



Multi-bank FX reconciliation rarely fails for the reasons teams expect. Systems can be fully compliant with FIX, ISO 20022, internal controls, and vendor workflows — and still disagree on what a single trade represents.
The break does not originate in dashboards or storage engines. It emerges as trades move across lifecycle layers that were designed independently and optimized for different objectives.
This article examines how execution protocols, settlement models, reporting identifiers, and accounting systems fragment trade lineage — and why reconciliation becomes non-deterministic when identity is not treated as a system invariant.
1. This Does Not Break Because of Dashboards
In most treasury programs, reconciliation failures are blamed on tooling: incomplete API coverage, inconsistent CSV formats, or insufficient dashboard visibility. Those are surface explanations.
The break usually appears much earlier — at the point where independently designed systems attempt to agree on what a single trade is.
A FIX fill arrives at 14:03:21.347 with a ClOrdID generated by the client, an OrderID assigned by the venue, and an ExecID for the fill itself. The same trade later appears in an MT940 statement timestamped 14:03 — sometimes rounded to 14:00 — with no millisecond precision and no reference to the original execution identifiers. By the time it reaches an ERP, it may be attached to an internally generated document number with the external IDs stored in free-text reference fields.
Nothing is technically “wrong.” Each system is behaving correctly within its own domain. The failure emerges in the stitching.
The problem is not missing data. It is mismatched lifecycle semantics.
2. The FX Lifecycle Is Not a Straight Line
An FX trade does not travel cleanly from execution to accounting. It passes through layers that were designed by different institutions, at different times, for different objectives.
Execution
Identity here is composite. ClOrdID represents intent. OrderID represents venue acknowledgement. ExecID represents a specific fill. A smart order router may split one ClOrdID into multiple OrderIDs across venues. Partial fills create multiple ExecIDs. Cancel/replace flows preserve economic intent while mutating identifiers.
Reconciliation often fails in the mapping between those identifiers, not because an ID is missing, but because lineage becomes non-linear.
Market Infrastructure
Before a trade even reaches treasury, it may traverse matching utilities or settlement infrastructure. These intermediaries may:
- Re-key identifiers.
- Aggregate partial fills.
- Normalize economic fields.
- Introduce proprietary reference IDs.
The corporate system often receives a transformed projection, not the original execution narrative.
Confirmation
Confirmations may collapse multiple execution events into a single economic representation. Amendments can appear as full overwrites rather than deltas. Product terms in FpML may not map cleanly back to execution semantics.
Settlement
Settlement may be gross (1:1) or netted across trades. Netting is an operational efficiency, not a flaw — but it requires explicit mapping between trade-level economics and net cash realization. A single CLS pay-in can represent dozens of underlying trades.
Even in gross settlement, timestamp semantics shift. FIX may record milliseconds; MT940 often records minutes. Some ISO 20022 camt statements rely primarily on value date. That precision asymmetry forces tolerance windows in matching engines.
Accounting
ERPs generally assign internal document numbers as primary identity. External IDs — ClOrdID, OrderID, UTI — become reference attributes. In SAP environments, IDOCs may not consistently preserve all upstream identifiers unless custom fields are enforced.
Modern ERP systems can support bitemporal storage (valid time vs transaction time). That preserves internal causality. It does not automatically preserve cross-domain identity alignment.
Regulatory Reporting
Under EMIR or Dodd-Frank, reporting can be concurrent with execution. The UTI was designed to solve identity coherence across counterparties.
In practice, UTIs often fail as lifecycle-wide identifiers because:
- One counterparty generates it late.
- Responsibility waterfalls create ambiguity.
- Interim reports are filed before synchronization.
- Intermediary banks fail to propagate it consistently.
The reporting layer sometimes adds another identity discontinuity instead of resolving one.
The lifecycle is not linear. It is mediated, transformed, and partially re-expressed at each boundary.
3. Record-Centric Modeling and Where It Breaks
The storage engine is not the core issue. Relational databases, temporal tables, and change-data-capture mechanisms can preserve history. Event sourcing, when used, almost always relies on snapshotting for performance.
The break happens at the domain abstraction level.
Many treasury systems model a trade primarily as a current-state record:
- Latest quantity
- Latest rate
- Current status
- Current settlement flag
Amendments update economic fields in place. Partial fills accumulate into totals. Settlement updates status columns. Historical states may exist in audit tables, but reconciliation logic operates on the present projection.
