


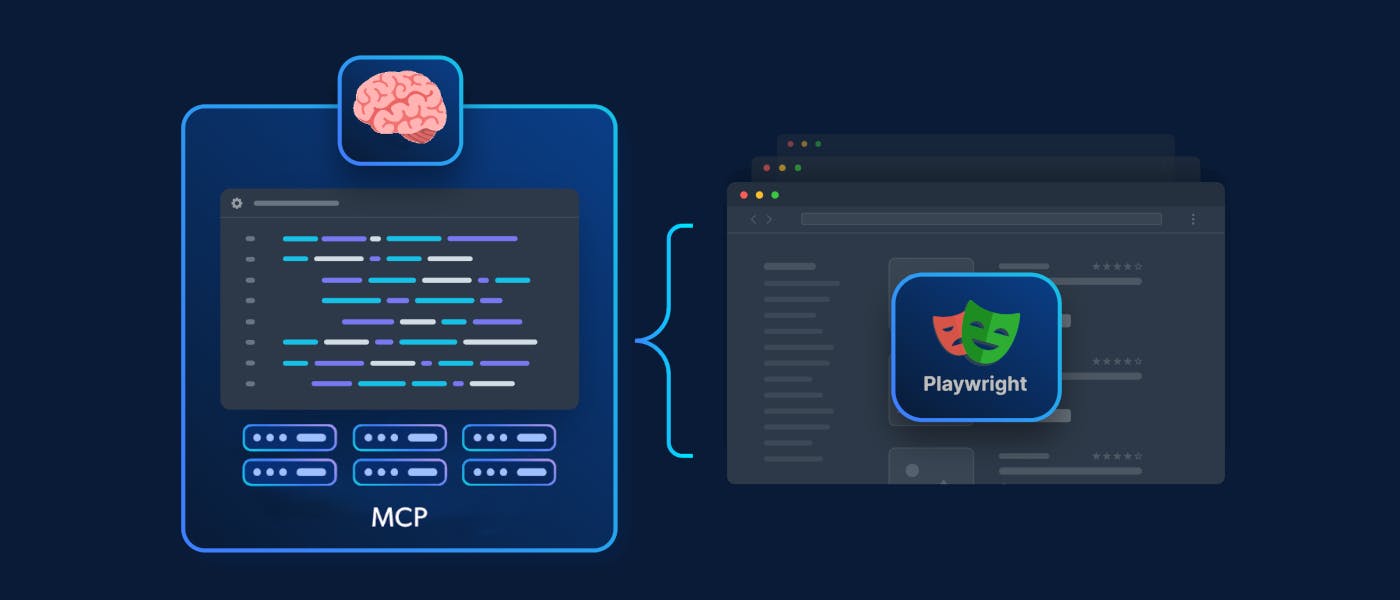
In April 2025, Microsoft quietly dropped Playwright MCP, a new server that connects your AI agent (via MCP) directly to the Playwright browser API.
What does that mean in plain English? Your AI agent can now interact with real web pages using nothing but simple text instructions (and for free!) “Click this,” “Take a screenshot“—all without writing a single line of browser automation code.
Yeah, that’s so big that Playwright MCP has already become one of the most-starred MCP servers on GitHub. And it’s only just getting started. 🔥
In this step-by-step guide, you’ll see exactly what this server can do, and how to plug it into a Python-based AI workflow using the OpenAI Agents SDK.
Why Everyone’s Talking About the Playwright MCP Server
Playwright MCP is an MCP (Model Context Protocol) server that gives your AI agents serious browser automation superpowers via the Playwright API.
Behind the scenes, instead of relying on screenshots or vision-tuned models, it lets LLMs interact with web pages using structured accessibility snapshots. That means faster, cleaner, and far more LLM-friendly interactions.
In the world of agentic AI and agentic RAG workflows—where AI needs to read, click, and navigate like a human—this is a total game-changer! 🤯
And get this: even though Microsoft didn’t roll it out with much fanfare (no flashy keynote, no blog post blitz), this low-key library is already sitting at 12K+ ⭐ on GitHub… and climbing.




