



When Dun & Bradstreet Holdings Inc. set out to build a suite of analytical capabilities anchored in artificial intelligence three years ago, it confronted a problem that has become common across the enterprise AI landscape: how to scale up AI workflows without sacrificing trust in the underlying data.
Trust wasn’t a negotiable issue. The company’s Data Universal Numbering System, which is the equivalent of a Social Security number for businesses, was already embedded in credit decisioning, compliance, lending and supplier qualification workflows at more than 200,000 customers, including about 90% of the Fortune 500.
Introducing agentic AI created new challenges around transparency, lineage and recoverability that demanded additional safeguards, said Gary Kotovets, D&B’s chief data and analytics officer. “The essence of our business is trust,” he said. “When we started making that data available through AI and agents, we had to make sure the same level of trust carried through.”
Over the course of two years, D&B built a multilayered data resilience framework that includes consistent backup and retention policies, model version controls, confidence scoring and integrity monitoring to detect anomalies and synthetic outputs. It also expanded its governance layer to prevent data leakage and enforce strict rules around who had access to data.
D&B’s Kotovets: “The essence of our business is trust.” Photo: D&B
“We started with [a set of governance standards] that we thought covered everything, but we’ve been adding to them over the last two or three years,” Kotovets said. By the time D&B.AI launched, trust was more than a marketing message; it was a measurable property of the system.
D&B’s experience highlights the pains organizations must take to ensure that AI in general, and agentic AI in particular, can deliver consistently trustworthy results. Recent research suggests that many companies are far from reaching that goal.
As they race to satisfy board-level demands to put AI to work, the foundation of data resilience that supports reliable AI model performance is often overlooked. That’s creating new cybersecurity vulnerabilities and could slow long-term AI adoption if trust erodes.
Security disconnect
A new study by TheCUBE Research found that although most organizations rate their performance as strong against the highly regarded National Institute of Standards and Technology Cybersecurity Framework, only 12% said they can recover all their data after an attack, and 34% experienced data losses exceeding 30% in the past year.
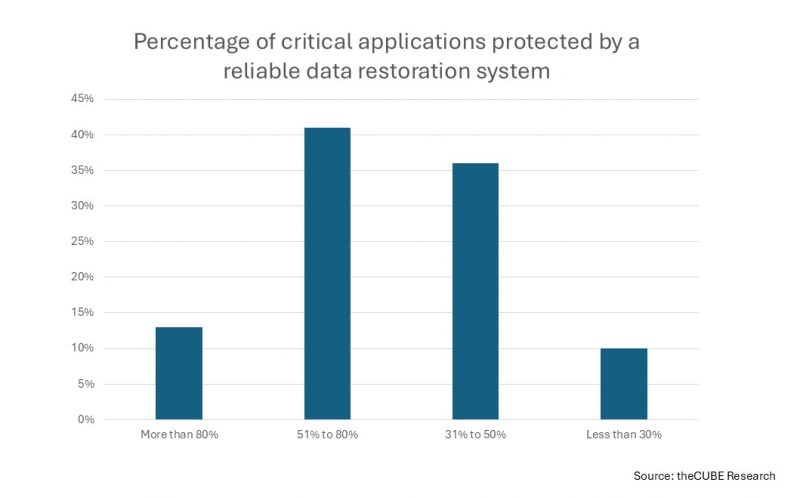

“How can you do agentic AI when your basics are such a mess?” asked Christophe Bertrand, principal analyst for cyber resiliency, data protection and data management at theCUBE Research.
Although there’s broad agreement that AI demands high-quality, well-governed data, the research indicates that AI inference data is often poorly governed, inadequately classified and rarely backed up. Just 11% of respondents back up more than 75% of their AI data, and 54% back up less than 40%, according to theCUBE Research.
Forty-eight percent said less than half of their critical applications are protected by a comprehensive data restoration solution, while only 4% said more than 90% of their critical applications are fully protected.
Agentic amplifier
The risks of poor data resilience will be magnified as agentic AI enters the mainstream. Whereas generative AI applications respond to a prompt with an answer in the same manner as a search engine, agentic systems are woven into production workflows, with models calling each other, exchanging data, triggering actions and propagating decisions across networks. Erroneous data can be amplified or corrupted as it moves between agents, like the party game “telephone.”


