



I like my Obsidian vault a lot. But NotebookLM made me realize that I could probably squeeze a lot more value out of my notes. So, I hooked a local LLM to my Obsidian vault—and it was amazing. That experiment opened the floodgates, and I started thinking about what else I could do to really maximize what Obsidian offers. You see the rabbit hole I’m digging for myself here: just one more integration, I promise.
One long-standing pain point for me has been the friction of starting a daily note. Voice journaling worked as a quick fix, but the resulting text was always unformatted and difficult to scan. What if I could voice journal directly in Obsidian and end up with a clean, formatted note instead of a messy transcript? Thanks to local LLMs and the abundance of free AI libraries, this is now possible.
My voice notes turn into fully structured entries
Raw audio to formatted notes
Before I dive into the how and what, here’s what the plugin actually does. It adds a record button to the Obsidian sidebar. I click it, and a prompt opens to record a voice note. After hitting Start, I speak my mind. Once I’m finished, I hit Stop. At that point, the audio is processed: first for transcription, then for formatting and summarization. When all of that’s done, the plugin generates a new note in the Voice Notes folder of my vault.
Each voice note contains an embedded audio player with the original recording, a summary, action tasks, key points, and the full transcript. The action tasks sometimes feel a bit overconfident, but overall, I like the result. It’s a fantastic way to quickly capture journal entries when I’m feeling lazy.
I already had openai/gpt-oss-20b hooked into Obsidian through a plugin called Private AI. That plugin supports RAG, which is great, but it doesn’t go beyond being a chatbot—it can’t create or modify notes. What I wanted was more automation.
The overall flow is obvious now: I click the record button, speak, and finish. Then, Whisper transcribes the audio. The transcription gets passed to my local LLM, which generates a summary and action items, and then that output flows back into Obsidian as a formatted note. Simple in concept, but surprisingly effective. A year ago, this would’ve felt impossible, but now we’re spoiled with user-friendly tools for running your own models. Below, I’ve written the gist of what I did. This isn’t meant to be a step-by-step programming tutorial so I’ll spare you the boilerplate and focus on the core idea instead.
The engine under the hood
LM Studio does the heavy lifting
I use LM Studio. I might switch to AnythingLLM at some point, but I started with LM Studio and I’m not keen on re-downloading models right now. LM Studio makes things simple: it runs a server with an API that mimics OpenAI, so it’s compatible with a wide range of services.
By default, the API is exposed at 127.0.0.1:1234/v1/chat/completions. I’ve experimented with different models, and gpt-oss-20b does a decent job. To balance speed with quality, I keep the reasoning effort set to low. This is necessary since I’m running all of this on an AMD RX6700XT 12GB. You have to cut corners when your GPU isn’t top of the line.
Setting up LM Studio is dead simple. Install it, pick and download a model, load it, and run the local server.
The voice-to-text layer
Whisper makes sense of the sound

