


Authors:
(1) Raphaël Millière, Department of Philosophy, Macquarie University ([email protected]);
(2) Cameron Buckner, Department of Philosophy, University of Houston ([email protected]).
Table of Links
Abstract and 1 Introduction
2. A primer on LLMs
2.1. Historical foundations
2.2. Transformer-based LLMs
3. Interface with classic philosophical issues
3.1. Compositionality
3.2. Nativism and language acquisition
3.3. Language understanding and grounding
3.4. World models
3.5. Transmission of cultural knowledge and linguistic scaffolding
4. Conclusion, Glossary, and References
3.1. Compositionality
According to a long-standing critique of the connectionist research program, artificial neural networks would be fundamentally incapable of accounting for the core structure-sensitive features of cognition, such as the productivity and systematicity of language and thought. This critique centers on a dilemma: either ANNs fail to capture the features of cognition that can be readily accounted for in a classical symbolic architecture; or they merely implement such an architecture, in which case they lack independent explanatory purchase as models of cognition (Fodor & Pylyshyn 1988, Pinker & Prince 1988, Quilty-Dunn et al. 2022). The first horn of the dilemma rests on the hypothesis that ANNs lack the kind of constituent structure required to model productive and systematic thought – specifically, they lack compositionally structured representations involving semantically-meaningful, discrete constituents (Macdonald 1995). By contrast, classicists argue that thinking occurs in a language of thought with a compositional syntax and semantics (Fodor 1975). On this view, cognition involves the manipulation of discrete mental symbols combined according to compositional rules. Hence, the second horn of the dilemma: if some ANNs turn out to exhibit the right kind of structure-sensitive behavior, they must do so because they implement rule-based computation over discrete symbols.
The remarkable progress of LLMs in recent years calls for a reexamination of old assumptions about compositionality as a core limitation of connectionist models. A large body of empirical research investigates whether language models exhibit human-like levels of performance on tasks thought to require compositional processing. These studies evaluate models’ capacity for compositional generalization, that is, whether they can systematically recombine previously learned elements to map new inputs made up from these elements to their correct output (Schmidhuber 1990). This is difficult to do with LLMs trained on gigantic natural language corpora, such as GPT-3 and GPT-4, because it is near-impossible to rule out that the training set contains that exact syntactic pattern. Synthetic datasets overcome this with a carefully designed train-test split.
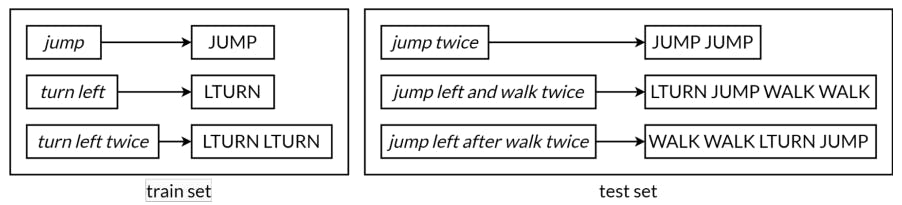
The SCAN dataset, for example, contains a set of natural language commands (e.g., “jump twice”) mapped unambiguously to sequences of actions (e.g., JUMP JUMP) (Lake & Baroni 2018). The dataset is split into a training set, providing broad coverage of the space of possible commands, and a test set, specifically designed to evaluate models’ abilities to compositionally generalize (3). To succeed on SCAN, models must learn to interpret words in the input (including primitive commands, modifiers and conjunctions) in order to properly generalize to novel combinations of familiar elements as well as entirely new commands. The test set evaluates generalization in a number of challenging ways, including producing action sequences longer than seen before, generalizing across primitive commands by producing the action sequence for a novel composed command, and generalizing in a fully systematic fashion by “bootstrapping” from limited data to entirely new compositions.
![Figure 3 | Examples of inputs and outputs from the SCAN dataset (Lake & Baroni 2018) with an illustrative train-test split.[7]](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)
![Figure 3 | Examples of inputs and outputs from the SCAN dataset (Lake & Baroni 2018) with an illustrative train-test split.[7]](https://hackernoon.imgix.net/images/fWZa4tUiBGemnqQfBGgCPf9594N2-528316i.png?auto=format&fit=max&w=1920)


