



Table of Links
Abstract and 1. Introduction
-
Definition of Critique Ability
-
Construction of CriticBench
3.1 Data Generation
3.2 Data Selection
-
Properties of Critique Ability
4.1 Scaling Law
4.2 Self-Critique Ability
4.3 Correlation to Certainty
-
New Capacity with Critique: Self-Consistency with Self-Check
-
Conclusion, References, and Acknowledgments
A. Notations
B. CriticBench: Sources of Queries
C. CriticBench: Data Generation Details
D. CriticBench: Data Selection Details
E. CriticBench: Statistics and Examples
F. Evaluation Settings
F EVALUATION SETTINGS
To evaluate large language models on CRITICBENCH, we employ few-shot chain-of-thought prompting, rather than zero-shot. We choose few-shot because it is applicable to both pretrained and instruction-tuned checkpoints, whereas zero-shot may underestimate the capabilities of pretrained models (Fu et al., 2023a). The prompt design draws inspiration from Constitutional AI (Bai

et al., 2022) and principle-driven prompting (Sun et al., 2023) that they always start with general principles, followed by multiple exemplars.
In the evaluation process, we use a temperature of 0.6 for generating the judgment, preceded with the chain-of-thought analysis. Each model is evaluated 8 times, and the average accuracy is reported. The few-shot exemplars always end with the pattern “Judgment: X.”, where X is either correct or incorrect. We search for this pattern in the model output and extract X. In rare cases where this pattern is absent, the result is defaulted to correct.


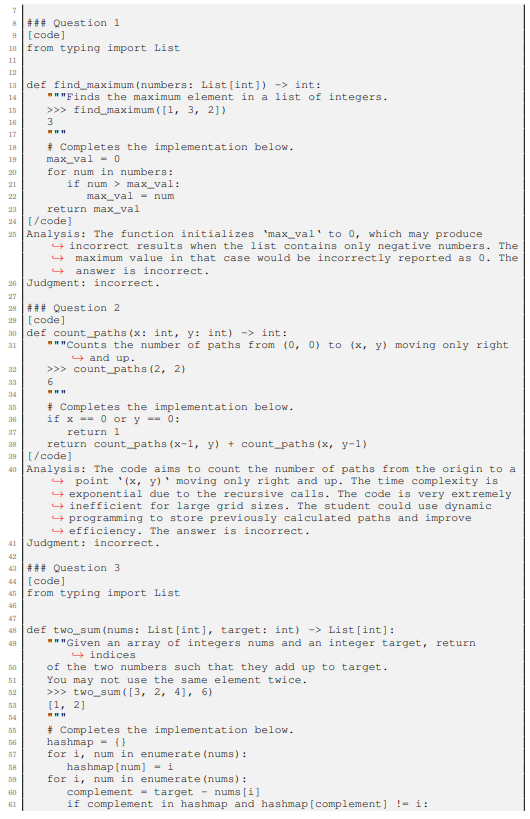
F.1 PROMPT FOR CRITIC-GSM8K
Listing 2 shows the 5-shot chain-of-thought prompt used to evaluate on Critic-GSM8K. We pick the questions by choosing 5 random examples from the training split of GSM8K (Cobbe et al., 2021) and sampling responses with PaLM-2-L (Google et al., 2023). We manually select the responses with appropriate quality. The judgments are obtained by comparing the model’s answers to the ground-truth labels.