Of course, before the LLM can summarize anything, I need a transcript. That’s where Whisper comes in. Whisper is open-source, powerful, and surprisingly fast depending on the model size. I couldn’t get it to run on my GPU, since AMD’s support in WSL is weak, but I decided to run it inside WSL anyway. Setting up WSL is straightforward—it’s just a few commands, and nothing gets messy since we’re only exposing the service.
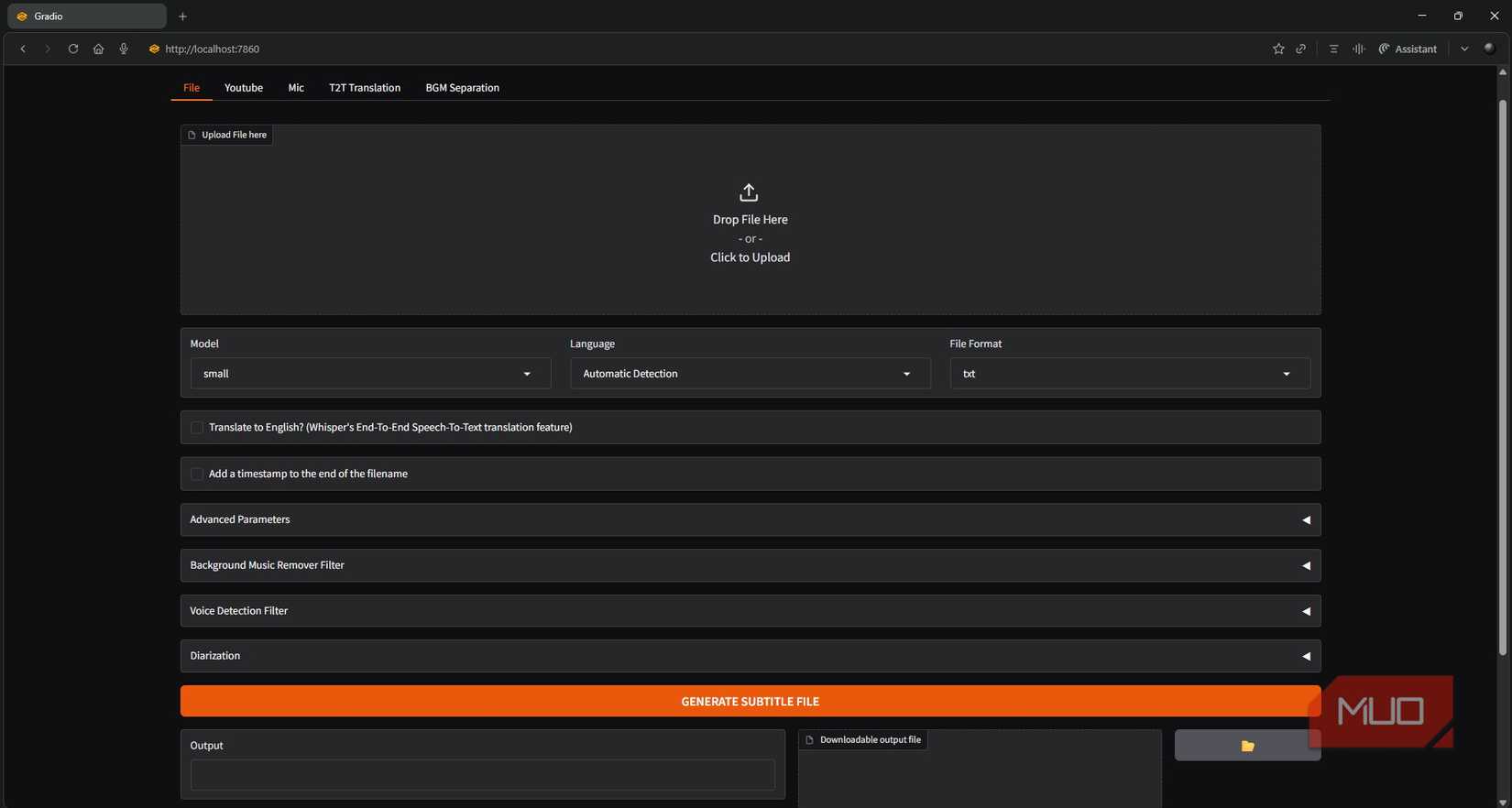
I initially used Whisper-WebUI since this was my first time trying it out and I wanted to see it in action. There were some hiccups with Python dependencies (as usual), but I eventually got it working. The WebUI is built on Gradio and lets you upload an audio file and get a transcript, which is a handy way to verify the setup. I used the small model, which works well enough, though larger models improve accuracy if you need it.

Eventually, the UI isn’t needed. If you’re confident, you can install the original Whisper repo directly. That said, the WebUI version also provides an API server if you wrap it in FastAPI, so either route works fine.
Obsidian ties it all together
Orchestrating the workflow
With Whisper transcribing and LM Studio summarizing, the final piece was making sure Obsidian could orchestrate the flow: sending audio to Whisper, feeding text to LM Studio, and creating the formatted note. Unsurprisingly, there’s no native way to do this. I didn’t even bother checking for community plugins—I knew I’d have to build my own.