Initial DNN performance on SCAN and other synthetic datasets probing compositional generalization – such as CFQ (Keysers et al. 2019) and COGS (Kim & Linzen 2020) – was somewhat underwhelming. Testing generally revealed a significant gap between performance on the train set and on the test set, suggesting a failure to properly generalize across syntactic distribution shifts. Since then, however, many Transformer-based models have achieved good to perfect accuracy on these tests. This progress was enabled by various strategies, including tweaks to the vanilla Transformer architecture to provide more effective inductive biases (Csordás et al. 2022, Ontanon et al. 2022) and data augmentation to help models learn the right kind of structure (Andreas 2020, Akyürek et al. 2020, Qiu et al. 2022).
Meta-learning, or learning to learn better by generalizing from exposure to many related learning tasks (Conklin et al. 2021, Lake & Baroni 2023), has also shown promise without further architectural tweaks. Standard supervised learning rests on the assumption that training and testing data are drawn from the same distribution, which can lead models to “overfit” to the training data and fail to generalize to the testing data. Meta-learning exposes models to several distributions of related tasks, in order to promote acquisition of generalizable knowledge. For example, Lake & Baroni (2023) show that a standard Transformer-based neural network, when trained on a stream of distinct artificial tasks, can achieve systematic generalization in a controlled few-shot learning experiment, as well as state-of-the-art performance on systematic generalization benchmarks. At test time, the model exhibits human-like accuracy and error patterns, all without explicit compositional rules. While meta-learning across various tasks helps promote compositional generalization, recent work suggests that merely extending the standard training of a network beyond the point of achieving high accuracy on training data can lead it to develop more tree-structured computations and generalize significantly better to held-out test data that require learning hierarchical rules (Murty et al. 2023). The achievements of Transformer models on compositional generalization benchmarks provide tentative evidence that built-in rigid compositional rules may not be needed to emulate the structure-sensitive operations of cognition.
One interpretation of these results is that, given the right architecture, learning objective, and training data, ANNs might achieve human-like compositional generalization by implementing a language of thought architecture – in accordance with the second horn of the classicist dilemma (Quilty-Dunn et al. 2022, Pavlick 2023). But an alternative interpretation is available, on which ANNs can achieve compositional generalization with non-classical constituent structure and composition functions. Behavioral evidence alone is insufficient to arbitrate between these two hypotheses.[8] But it is also worth noting that the exact requirements for implementing a language of thought are still subject to debate (Smolensky 1989, McGrath et al. 2023).
On the traditional Fodorian view, mental processes operate on discrete symbolic representations with semantic and syntactic structure, such that syntactic constituents are inherently semantically evaluable and play direct causal roles in cognitive processing. By contrast, the continuous vectors that bear semantic interpretation in ANNs are taken to lack discrete, semantically evaluable constituents that participate in processing at the algorithmic level, which operates on lower-level activation values instead. This raises the question whether the abstracted descriptions of stable patterns observed in the aggregate behavior of ANNs’ lower-level mechanisms can fulfill the requirements of classical constituent structure, especially when their direct causal efficacy in processing is not transparent.
For proponents of connectionism who argue that ANNs may offer a non-classical path to modeling cognitive structure, this is a feature rather than a bug. Indeed, classical models likely make overly rigid assumptions about representational formats, binding mechanisms, algorithmic transparency, and demands for systematicity; conversely, even modern ANNs likely fail to implement their specific architectural tenets closely. This leaves room for connectionist systems that qualify as ‘revisionist’ rather than implementational, with novel kinds of functional primitives like distributed microfeatures, formed through intrinsic learning pressures rather than explicit rules (Pinker & Prince 1988). Such systems may not only satisfy compositional constraints on processing, like their classical counterparts, but also what Smolensky et al. (2022a) call the continuity principle.
The continuity principle holds that information encoding and processing mechanisms should be formalized using real numbers that can vary continuously rather than discrete symbolic representations, because it confers critical benefits. First, continuous vector spaces support similarity-based generalization, wherein knowledge learned about one region of vector space transfers to nearby regions, enabling more flexible modeling of domains like natural language that confound approaches relying on mappings between discrete symbols. Second, statistical inference methods exploiting continuity, like neural networks, enable tractable approximation solutions that avoid intractable search through huge discrete search spaces. Finally, continuity permits the use of deep learning techniques that simultaneously optimize information encodings alongside model parameters to discover task-specific representational spaces maximizing performance. In concert, these advantages of leveraging continuity address longstanding challenges discrete symbolic approaches have faced in terms of flexibility, tractability, and encoding. Thus, Transformer-based ANNs offer a promising insight into ‘neurocompositional computing’ (Smolensky et al. 2022a,b): they suggest that ANNs can satisfy core constrains on cognitive modeling, notably the requirements for continuous and compositional structure and processing.
[7] Several train-test splits exist for the SCAN dataset to test different aspects of generalization, such as generalization to longer sequence lengths, to new templates, or to new primitives (Lake & Baroni 2018).
[8] See Part II for a brief discussion of mechanistic evidence in favor of the second hypothesis.


{kind=link}