Countly’s Soner: “AI amplifies weak data pipelines” Photo: LinkedIn
Other studies have uncovered similar confidence gaps. Deloitte LLP’s recent State of AI in the Enterprise survey of more than 3,000 business and information technology leaders found that while 74% expect to use agentic AI within two years, only 21% have mature governance practices in place for autonomous agents.
A survey of 3,500 IT and business leaders last fall by trust management platform Vanta Inc. found that though 79% are using or planning to use AI agents to protect against cyberattacks, 65% said their planned usage outpaces their understanding of the technology.
A Gartner Inc. report last month asserted that even as executives and chief information security officers “all claim to value cyber resilience, organizations chronically underinvest in it due to both organizational inertia and an outdated zero-tolerance-for-failure mindset.” Gartner said organizations fare worst in the critical response and recovery stages of the NIST framework.
This all adds up to a looming trust problem. Boards and chief information officers agree that artificial intelligence can’t be implemented at scale without high-quality, resilient data. Yet in many organizations, the inference data used to feed AI engines is poorly governed, inconsistently classified and rarely backed up. That makes it all but impossible to verify how decisions are made or to replay and unwind downstream effects.
The barrier to enterprise AI adoption may ultimately be less about model accuracy or the supply of processing power than the ability to guarantee the integrity, lineage and recoverability of the data that AI depends upon.
“AI doesn’t expose weak data pipelines,” said Onur Alp Soner, chief executive of analytics firm Countly Ltd. “It amplifies them.”
Compliance ≠ resilience
Experts cite numerous reasons data protection gets short shrift in many organizations. A key one is an overly intense focus on compliance at the expense of operational excellence. That’s the difference between meeting a set of formal cybersecurity metrics and being able to survive real-world disruption.
Compliance guidelines specify policies, controls and audits, while resilience is about operational survivability, such as maintaining data integrity, recovering full business operations, replaying or rolling back actions and containing the blast radius when systems fail or are attacked.


Info-Tech’s Avakian: Checkbox compliance creates a false sense of confidence. Photo: LinkedIn
Organizations tend to conflate the two, but having plans in place is different from testing them in real-world conditions. “They’ll look at NIST as a control framework and say, ‘OK, we have a policy for this,’” said Erik Avakian, technical counselor at Info-Tech Research Group Inc. and the Commonwealth of Pennsylvania’s former CISO. “They may have a policy, but they haven’t measured it.”
Checkbox compliance creates a “false sense of confidence,” he said. “Have we really gone in and tested those things? And do they work? Some frameworks are a self-assessment without proof of implementation,” he said, allowing CISOs to effectively grade their own work.
Another factor is cybersecurity’s traditional focus on preventing intrusions rather than containing damage. That strategy has become “prohibitively expensive and impractical,” Gartner noted. Its researchers instead recommend, “a new way of thinking that prioritizes cyber resilience and mitigates harm caused by inevitable breaches.”
Someone else’s problem
Organizational factors also create vulnerabilities. Data protection often lives inside the risk management function, which is separate from cybersecurity. Security pros can be lulled into a false sense of complacency by the belief that someone else is taking care of the data.
“Resilience and compliance-oriented security are handled by different teams within enterprises, leading to a lack of coordination,” said Forrester’s Ellis. “There is a disconnect between how prepared people think they are and how prepared they actually are.”