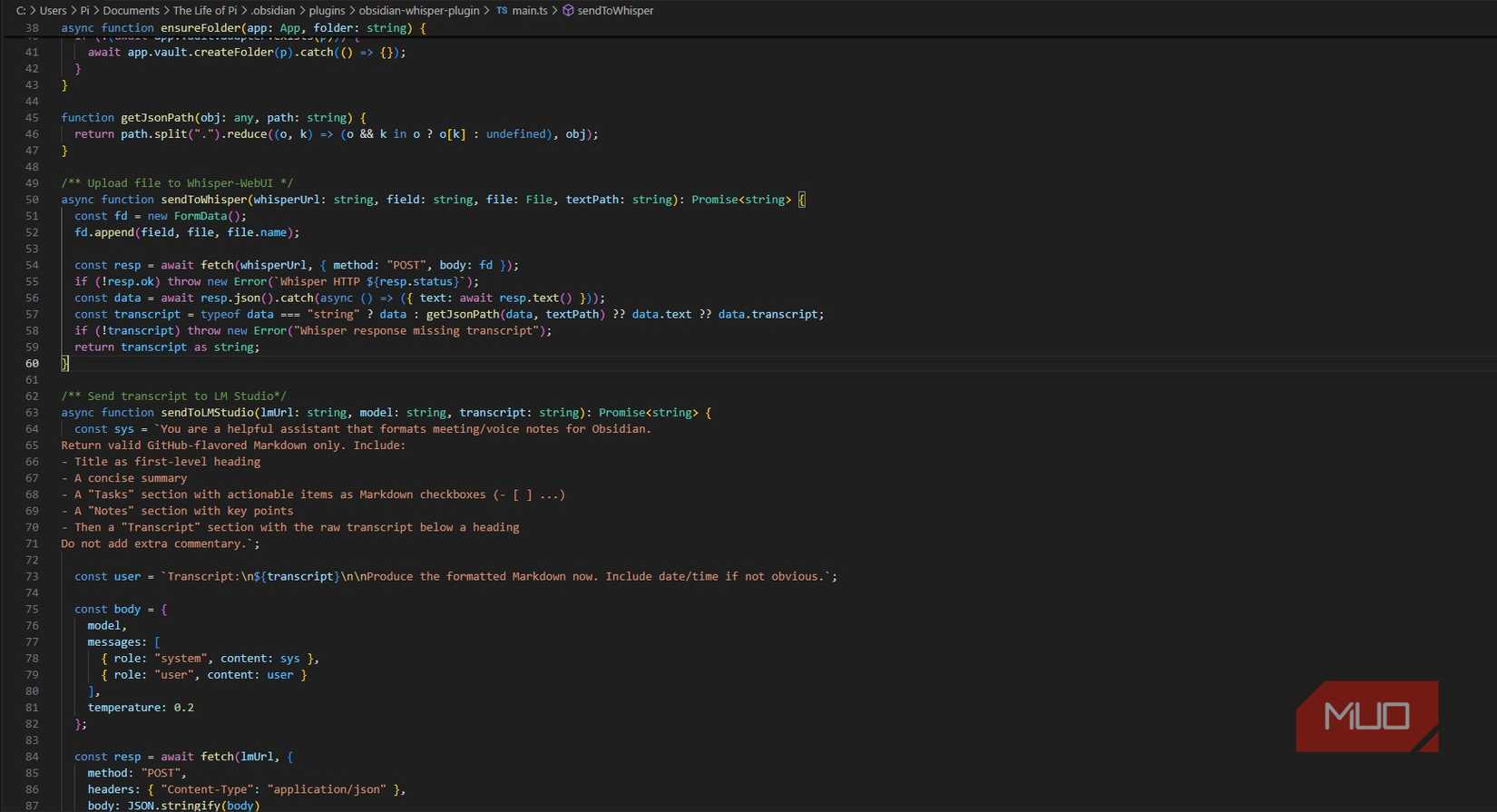
Thankfully, writing an Obsidian plugin is easy. Beyond the settings, there are two core functions: sendToWhisper takes the recorded audio and sends it to Whisper, waiting for the transcription. sendToLMStudio sends the transcription along with a prompt:
You are a helpful assistant that formats voice notes for Obsidian. Return valid GitHub-flavored Markdown only. Include:
– Title as first-level heading
– A concise summary
– A “Tasks” section with actionable items as Markdown checkboxes (- [ ] …)
– A “Notes” section with key points
– Then a “Transcript” section with the raw transcript below a heading
Do not add extra commentary.
The response is then caught, formatted into a new note, and saved. I speak, Obsidian processes, and I get a clean, structured note. It takes around ~40 seconds for it to transcribe a 4-minute voice note, which is fine, especially considering that I’m using my CPU only for the transcription. It’s not perfect, but it’s mine. The only drawback is that it all runs locally. I don’t have a homelab, so if I’m outside and using my phone, it won’t work. But … that’s a problem for future me.



{kind=link}