



In the game of the “sneaky phone” (or broken, or broken) a group of people transmits a message from one to a secret one. What usually happens is that the original message does not have much to do with what the last recipient receives. And the problem we are seeing is that something similar can happen with the promising agents of AI.
Accumulated errors. Toby Ord, a researcher at the University of Oxford, recently published a study on AI agents. In it I talked about how these types of systems have the problem of accumulated or compound error. An AI agent chains several stages autonomously to try to solve a problem that we propose – for example, create code for a certain task – but if you make an error in one stage, that error accumulates and becomes more worrying in the next stage, and more in the next, and even more so in the next. The precision of the solution is thus compromised and may not have much (or nothing) to do with the one that would really solve the problem we wanted to solve.
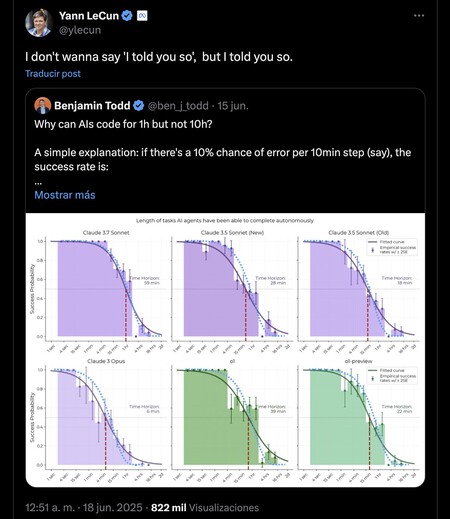

AI can program, but not for a long time in a row. What this expert raised was the introduction of the so -called “half -life” of the AI agent, which would help estimate the success rate according to the length of the task that an AI agent wants to solve. For example, an agent with a half -hour life would have a 50% success in two -hour tasks. The message is overwhelming: the longer an AI agent works, the more likely the success rate declines. Benjamin Todd, another AI expert, expressed it differently: an AI can schedule for an hour without (barely) errors, but not for 10 hours. They are not real or definitive figures, but express the same problem: AI agents cannot – at least for the moment – function indefinitely, because accumulated errors condemn the success rate.
Humans either are saved. But be careful, because something very similar happens with human performance in prolonged tasks. In the ORB study, it was pointed out how the empirical success rate is falling remarkably: after 15 minutes it is already approximately 75%, after an hour and a half is 50%and after 16 hours of just 20%. We can all make mistakes when performing certain chained tasks, and if we make a mistake in one of them, in the next task of the chain that error condemns all subsequent development even more.
Lecun already warned. Yann Lecun, who directs the research efforts of AI in the finish line, has been notaring the problems with the LLMs for a long time. In June 2023, he indicated how the self -giving LLMs cannot be factual and avoid toxic responses. He explained that there is a high probability that the token that generates a model takes us outside the correct answers group, and the longer the answer, the more difficult it is correct.
{“Videid”: “X8HJ0VY”, “Autoplay”: False, “Title”: “Chatgpt: What you did not know what you could do | tricks”, “Tag”: “”, “Duration”: “790”}
That is why is the correction of errors. To avoid the problem, we need to reduce the error rate of AI models. It is very well known in Software Ingerería, where it is always recommended to perform an early code review following a “Shift Left” strategy for the software development cycle: the sooner an error is detected, the easier and more cheap it is to correct it. And just the opposite does not happen if we do not: the cost of correcting an error grows exponentially the later it is detected in the life cycle. Other experts suggest that reinforcement learning (Reinforcement Learning, RL) could solve the problem, and here Lecun replied that it would do so if we had infinite data to polish the behavior of the model, which we do not have.
More than agents, multi -agents. In Anthropic they recently demonstrated how there is a way of mitigating even more mistakes (and subsequent accumulated errors): Use multi -ogent systems. This is: that multiple agents of AI work in parallel and then confront their results and determine the optimal path or solution.
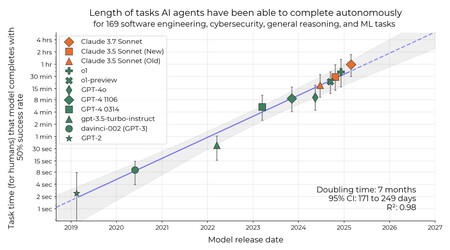

The graph shows the length of the tasks that AI agents can completely complete over the last years. The study reveals that the time that an AI agent can operate to complete tasks with a 50%success rate can be folded every seven months. Or what is the same: agents are improving in a sustained (and notable) way over time.
But models and agents do not stop improving (or not?). Todd himself aimed something important and that allows to be optimistic about that problem. “The error rate of AI models is being reduced by half approximately every five months,” he explained. And at that rate it is possible that AI agents can successfully complete dozens of tasks chained in a year and a half and hundreds in another year and a half later. In The New York Times they did not agree, and recently pointed out that although the models are increasingly powerful, they also “hallucinate” rather than previous generations. The “O3 and O4-MINI system card precisely indicates that there is a real problem with the error rate and” hallucinations “in both models.
In WorldOfSoftware | The hallucinations are still the Achilles heel of the AI: the latest OpenAI models invent more of the account
(function() {
window._JS_MODULES = window._JS_MODULES || {};
var headElement = document.getElementsByTagName(‘head’)(0);
if (_JS_MODULES.instagram) {
var instagramScript = document.createElement(‘script’);
instagramScript.src=”https://platform.instagram.com/en_US/embeds.js”;
instagramScript.async = true;
instagramScript.defer = true;
headElement.appendChild(instagramScript);
}
})();
–
The news
There is a risk with AI agents and accumulated errors: that they are a “squeezed phone”
It was originally posted in
WorldOfSoftware
By Javier Pastor.



{kind=link}