


Table of Links
Abstract and 1. Introduction
2 Concepts in Pretraining Data and Quantifying Frequency
3 Comparing Pretraining Frequency & “Zero-Shot” Performance and 3.1 Experimental Setup
3.2 Result: Pretraining Frequency is Predictive of “Zero-Shot” Performance
4 Stress-Testing the Concept Frequency-Performance Scaling Trend and 4.1 Controlling for Similar Samples in Pretraining and Downstream Data
4.2 Testing Generalization to Purely Synthetic Concept and Data Distributions
5 Additional Insights from Pretraining Concept Frequencies
6 Testing the Tail: Let It Wag!
7 Related Work
8 Conclusions and Open Problems, Acknowledgements, and References
Part I
Appendix
A. Concept Frequency is Predictive of Performance Across Prompting Strategies
B. Concept Frequency is Predictive of Performance Across Retrieval Metrics
C. Concept Frequency is Predictive of Performance for T2I Models
D. Concept Frequency is Predictive of Performance across Concepts only from Image and Text Domains
E. Experimental Details
F. Why and How Do We Use RAM++?
G. Details about Misalignment Degree Results
H. T2I Models: Evaluation
I. Classification Results: Let It Wag!
H T2I Models: Evaluation
We provide additional quantitative and qualitative results in this section for T2I models evaluated on the “Let It Wag!” dataset.
H.1 Quantitative Results by Retrieval
We provide further analysis on how state-of-the-art T2I models perform on the long-tailed concepts comprising the “Let It Wag!” dataset. As detailed in Sec. 6, we generate 4 images for each concept using Stable Diffusion XL [89], Stable Diffusion v2 [96] and Dreamlike Photoreal [1].
Prompting Strategy. The prompting strategy (system role) used, adapted from Shahmohammadi et al. [105], was:




With this pool of generated images, we conduct a controlled experiment on the long-tailed concepts using nearest-neighbor retrieval as the evaluation metric by querying a generated image and retrieving the top-k results from a gallery of images taken from the “Let It Wag!” dataset. The overall pipeline is as follows:
Setup. We define the query and gallery set for head and tail concepts. For tail concepts, we sample the 25 concepts with the lowest frequency from the “Let It Wag!” dataset. For head concepts, we sample the 25 most frequent concepts for comparison. We use the same prompting strategy with the selected 25 concepts across all 3 T2I models. To create the gallery set, we randomly sample 100 images for each of these concepts. We use DINOv2 [85] ViT-S/14 as the feature extractor.
Results. In Table 5, we provide the Cumulative Matching Characteristic (CMC@k) results for all 3 T2I models used in our experiment. CMC@k was chosen as we are interested in measuring the delta between head and tail concepts for successful retrievals within the top-k retrieved real images for a given generated image. We observe a large performance gap between Head and Tail concepts, providing a quantitative evaluation of generation performance of T2I models.



H.2 Qualitative Results
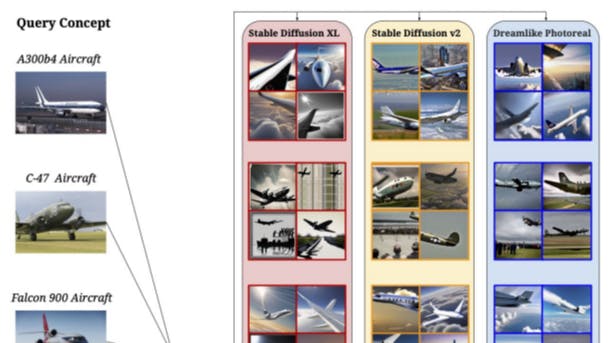
In Fig. 7 of the main text, we provide an initial insight into the qualitative performance of T2I models on “Let It Wag!” concepts. For ease of comprehension and comparison, we segregate concepts into 4 clusters: Aircraft (Fig. 23), Activity (Fig. 24), Animal (Fig. 25) and others (Fig. 26).
Results. Fig. 23 shows T2I models having difficulty in representing an aircraft in its full form in a majority of cases in addition to misrepresenting the specific model in the generated images. Fig. 24 showcases the difficulty T2I models face when representing actions or activities from prompts. Fig. 25 exemplifies the same inability of T2I models to accurately represent animal species. Finally, the remainder of the query set is shown in Fig. 26 and includes the inability to classify and subsequently generate certain species of flowers and objects.












I Classification Results: Let It Wag!
Here, we present the raw accuracy values of the 40 tested models on both Let It Wag! and ImageNet in Tab. 6. For reference, we also report the datasets these models were trained on and the number of parameters for each model. We see clear drops in performance compared to ImageNet, across model sizes, architectures and pretraining datasets.



Authors:
(1) Vishaal Udandarao, Tubingen AI Center, University of Tubingen, University of Cambridge, and equal contribution;
(2) Ameya Prabhu, Tubingen AI Center, University of Tubingen, University of Oxford, and equal contribution;
(3) Adhiraj Ghosh, Tubingen AI Center, University of Tubingen;
(4) Yash Sharma, Tubingen AI Center, University of Tubingen;
(5) Philip H.S. Torr, University of Oxford;
(6) Adel Bibi, University of Oxford;
(7) Samuel Albanie, University of Cambridge and equal advising, order decided by a coin flip;
(8) Matthias Bethge, Tubingen AI Center, University of Tubingen and equal advising, order decided by a coin flip.



{kind=link}