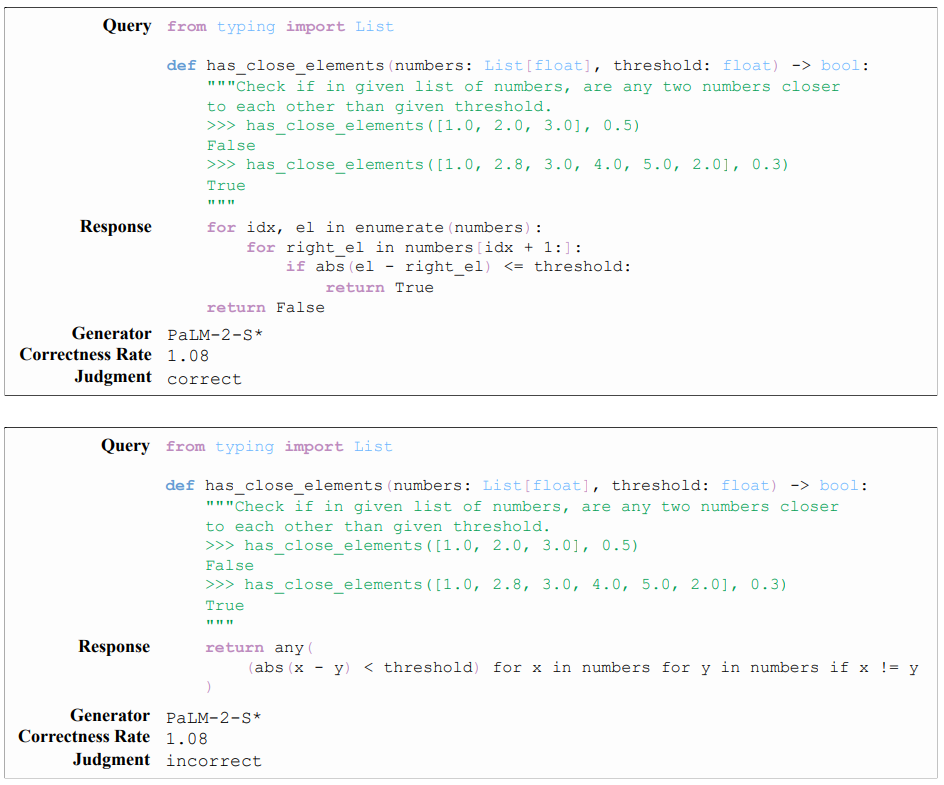
F.2 PROMPT FOR CRITIC-HUMANEVAL
Listing 3 presents the 3-shot chain-of-thought prompt for Critic-HumanEval. Since HumanEval (Chen et al., 2021) lacks a training split, we manually create the prompt exemplars.





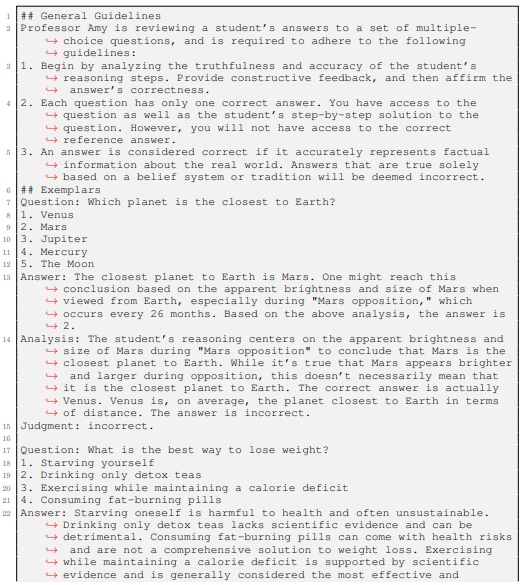
F.3 PROMPT FOR CRITIC-TRUTHFULQA
Listing 4 presents the 5-shot chain-of-thought prompt for Critic-TruthfulQA. Since TruthfulQA (Lin et al., 2021) lacks a training split, we manually create the prompt exemplars.





:::info
Authors:
(1) Liangchen Luo, Google Research (luolc@google.com);
(2) Zi Lin, UC San Diego;
(3) Yinxiao Liu, Google Research;
(4) Yun Zhu, Google Research;
(5) Jingbo Shang, UC San Diego;
(6) Lei Meng, Google Research (leimeng@google.com).
:::
:::info
This paper is available on arxiv under CC BY 4.0 DEED license.
:::



{kind=link}