So why the hype? Because it just works, and below’s what makes it special:
- ⚡ Blazing fast and lightweight: Uses the browser’s accessibility tree, not slow, clunky pixel-based input.
- 🧠 LLM-first design: No need for vision model. It’s built for structured text interfaces.
- 🛠️ Deterministic tool usage: No guesswork, no ambiguity—just clear, reliable actions via several tools.
Plus, it comes with a solid CLI and useful customization flags for fine-tuned browser control.
This technology lets you build serious agents that don’t just hallucinate, but actually do stuff on the web. 💪 🌐
How to Use the Playwright MCP Server: Step-by-Step Tutorial
Ready to put the Playwright MCP server into action? Follow the steps below to wire it up in your Python script using the OpenAI Agents SDK!
Prerequisites
To follow along with this tutorial, make sure you’ve got your dev setup ready to roll:
- Python 3.10+ installed locally 🐍
- Node.js installed and working (the latest LTS version is your friend) ⚙️
- An API key from a supported LLM provider (OpenAI Agents SDK needs it, and we recommend Gemini because it’s free to use) 🔑
Step #1: Project Setup & Configuration
This Playwright + MCP integration builds on what we covered in MCP + OpenAI Agents SDK: How to Build a Powerful AI Agent. So if you haven’t checked that out yet, go skim it real quick. We’ll wait. 🕒



But if you’re in a rush (we get it), here’s the TL;DR version to get you rolling:
- Create a project folder.
- Inside it, add a file named
agent.pyand set up a Python virtual environment. - Install the required libraries with
pip install openai-agents python-dotenv. - Add a
.envfile to your project folder and, inside it, drop your Gemini API key like this:
GEMINI_API_KEY=<your-gemini-api-key>
That’s it! You’re now locked, loaded, and ready to start building! 💥
Step #2: Playwright MCP Server Integration
Get the Playwright MCP server up and running inside OpenAI Agents SDK with the following code:
async with MCPServerStdio(
name="Playwright MCP server",
params={
"command": "npx",
"args": ["-y", "@playwright/mcp@latest", "--output-dir", "./"],
},
) as server:
# Create and initialize the AI agent with the running MCP server
agent = await create_mcp_ai_agent(server)
# Agent request-response cycle...
```python
This chunk of code basically runs the following shell command under the hood:
```bash
npx -y @playwright/mcp@latest --output-dir "./"
In plain English? It spins up the Playwright MCP server using Node.js. The --output-dir "./" bit tells it where to dump export files like screenshots and PDFs.
ℹ️ Note: If your agent doesn’t need to export any files, you can skip the --output-dir flag entirely. That’s optional!
Step #3: Complete Code
Here’s what your agent.py file should look like once everything’s wired up and humming. This is your full Open AI Agents SDK-built, Gemini-powered, Playwright-integrated AI agent ready to take action through MCP:
import asyncio
from dotenv import load_dotenv
import os
from agents import (
Runner,
Agent,
OpenAIChatCompletionsModel,
set_default_openai_client,
set_tracing_disabled
)
from openai import AsyncOpenAI
from agents.mcp import MCPServerStdio
# Load environment variables from the .env file
load_dotenv()
# Read the required secrets envs from environment variables
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
async def create_mcp_ai_agent(mcp_server):
# Initialize Gemini client using its OpenAI-compatible interface
gemini_client = AsyncOpenAI(
api_key=GEMINI_API_KEY,
base_url="https://generativelanguage.googleapis.com/v1beta/openai/"
)
# Set the default OpenAI client to Gemini
set_default_openai_client(gemini_client)
# Disable tracing to avoid tracing errors being logged in the terminal
set_tracing_disabled(True)
# Create an agent configured to use the MCP server and Gemini model
agent = Agent(
name="Assistant",
instructions="You are a helpful assistant",
model=OpenAIChatCompletionsModel(
model="gemini-2.0-flash",
openai_client=gemini_client,
),
mcp_servers=[mcp_server]
)
return agent
async def run():
# Start the Playwright MCP server via npx
async with MCPServerStdio(
name="Playwright MCP server",
params={
"command": "npx",
"args": ["-y", "@playwright/mcp@latest", "--output-dir", "./"],
},
) as server:
# Create and initialize the AI agent with the running MCP server
agent = await create_mcp_ai_agent(server)
# Main REPL loop to process user requests
while True:
# Read the user's request
request = input("Your request -> ")
# Exit condition
if request.lower() == "exit":
print("Exiting the agent...")
break
# Run the request through the agent
output = await Runner.run(agent, input=request)
# Print the result to the user
print(f"Output -> n{output.final_output}nn")
if __name__ == "__main__":
asyncio.run(run())
🚨 Boom. Just like that, you’ve built a fully functional AI agent in ~75 lines of Python. It can think through Gemini and act through Playwright. 🧠 🛠️
Step #4: Test Your Playwright-Powered AI Agent
It’s time to test your agent by running:
python agent.py
👀 That’s what you’ll see on startup:



Now hit it with a prompt like this:
Visit hackernoon.com, click on "Trending Stories", wait for the page to fully load, and then export it as a PDF file named "hackernoon-trending-stories.pdf"
🎯 The result?