Consider a common case:
- A USD/EUR spot order is partially filled in three executions.
- One fill is corrected.
- The final economic confirmation differs slightly due to embedded fees.
- Settlement is netted with other trades in CLS.
- The ERP posts two journal lines with internal document IDs.
Every system has internally consistent state.
Reconciliation now depends on inference:
- Matching net cash movement back to multiple execution IDs.
- Applying ±5 minute timestamp tolerances due to MT940 granularity.
- Interpreting whether a corrected fill replaced or supplemented a prior execution.
This is not a database failure. It is a modeling compression problem.
If lifecycle transitions are not treated as first-class domain entities — regardless of whether they are stored in SQL tables or append-only logs — causality becomes secondary. Identity stitching becomes rule-driven rather than structural.
The distinction is not CRUD versus event sourcing. It is whether lifecycle semantics are explicit or inferred.
One might assume that industry standards such as ISO 20022 or FpML resolve this identity crisis. They do not.
4. Standards Solve Syntax, Not Lifecycle Semantics
Industry standards materially improve interoperability. But they operate within domain boundaries.
FIX standardizes execution messaging. FpML standardizes contract representation. ISO 20022 structures payment and reporting messages. LEIs identify legal entities. UTIs attempt transaction-level identity coherence.
None of these standards enforce lifecycle-wide semantic alignment.
A FIX execution report does not guarantee that the downstream confirmation preserves execution lineage. An FpML confirmation does not guarantee that the ERP uses its identifiers as primary keys. An ISO 20022 camt statement does not guarantee millisecond alignment with execution timestamps.
Standards constrain message structure. They do not guarantee cross-system identity continuity.
Two counterparties can both be fully compliant and still fail to reconcile deterministically. One may collapse amendments into overwrite confirmations. Another may report before UTI synchronization. A clearing workflow may net settlement before allocating trade-level references. Each step is locally rational. Collectively, they fracture lifecycle continuity.
The issue is not regulatory non-compliance. It is that each layer optimizes for its own constraints, while reconciliation requires continuity across them.
5. Canonical Normalization Is a Domain Modeling Decision
The failure mode described so far does not disappear with better dashboards or faster APIs.
It requires a normalization layer that treats lifecycle transitions as first-class objects rather than as incidental by-products of storage or logging mechanisms. Instead of relying on logs or audit trails as indirect evidence of change, the model must represent lifecycle transitions explicitly as domain events.
That layer must do three things consistently:
- Preserve identity lineage.
- Preserve temporal precision.
- Preserve economic decomposition.
Consider what happens without it. Three ExecIDs are compressed into a single confirmation record. That confirmation is absorbed into a net settlement position. The net settlement produces two ERP postings, each identified only by internal document numbers. By the time the cash movement appears in reporting, the original execution lineage is no longer structurally visible.
At that point, stitching logic turns procedural: status flags are checked, tolerance bands are applied, timestamps are compared within windows. Matching succeeds not because identities are structurally aligned, but because the rules happen to converge.
This is rule accumulation rather than semantic alignment.
A canonical model does not eliminate transformation. It makes transformation explicit.
It defines:
- What constitutes a lifecycle event.
- How identifiers are related.
- How net settlement maps back to trade-level economics.
- How corrections are represented (replace vs delta).
- How reporting identifiers attach to economic lineage.
Whether stored in relational tables, log stores, or hybrid systems is secondary.
The modeling decision is primary.
This model does not prescribe a specific storage technology. A canonical lifecycle layer can be implemented using relational schemas, append-only logs, graph models, or hybrid persistence patterns. The architectural requirement is explicit identity and event lineage, not a particular database choice.
That said, building such a canonical mapping graph is not a cosmetic refactor. In most institutions, the relevant lifecycle logic is embedded across vendor platforms, routing engines, settlement adapters, ERP customizations, and reconciliation rule engines. Identifier stitching, tolerance logic, and exception handling are often hard-coded in proprietary systems accumulated over years of incremental fixes.
Extracting that logic into an explicit, canonical layer requires:
- Reverse-engineering implicit assumptions embedded in legacy matching rules.
- Surfacing undocumented field transformations inside vendor adapters.
- Reconciling conflicting interpretations of amendments (replace vs delta).
- Re-establishing identifier lineage that was historically treated as secondary metadata.
It also requires cross-organizational alignment. Execution venues, clearing infrastructure, custodians, and ERP vendors rarely share a unified semantic contract. Governance and coordination are as challenging as the engineering itself.