Forrester’s Ellis: “There is a disconnect between how prepared people think they are and how prepared they actually are.” Photo: News
Then there are the technical factors. AI models behave fundamentally differently from traditional software, introducing complexity that conventional data protection measures don’t fully address.
Conventional software is deterministic, meaning it follows predefined rules that ensure the same input always yields the same output. AI models are probabilistic. They use statistical or learned estimation processes to infer plausible outputs from patterns in the training data.
“With interpretive or generative AI, you’re asking the engine to start thinking, and that causes it to spread its wings and stitch together internal and external data sources in ways that were never done before,” said Ashish Nadkarni, group vice president and general manager, worldwide infrastructure research at International Data Corp.
There’s no guarantee that a probabilitistc model will produce the same results every time. Whereas deterministic systems fail loudly by generating errors, AI systems fail silently by delivering confident but wrong outputs.
Off the mark
Missing or corrupted data can lead models to make decisions or recommendations that appear plausible but are far off the mark. In large language models, these errors manifest as “hallucinations,” which occur up to 20% of the time in many of the most popular chat engines despite years of research aimed at minimizing them.
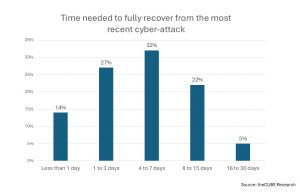

Agentic networks can magnify errors exponentially. “A single upstream data issue becomes a cascading failure,” said Countly’s Soner. “Without clear lineage and integrity guarantees, it becomes impossible to tell whether the model was wrong, the data was wrong, or the system state itself was inconsistent.”
More on data resilience and AI:
Organizations must treat data resilience as a core AI service layerl.
AI-driven predictive analytics can safeguard enterprise storage against escalating security threats.
How AI-driven automation and managed detection services are transforming cyber resiliency
Attacks will succeed; the best strategy is to protect backups and use assessments to guide data resilience improvements.
There are ways to audit model performance to protect against anomalies, but they require examining input data and tracking the model’s reasoning process. Lost or compromised data can make such troubleshooting impossible.
“A change to one library deep in the stack can have no impact, or it can mean you’re suddenly getting completely different answers, even though nothing appears to have changed,” said Miriam Friedel, vice president of machine learning engineering at Capital One Financial Corp. Observability, logging and automated scanning support the type of forensic analysis needed to diagnose such problems, she said.
Data overload
AI also introduces new data classes. Training data provides the real-world context that complex models learn from. It’s typically unstructured, and the volumes can be very large, making classification and conventional data protection measures difficult to implement. It’s tempting to take a “kitchen sink” approach to training data, loading everything into the model and letting it sort things out.


Capital One’s Freidel: You can get “completely different answers, even though nothing appears to have changed.” Photo: X
But that can be an invitation to a cybersecurity disaster. “If you have a database, you know what’s in that database. If you have an [enterprise resource planning] application, you know it’s only going to fetch data that is relevant to it,” said IDC’s Nadkarni. “With AI, there’s a level of sprawl within and outside of the company. People don’t often fully understand how massive that sprawl is and what kind of bad actors might be at play trying to compromise the data.”
Prompts and inference data need to be captured in context logs, which document the information the model had at the time it made a decision. These records are critical where safety, accountability and recoverability matter.
Inference data is what models use to make decisions. It poses unique challenges because securing it while in use in third-party or cloud environments is difficult. Inference data is critical because it fuels continuous training, can be exposed externally and may trigger automated workflows. Despite these risks, many organizations don’t go to the trouble of classifying inference data, making it hard to protect.
“Inference outputs are rarely treated as first-class data,” said Countly’s Soner. “Replay becomes impossible once actions have been triggered. AI-generated data needs to be governed in the same way as source data, not treated as logs or exhaust.”
“There’s a lack of appreciation for generated data because it summarizes a variety of input data,” said Gagan Gulati, senior vice president and general manager of data services at NetApp Inc. “Primary data typically has rules and regulations around its use. Generated data typically has none.”
That wouldn’t be a problem if generated data simply vanished into the ether, but it has a way of sticking around. Without controls in place, AI models can remember prior interactions and incorporate them into their short-term memory. This recursive output can magnify errors and introduce new vulnerabilities.
PII problem
For example, users who include personally identifiable information in prompts can see that data come back in responses days later. Without proper guardrails, prompt data can even become part of a model’s training set and re-emerge in unpredictable ways.


