


Authors:
(1) Albert Gu, Machine Learning Department, Carnegie Mellon University and with equal contribution;
(2) Tri Dao, Department of Computer Science, Princeton University and with equal contribution.
Table of Links
Abstract and 1 Introduction
2 State Space Models
3 Selective State Space Models and 3.1 Motivation: Selection as a Means of Compression
3.2 Improving SSMs with Selection
3.3 Efficient Implementation of Selective SSMs
3.4 A Simplified SSM Architecture
3.5 Properties of Selection Mechanisms
3.6 Additional Model Details
4 Empirical Evaluation and 4.1 Synthetic Tasks
4.2 Language Modeling
4.3 DNA Modeling
4.4 Audio Modeling and Generation
4.5 Speed and Memory Benchmarks
4.6 Model Ablations
5 Discussion
6 Conclusion and References
A Discussion: Selection Mechanism
B Related Work
C Mechanics of Selective SSMs
D Hardware-aware Algorithm For Selective SSMs
E Experimental Details and Additional Results
4.2 Language Modeling
We evaluate the Mamba architecture on standard autoregressive language modeling against other architectures, on both pretraining metrics (perplexity) and zero-shot evaluations. We set the model sizes (depth and width) to mirror GPT3 specifications. We use the Pile dataset (L. Gao, Biderman, et al. 2020), and follow the training recipe described in Brown et al. (2020). All training details are in Appendix E.2.
4.2.1 Scaling Laws
For baselines, we compare against the standard Transformer architecture (GPT3 architecture), as well as the strongest Transformer recipe we know of (here referred to as Transformer++), based on the PaLM and LLaMa

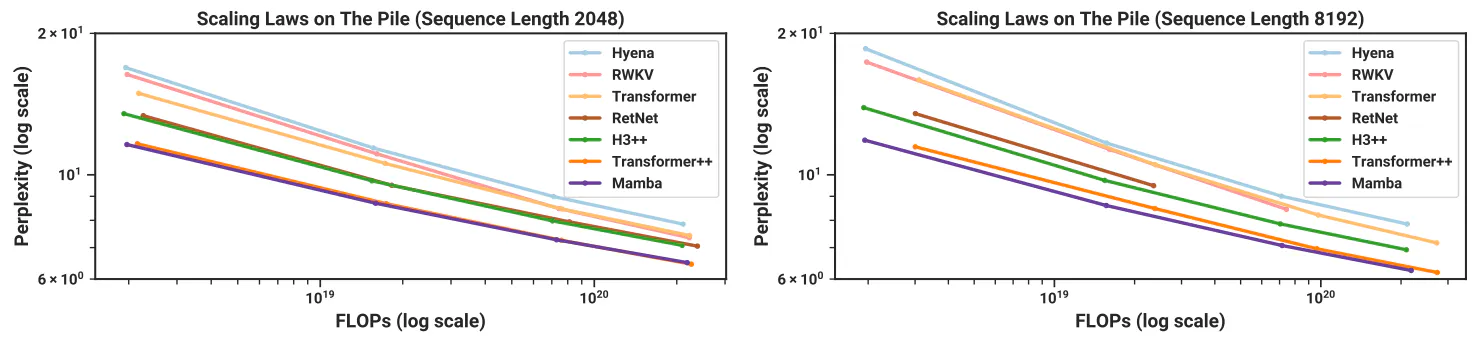


architectures (e.g. rotary embedding, SwiGLU MLP, RMSNorm instead of LayerNorm, no linear bias, and higher learning rates). We also compare against other recent subquadratic architectures (Figure 4). All model details are in Appendix E.2.
Figure 4 shows scaling laws under the standard Chinchilla (Hoffmann et al. 2022) protocol, on models from ≈ 125푀M to ≈ 1.3B parameters. Mamba is the first attention-free model to match the performance of a very strong Transformer recipe (Transformer++) that has now become standard, particularly as the sequence length grows. We note that full results on context length 8k are missing for the RWKV and RetNet baselines, prior strong recurrent models that can also be interpreted as SSMs, due to a lack of efficient implementation leading to out-of-memory or unrealistic computation requirements.
4.2.2 Downstream Evaluations
Table 3 shows the performance of Mamba on a range of popular downstream zero-shot evaluation tasks. We compare against the most well-known open source models at these sizes, most importantly Pythia (Biderman et al. 2023) and RWKV (B. Peng et al. 2023) which were trained with the same tokenizer, dataset, and training length (300B tokens) as our models. (Note that Mamba and Pythia are trained with context length 2048, while RWKV was trained with context length 1024.)

/cdn.vox-cdn.com/uploads/chorus_asset/file/25793290/Z2B0aZbqstJ98kwx_dualM2adapter.jpg)
{kind=link}