


Table of Links
-
Introduction
-
Hypothesis testing
2.1 Introduction
2.2 Bayesian statistics
2.3 Test martingales
2.4 p-values
2.5 Optional Stopping and Peeking
2.6 Combining p-values and Optional Continuation
2.7 A/B testing
-
Safe Tests
3.1 Introduction
3.2 Classical t-test
3.3 Safe t-test
3.4 χ2 -test
3.5 Safe Proportion Test
-
Safe Testing Simulations
4.1 Introduction and 4.2 Python Implementation
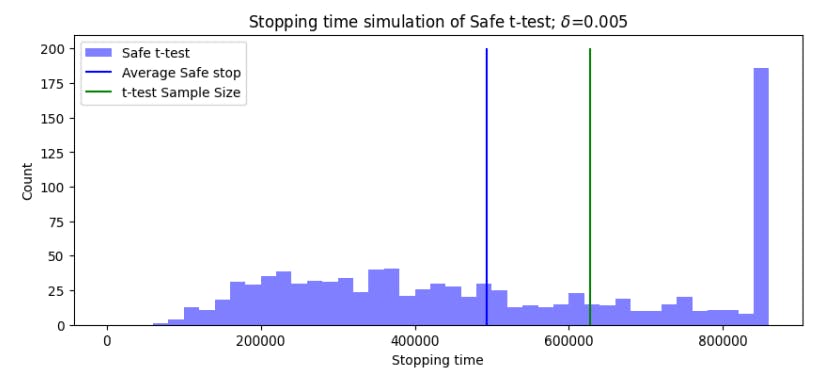
4.3 Comparing the t-test with the Safe t-test
4.4 Comparing the χ2 -test with the safe proportion test
-
Mixture sequential probability ratio test
5.1 Sequential Testing
5.2 Mixture SPRT
5.3 mSPRT and the safe t-test
-
Online Controlled Experiments
6.1 Safe t-test on OCE datasets
-
Vinted A/B tests and 7.1 Safe t-test for Vinted A/B tests
7.2 Safe proportion test for sample ratio mismatch
-
Conclusion and References
2.4 p-values




The p-value represents how strongly the data contradict the hypothesis. A small p-value suggests that the data do not accurately represent the hypothesis. p-values are used widely throughout the sciences, but are so misunderstood that the American Statistical Association published an article on common misconceptions in order to alleviate the issues [WL16]. One popular misconception among researchers is that a p-value is the probability that the null hypothesis is true. Furthermore, a p-value less than 0.05 is also often used as the sole justification for scientific inference. Perhaps the most egregious issue with p-values is “phacking,” in which unfavourable data are omitted from the analysis in order to influence the results [Hea+15]. Thus, due to their outsized importance in scientific publications, their potential for misinterpretation, and their potential for abuse, many scientists have taken a vocal stance against p-values [AGM19], with over 800 signatories calling to abolish p-values.
This has led to increased motivation for statisticians to develop new and improved methods to analyze scientific data. One pervasive issue has been the unreliability of statistical results during the course of an experiment.
2.5 Optional Stopping and Peeking
As an experimenter conducts an A/B test, modern data infrastructure allows them to view the results in real-time. There are good reasons for them to do this. First of all, experiments are expensive to run. If an experiment’s target metric is showing negative results, there may be pressure to stop the experiment as it costs the company money. A second reason to consider stopping an experiment has to do with secondary and guardrail metrics, which provide additional information about possible causal factors of the hypothesis or unintended impacts of the test. If these metrics are showing negative results, this may suggest that the experimental feature has an unintended negative consequences for the users. A further reason for monitoring results is to check the effect size for the feature. The effect size determines the sample size, and hence the length of time that the test must run. If the effect is large, the experimenter may suggest to stop the experiment since the necessary information has been collected.
Examining the results of the test before it’s complete is known as peeking, and it has unintended consequences for the results of the test. With standard A/B testing, peeking leads to an inflated false positive rate for each metric being monitored. Figure 1 shows how the false positive probability increases with successive peeks. The data are derived from the same distribution and tested with a two-sided, two-sample t-test. If the data are observed at the end of the test, there should be a false positive rate of α. However, since each peek gives a new opportunity for a false positive, the probability of a false positive becomes more and more likely throughout the test.
The false positive probability increases throughout the test because the test is not safe under optional stopping. In other words, continuously monitoring the results in Figure 1 to decide when to stop the experiment can impact the outcome of the test. This is a problem for which the ideal solution is one which allows the experimenter to monitor their results while keeping false positives below α. As we will see, safe testing is the solution that allows for this continuous monitoring and anytime-valid inference of test results.
Author:
(1) Daniel Beasley
This paper is available on arxiv under ATTRIBUTION-NONCOMMERCIAL-SHAREALIKE 4.0 INTERNATIONAL license.


{kind=link}