


Table of links
ABSTRACT
1 INTRODUCTION
2 BACKGROUND: OMNIDIRECTIONAL 3D OBJECT DETECTION
3 PRELIMINARY EXPERIMENT
3.1 Experiment Setup
3.2 Observations
3.3 Summary and Challenges
4 OVERVIEW OF PANOPTICUS
5 MULTI-BRANCH OMNIDIRECTIONAL 3D OBJECT DETECTION
5.1 Model Design
6 SPATIAL-ADAPTIVE EXECUTION
6.1 Performance Prediction
5.2 Model Adaptation
6.2 Execution Scheduling
7 IMPLEMENTATION
8 EVALUATION
8.1 Testbed and Dataset
8.2 Experiment Setup
8.3 Performance
8.4 Robustness
8.5 Component Analysis
8.6 Overhead
9 RELATED WORK
10 DISCUSSION AND FUTURE WORK
11 CONCLUSION AND REFERENCES
3 PRELIMINARY EXPERIMENT
We present in-depth observations on methods to improve the accuracy of the baseline BEVDet model mentioned in Section 2. Based on the results, we derived key insights and challenges in the design of Panopticus.
3.1 Experiment Setup
Based on the baseline BEVDet model, we established 16 variants with different detection capabilities by combining the design parameters in Table 1. Each variant utilizes one of four combinations of ResNet backbones and input resolutions listed in Table 1, such as ResNet34 backbone with a resolution of 256×448, which we refer to as BEVDet-R34. Also, each variant incorporates one of two DepthNets, differing in depth prediction capabilities. Last, a group of variants utilizes a temporal fusion technique, further enhancing BEV feature




generation. To compare with the state-of-the-art LiDARbased method, we profiled the CenterPoint [54] model. For model training, we utilized the nuScenes dataset [2] with ground-truth annotated 850 scenes, each of which contains a 20-second duration of video frames. Every frame provides 360° horizontal FOV through six camera images, each with a resolution of 900×1,600. For evaluation metrics, we used average precision (AP), widely employed to assess detection accuracy, and true positive (TP) errors. TP errors include average translation error (ATE) in meters and average velocity error (AVE) in meters per second, which represent the prediction errors of 3D location and speed for correctly detected objects, respectively. All metrics are calculated for each object type, such as cars and bicycles, and averaged across all types to report the model’s final detection performance, i.e., mAP, mATE, and mAVE. Inference latency was profiled on a recent edge device, Jetson AGX Orin [8] with a CUDA [6] GPU.
3.2 Observations
Accuracy-latency trade-offs in different models. Both detection accuracy and latency are crucial factors in building a 3D detection system. As shown in Figure 3, the profiled 3D detection models exhibit various accuracy-latency tradeoffs. Increasing both backbone capacity and input resolution clearly enhances mAP, but leads to high latency. For example, BEVDet-R152, which has the largest backbone capacity and resolution, achieves a 1.6× mAP improvement compared to BEVDet-R34. However, the inference latency is substantially increased by +717ms. Incorporating a dense DepthNet and temporal feature fusion into BEVDet-R152 further improves mAP by 12.1% and 16.1%, respectively, outperforming LiDARbased CenterPoint. However, employing all of these methods to enhance camera-based detection can result in considerable inference latency on resource-constrained edge devices.



Detection performance over various object properties. Real-world outdoor scenes encounter objects with diverse characteristics such as moving speed. We categorized objects based on the property and its levels defined in Table 2. For brevity, we focused on the distance between objects and the camera, as well as object velocity. As shown in the first row of Figure 4, all models achieve high mAP for objects with a D0 distance level. However, as the object distance level increases, lightweight models show significantly lower mAP. For example, the mAP of BEVDet-R34 for D3 objects is 2.7× lower than that of BEVDet-R152. The increase in errors of location and velocity predictions for distant and fast-moving objects, as shown in the second row of Figure 4, is mitigated in heavier models. Specifically, leveraging both temporal fusion and dense DepthNet reduces velocity prediction error for V3 objects by 2.4× compared to BEVDet-R50. Reducing the prediction errors of object properties is important for safety-critical applications. For instance, autonomous robots plan a navigation path based on the understanding of surrounding objects’ positions and movements. In summary, the detection capabilities of models vary across diverse object properties, requiring the use of appropriate models with an awareness of objects’ characteristics
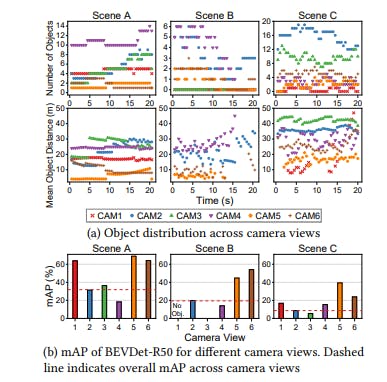
Detection performance over diverse spatial distributions. We examined how detection performance varies depending on spatial characteristics. Figure 5 shows the spatial object distribution and mAP in three example scenes from the nuScenes dataset. For each camera view (e.g., CAM1), we



Figure 5: Distribution and mAP in example scenes.
analyzed the spatial distribution by calculating both the number of objects and their average distance from the camera. Figure 5a shows that the overall scene complexity increases from Scene A to C, considering distribution in all camera views. Therefore, as shown in Figure 5b, the overall mAP gradually decreases. Note that the relative difference in distribution and mAP is even more significant across camera views. In Scene A, CAM4, which captures many distant objects, has the lowest mAP, whereas camera views with a smaller number of closer objects, such as CAM5, have a higher mAP. Meanwhile, in Scene C, the mAP between CAM3 and CAM5 differs by as much as 7.1×, indicating significant differences in spatial complexities. Consequently, diversity in spatial distribution across scenes and camera views necessitates model selection for each view to achieve the best performance.
3.3 Summary and Challenges
Based on the observations, we derived insights to enhance both the accuracy and efficiency of omnidirectional 3D detection. Prior BEV-based models have made advancements in camera-based detection accuracy, but may result in substantial computational demands for a resource-constrained device. We observed that the models’ detection capabilities differ by object properties such as distance and velocity. Moreover, the variance in spatial distribution across scenes, even among different camera views within the same scene, suggests a need for employing diverse models to enhance overall



performance. The experimental results inspired us to explore a high-accuracy omnidirectional perception scheme tailored for limited edge resources. This scheme would utilize the appropriate models for multi-view images, considering the models’ capabilities and the spatial distribution variations across camera views
However, realizing this scheme poses several challenges. First, previous BEV-based models lack dynamic inference capabilities to process each camera view with varying inference configurations, such as the choice of backbone or DepthNet types. An approach to load all possible models into memory and assign them across views [28] may incur significant memory and latency overheads due to the redundant components among models. Moreover, the architecture of the BEV-based model needs to be adjustable considering various constraints such as device capabilities and latency requirements. Second, to maximize detection accuracy while meeting the latency requirements, the optimal inference configurations for all camera views must be established at each video frame. This requires real-time analysis of (1) changes in the surrounding spatial distribution within a dynamic environment and (2) the expected performance of different inference configurations.
This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.


{kind=link}