


Authors:
(1) Dan Kondratyuk, Google Research and with Equal contribution;
(2) Lijun Yu, Google Research, Carnegie Mellon University and with Equal contribution;
(3) Xiuye Gu, Google Research and with Equal contribution;
(4) Jose Lezama, Google Research and with Equal contribution;
(5) Jonathan Huang, Google Research and with Equal contribution;
(6) Grant Schindler, Google Research;
(7) Rachel Hornung, Google Research;
(8) Vighnesh Birodkar, Google Research;
(9) Jimmy Yan, Google Research;
(10) Krishna Somandepalli, Google Research;
(11) Hassan Akbari, Google Research;
(12) Yair Alon, Google Research;
(13) Yong Cheng, Google DeepMind;
(14) Josh Dillon, Google Research;
(15) Agrim Gupta, Google Research;
(16) Meera Hahn, Google Research;
(17) Anja Hauth, Google Research;
(18) David Hendon, Google Research;
(19) Alonso Martinez, Google Research;
(20) David Minnen, Google Research;
(21) Mikhail Sirotenko, Google Research;
(22) Kihyuk Sohn, Google Research;
(23) Xuan Yang, Google Research;
(24) Hartwig Adam, Google Research;
(25) Ming-Hsuan Yang, Google Research;
(26) Irfan Essa, Google Research;
(27) Huisheng Wang, Google Research;
(28) David A. Ross, Google Research;
(29) Bryan Seybold, Google Research and with Equal contribution;
(30) Lu Jiang, Google Research and with Equal contribution.
Table of Links
Abstract and 1 Introduction
2. Related Work
3. Model Overview and 3.1. Tokenization
3.2. Language Model Backbone and 3.3. Super-Resolution
4. LLM Pretraining for Generation
4.1. Task Prompt Design
4.2. Training Strategy
5. Experiments
5.1. Experimental Setup
5.2. Pretraining Task Analysis
5.3. Comparison with the State-of-the-Art
5.4. LLM’s Diverse Capabilities in Video Generation and 5.5. Limitations
6. Conclusion, Acknowledgements, and References
A. Appendix
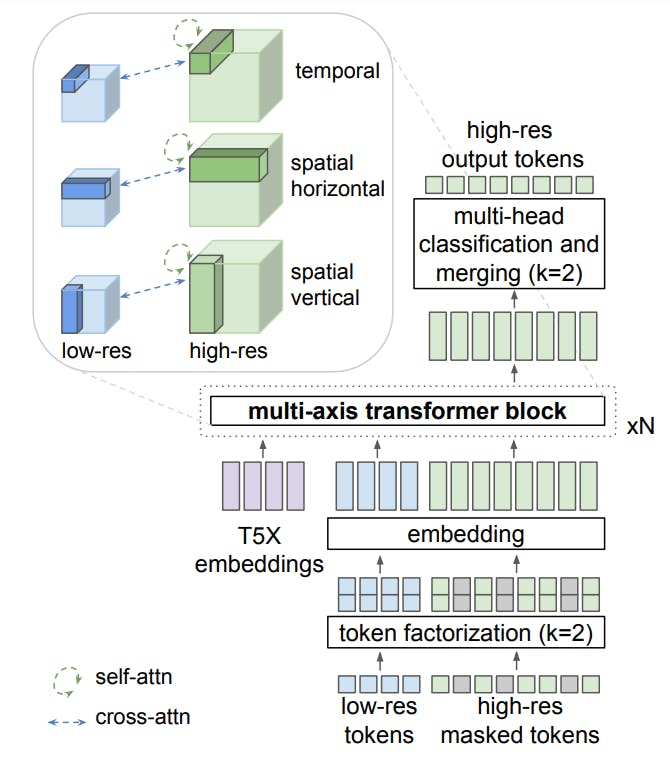
3. Model Overview
We propose an effective method for video generation and related tasks from different input signals by leveraging large language models. Our model consists of three components: (1) modality-specific tokenizers, (2) a language model backbone (Fig. 2), and (3) a super-resolution module (Fig. 3). The tokenizers map input data – i.e. image pixels, video frames, and audio waveforms – into discrete tokens in a unified vocabulary. The visual and audio tokens are flattened into a sequence of integers. Next, the LLM accepts these tokens as input along with text embeddings, and is responsible for generative multi-task and multimodal modeling. As illustrated in Fig. 2, VideoPoet conditions on text
3.1. Tokenization
We employ the MAGVIT-v2 (Yu et al., 2023c) tokenizer for joint image and video tokenization, and the SoundStream (Zeghidour et al., 2021) tokenizer for audio. Visual and audio vocabularies are concatenated into a unified vocabulary. The text modality is represented by embeddings.




We enforce causal temporal dependency, which facilitates the generation of longer videos. To jointly represent images and videos, we encode the initial frame of a video or a static image into tokens with a consistent shape of (1, 16, 16). We use the COMMIT (Yu et al., 2023a) encoding scheme to tokenize the inpainting and outpainting tasks.
Audio tokenizer. We tokenize audio clips with a pretrained SoundStream (Zeghidour et al., 2021) tokenizer. We embed 2.125 seconds of audio to produce 106 latent frames



with a residual vector quantizer (RVQ) of four levels. To improve audio generation performance, we transpose the clip before flattening so that the model predicts the full audio clip at each RVQ granularity level before moving on to the finer grained levels. Finally, each RVQ level has a disjoint vocabulary with each level containing 1,024 codes. This results in a combined audio vocabulary size of 4,096 codes.
Text embedding as input. Pretrained text representations, in general, outperform training our model by learning text tokens from scratch. We use pretrained language embeddings from a frozen T5 XL encoder (Raffel et al., 2020). For tasks with text guidance, such as text-to-video, T5 XL embeddings are projected into the transformer’s embedding space with a linear layer.



{kind=link}