This is why the problem persists. The barrier is not conceptual clarity; it is the engineering and coordination effort required to externalize and formalize logic that currently lives inside opaque, distributed implementations.
A minimal structural representation of such a layer would look like this:
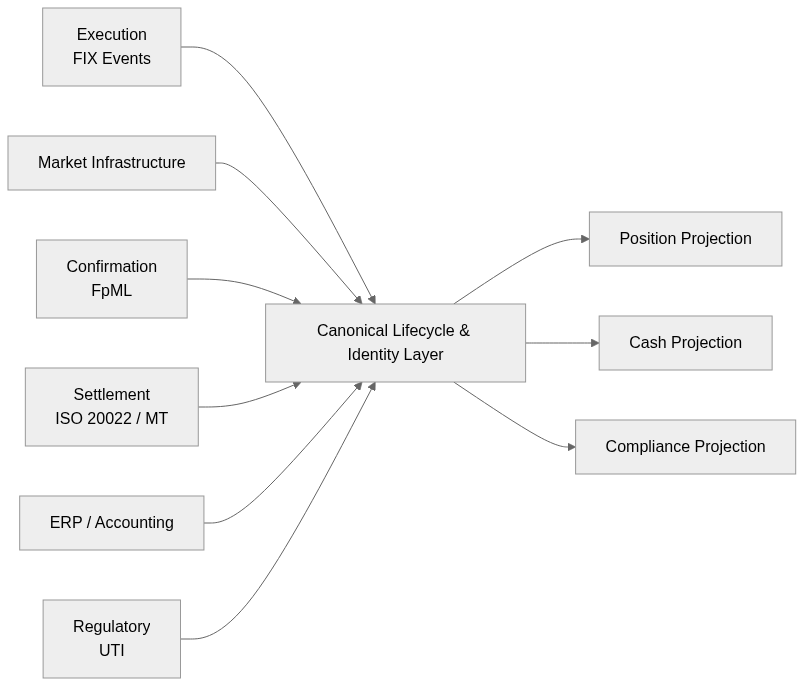

The key point is not centralization of data. It is centralization of lifecycle identity and event semantics before any downstream projection is produced.
6. Deterministic vs Heuristic Reconciliation
Most production reconciliation engines contain layers of tolerance logic:
- ±X basis points price tolerance.
- ±N minutes timestamp window.
- Net amount fuzzy matching.
- Manual override flags.
Those are not signs of incompetence.
They are symptoms of compressed lifecycle modeling.
When identity continuity is structural, reconciliation reduces to graph consistency:
- Does every settlement leg map to known execution lineage?
- Does every amendment reference a prior economic state?
- Does every UTI correspond to a reconciled internal identity node?
When identity continuity is inferred, reconciliation becomes statistical.
The difference is subtle but decisive.
Heuristic reconciliation tends to scale operational effort — more rules, more tolerances, more exception queues. Deterministic reconciliation, when achievable, scales structural integrity: fewer inference layers, fewer ambiguous states, fewer manual interventions.
7. Conclusion: Reconciliation Is a Modeling Problem
Multi-bank FX data does not fail to reconcile because standards are missing. It does not fail because APIs are slow. It does not fail because dashboards are insufficient.
It fails because lifecycle identity is not preserved as a structural primitive across systems that were never designed to share one.
Each layer in the trade lifecycle optimizes for its own objective:
- Execution optimizes for latency.
- Infrastructure optimizes for throughput and risk containment.
- Confirmation optimizes for contractual completeness.
- Settlement optimizes for liquidity efficiency.
- Accounting optimizes for financial control.
- Reporting optimizes for regulatory compliance.
None of these objectives are wrong. They are simply orthogonal.
Reconciliation breaks when identity is treated as a local concern rather than a cross-domain invariant.
The practical implication is not that firms need new messaging standards. Nor that they must replace relational databases with event stores.
It is that lifecycle transitions and identifier lineage must be made explicit — once — before any projection, netting, enrichment, or reporting logic is applied.
Where that discipline exists, reconciliation becomes deterministic.
Where it does not, tolerance bands, exception queues, and manual overrides become permanent architecture.
The difference is not technological sophistication. It is whether identity is treated as incidental metadata or as a system invariant.
The argument here is not that reconciliation challenges are new. It is that identity discontinuity across independently optimized lifecycle layers is structural rather than accidental — and therefore requires structural remedies.



{kind=link}