Yup, it nailed it! 🎉
But that was fast, so let’s break down what happened:
- The agent launches a Playwright-powered Chrome instance. 🧭
- It visits hackernoon.com. 🌐
- Clicks on the “Trending Stories” link. 🖱️
- Waits for the page to fully load. ⏳
- Exports the page to a PDF file named
hackernoon-trending-stories.pdf, which appeared in the project folder. 📄
Note that the browser stays open in the background on the final page. That’s perfect if you want to send another prompt and keep the current session alive!



Don’t like that and want to end the session and close the browser? Just type something like:
Now, close the browser.
The agent will shut down the browser for you. ✅
Now, go check the generated PDF file hackernoon-trending-stories.pdf in your project folder. Scroll through it, and you’ll see:



Fantastic! A clean, full-page export of Hackernoon’s trending page, links and all, in crisp PDF format. That’s real browser automation, powered by your own AI agent.
And that, folks, is how you build an AI agent with Playwright + MCP. This thing is seriously powerful. Let it cook. 👨🍳
The Hidden Limitations of Playwright MCP (And How to Outsmart Them)
Cool! You might be thinking:
“Alright, I’ve got the tools… an LLM that can think, an MCP server that can scrape, and Playwright to control the browser. Game over, right? Time to automate the entire internet!”
Well… not so fast. 🛑
Sure, there are only two core things AI agents need to thrive:
- Access to real-time web data (✅ handled by scraping-capable MCP integrations)
- The ability to interact with a browser (✅ enter Playwright MCP)
But here’s where things get interesting…



Try asking your Playwright-powered AI agent something like:
Visit g2.com, wait for the page to load, and take a screenshot
And what happens? This! 👇



It navigates to G2. ✅ Waits. ✅ Takes a screenshot. ✅ But there’s a catch: the page is blocked behind a verification wall. 😬



And the agent is even polite enough to tell you:
Your request -> Visit g2.com, wait for the page to load, and take a screenshot
Output ->
Okay, I navigated to g2.com, waited for 5 seconds, took a snapshot of the page, and then took a screenshot. However, the page is showing a verification requirement. I am unable to complete the request.
Nope, it’s not “game over” for us as human beings. But maybe… it’s game over for the default Playwright browser setup. 😵 💻
🧩 So what went wrong? Here’s the issue: Vanilla Chrome! 🙅♂️
The browser Playwright controls out of the box isn’t designed to avoid blocks. It leaks signals all over the place, such as automation flags, weird configs, and so on…. To the point that most websites—jsut like G2 —instantly know it’s a bot. 🤖 🚫
So what’s the solution? 👉 A Playwright-compatible infrastructure built to support agentic workflows on remote browsers that don’t get blocked. We’re talking:
- Infinitely scalable ⚙️
- Works headless or headful 👁️
- Powered by a proxy network with 100M+ residential IPs 🌍
- Designed to blend in like a real user 🕵️♂️
Wondering what this magical tool is? Say hello to Bright Data’s Agent Browser—your stealthy, scalable, AI-friendly browser stack:
If you’re wondering how to plug it into your Playwright MCP setup, it’s as simple as passing a CDP endpoint:
async with MCPServerStdio(
name="Playwright MCP server",
params={
"command": "npx",
"args": [
"-y", "@playwright/mcp@latest",
# other arguments...
"--cdp-endpoint", "<YOUR_BRIGHT_DATA_AGENT_BROWSER_CDP_URL>"
],
},
) as server:
# Your agent logic here...
And just like that, no more blocks! No more bot walls. No more sad Gru memes.
Ready to build agentic workflows that actually work on the live web? Bright Data’s Agent Browser has your back!
See it in action in another integration here:
Final Thoughts
Now you know how to supercharge any AI agent built with the OpenAI Agents SDK—whether it’s running on GPT, Gemini, or whatever’s coming next—by plugging it into the Playwright MCP server for real browser control.
We also showed how to level up even further by overcoming browser blocks using Bright Data’s Agent Browser, just one piece of the powerful AI infrastructure we’ve built to support real-world AI workflows at scale.
At Bright Data, our mission is simple: make AI accessible for everyone, everywhere. So until next time—stay curious, stay bold, and keep building the future of AI. ✨



{kind=link}