NetApp’s Gulati: “Primary data typically has rules around its use. Generated data typically has none.” Photo: News
AI also presents new challenges in managing data access, a critical component of resilience. Organizations don’t want to train models on production data, so they make copies. “That’s a data lineage problem,” said NetApp’s Gulati. “The data set is leaving the perimeter, but all the same protection rules must apply.”
Agents present new challenges in data classification and access controls, said David Lee, field chief technology officer at identity management firm Saviynt Inc. Weak entitlements, overly broad permissions and abandoned accounts undermine data resilience because all AI systems ultimately reach data through the same identity constructs as people.
Organizations need fine-grained authorization layers to ensure agents don’t access sensitive information they don’t need, he said. AI is so new, though, that such controls often are not in place.
According to Saviynt’s recent AI Risk Report, 71% of 235 security leaders said AI tools already access core operational systems but just 16% believe they govern that access effectively. More than 90% said they lack full visibility into AI identities or could detect or contain misuse if it happened.
“The complicated part is when you have a delegation model where an AI agent calls sub-agents that have their own permissions,” Lee said. “It becomes almost impossible to see what’s connected to what, what privileges are in place and who is granting what access.”
Agents’ ability to derive new types of data by combining multiple sources presents problems with data classification, a necessary component of access management.
“Let’s say I’ve got data classified as confidential and other data classified as personally identifiable information,” Lee said. “My agent creates a report question by putting that data together. It’s now come up with new data. How does that get classified?”
Classification is a slow and arduous task that many businesses abandoned or simplified years ago, but Lee sees the discipline staging a return. “We’re going to need a three-tiered approach around what the data is, who has the right to see it, and what they want to do with it,” he said. “Today’s systems weren’t designed for that.”
Getting ready for AI
These factors collectively underscore the need for organizations to prioritize data resilience as they move AI models from pilots into production. By most accounts, they have a long way to go. A recent survey of 200 people in charge of AI initiatives at software providers and enterprises by CData Software Inc. found that only 6% said their data infrastructure is fully ready for AI.


Saviynt’s Lee: Agent delegation can make it “impossible to see what’s connected to what.” Photo: LinkedIn
“AI remains a black box for many enterprises, and that is a primary reason executives hesitate to trust it,” said Daniel Shugrue, product director at software delivery platform firm Digital.ai Software Inc. “Enterprises aren’t blocked from scaling AI because of models; they’re blocked because they don’t trust the systems that feed, transform and act on the data on which AI depends.”
Data resilience experts advocate for what they call AI-grade recoverability. That encompasses knowing what data was used, what state the model was in at the time and confidence that the process can be replayed or rolled back.
“Part of resiliency is that when things break, you can understand and track down quickly where the breakage is and how to fix it,” said Capital One’s Friedel.
Ensuring data resilience in the AI age requires new tools and skill sets:
- Immutable event logs are permanent, tamper-evident records of system events that ensure every decision and data change can be traced and audited.
- Versioned schemas provide structured data definitions that can be tracked over time.
- End-to-end lineage analysis shows where data originated, how it was transformed and how it influenced model outputs.
- Replayable pipelines enable deterministic process re-execution for reproducing model decisions.
- Blast radius isolation contains the impact of erroneous outputs or actions so failures don’t cascade.
- Tested rollback procedures are documented methods for reverting models, data or system state to a known-good point without business disruption.
- Data retention policies ensure that redundant, and obsolete and trivial data are deleted rather than archived with the risk of contamination.
The success of enterprise AI ultimately depends less on novel model architectures and more on the unglamorous disciplines of cyber resilience, data protection and operational rigor. Organizations that can guarantee the robustness of the data that fuels their AI models will be in a better position to scale agentic systems into core business processes. Those that can’t will remain mired in pilots and proofs of concept. Investing in resilient data foundations now is the clearest path to trusted outcomes later.
Image: News/Google Whisk
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
- 15M+ viewers of theCUBE videos, powering conversations across AI, cloud, cybersecurity and more
- 11.4k+ theCUBE alumni — Connect with more than 11,400 tech and business leaders shaping the future through a unique trusted-based network.
About News Media
Founded by tech visionaries John Furrier and Dave Vellante, News Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.



{kind=link}