelong.shen@microsoft.com);
(5) Chen Liang, Microsoft (chenliang1@microsoft.com);
(6) Weizhu Chen, Microsoft (wzchen@microsoft.com).
:::
:::info
This paper is available on arxiv under CC BY 4.0 license.
:::
[3] https://github.com/sustcsonglin/flash-linear-attention
[4] https://github.com/datamllab/LongLM/blob/master/selfextendpatch/Llama.py
[5] https://github.com/jzhang38/TinyLlama



{kind=link}