


:::info
Authors:
(1) Hyeongjun Kwon, Yonsei University;
(2) Jinhyun Jang, Yonsei University;
(3) Jin Kim, Yonsei University;
(4) Kwonyoung Kim, Yonsei University;
(5) Kwanghoon Sohn, Yonsei University and Korea Institute of Science and Technology (KIST).
:::
Table of Links
Abstract and 1 Introduction
2. Related Work
3. Hyperbolic Geometry
4. Method
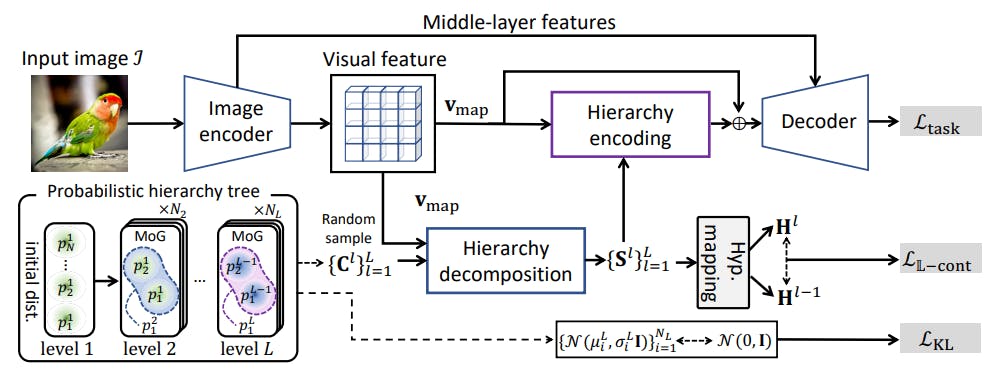
4.1. Overview
4.2. Probabilistic hierarchy tree
4.3. Visual hierarchy decomposition
4.4. Learning hierarchy in hyperbolic space
4.5. Visual hierarchy encoding
5. Experiments and 5.1. Image classification
5.2. Object detection and Instance segmentation
5.3. Semantic segmentation
5.4. Visualization
6. Ablation studies and discussion
7. Conclusion and References
A. Network Architecture
B. Theoretical Baseline
C. Additional Results
D. Additional visualization
C. Additional Results
C.1. Fine-tuning vs. full-training.
We also investigate the effectiveness of our proposed method when it is applied to training the model from scratch. For fair comparisons, we evaluate the classification performance of Hi-Mapper trained with the full-training scheme (350 epochs) and fine-tuning scheme (baseline + 50 epochs) of the same learning objectives on ImageNet-1K [36]. As shown in Tab. 6, the experimental results demonstrate that the finetuning scheme is better-suitable than full-training in terms of understanding the structural organization of visual scenes.
D. Additional visualization
For a more comprehensive understanding, we will provide additional visualization results that are included in the main paper and also examine the visual hierarchy in CNNs [59], as shown in Figure 7, 8. This will offer insights into the feature representation aspects in transformer structures and CNNs, as well as the benefits of applying our method.


![Figure 8. Visualization of visual hierarchy trees decomposed by Hi-Mapper(ENB4) trained on ImageNet-1K [36] with classification objective. The same color family represents the same subtree.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-gja31w9.png)

:::info
This paper is available on arxiv under CC BY 4.0 DEED license.
:::


{kind=link}