



Dear Readers,
Have you ever trained a machine learning model and found yourself wondering why it behaves like a distracted student during a pop quiz? If so, allow me to introduce you to the often-overlooked hero of the machine learning pipeline — Feature Engineering.
This week, I’ll dive into what truly goes on in feature engineering — from the essentials to the elegant, with a dash of wit and a sprinkle of practical wisdom.




Why Feature Engineering Deserves Your Attention
To put it plainly:
If data is the fuel, then feature engineering is the refining process. Without it, your high-performance machine learning engine is just hanging in one place. Great features can transform a mediocre model into a masterpiece.
Poor features? Well, even the best algorithm can’t save you from that.
Think of it like baking—you may have the best oven (model), but if you’re using expired flour (features), no one will eat your cake.
Three Categories of Feature Selection Techniques
Let’s explore the core techniques — categorised for your analytical pleasure.
1. Filter Methods — The Data Bouncers
Filter methods assess features before any model is involved. They are fast, model-agnostic, and wonderfully judgemental!
-
Correlation Coefficient: If two features are best friends (i.e., highly correlated), we politely ask one to leave. Redundancy is not invited to this party.
-
Chi-Squared Test: A classic from the world of statistics — perfect for categorical features. It tests whether your features and target variable are statistically compatible.
-
Mutual Information: This quantifies the amount of surprise one variable provides about another. If a feature tells your model something useful — it stays.
Pro Tip: Filter methods are ideal for early-stage exploration, especially when you’re staring at a dataset with more columns than a spreadsheet should legally allow.
2. Wrapper Methods — The Feature Stylists
These techniques treat feature selection as a full-blown search problem. They evaluate subsets of features by actually training models and choosing the combinations that perform best.
-
Forward Selection: Start with nothing. Add one feature at a time. Keep the ones that make your model smile.
-
Backward Elimination: Start with everything. Remove the least useful feature repeatedly — a Marie Kondo approach to data.
-
Recursive Feature Elimination (RFE): Like an intense game of musical chairs. It trains the model, kicks out the weakest features, and repeats until only the top contenders remain.
Did You Know? While wrapper methods are often accurate, they’re also computationally expensive. So bring snacks and resourses for yourself and your computer.
3. Embedded Methods — The Feature Whisperers
Embedded methods incorporate feature selection into the model training process itself. They’re smart, efficient, and just a bit opinionated.
-
Lasso Regression (L1 Regularization): Think of this as “zero-tolerance” feature selection. It shrinks some coefficients all the way down to zero, effectively removing them.
-
Ridge Regression (L2 Regularization): A gentler sibling — it doesn’t eliminate features but reduces their influence. Very democratic!
-
Tree-Based Methods: Algorithms like Random Forests and Extra Trees offer built-in feature importance scores. They decide who gets to speak and who gets to sit quietly in the back (something I would always use to weigh my feature to the target).
🎓 Lesson: Embedded methods often offer the best of both worlds efficient and accurate and they’re built into many popular algorithms.
The Rise of Automated Feature Engineering
Now, let’s address the elephant in the server room — automation. Yes, feature engineering can now be automated. No, it won’t take your job (yet).
Automated Feature Engineering uses algorithms to generate and select features with minimal human intervention.
Tools You Should Know:
- Featuretools: Pioneering deep feature synthesis.
- TPOT: Uses genetic programming to optimise pipelines.
- H2O.ai: Offers Driverless AI — heavy on automation, light on headaches.
- Auto-Sklearn: Scikit-learn’s futuristic cousin.
Practical Tips for Aspiring Feature Engineers
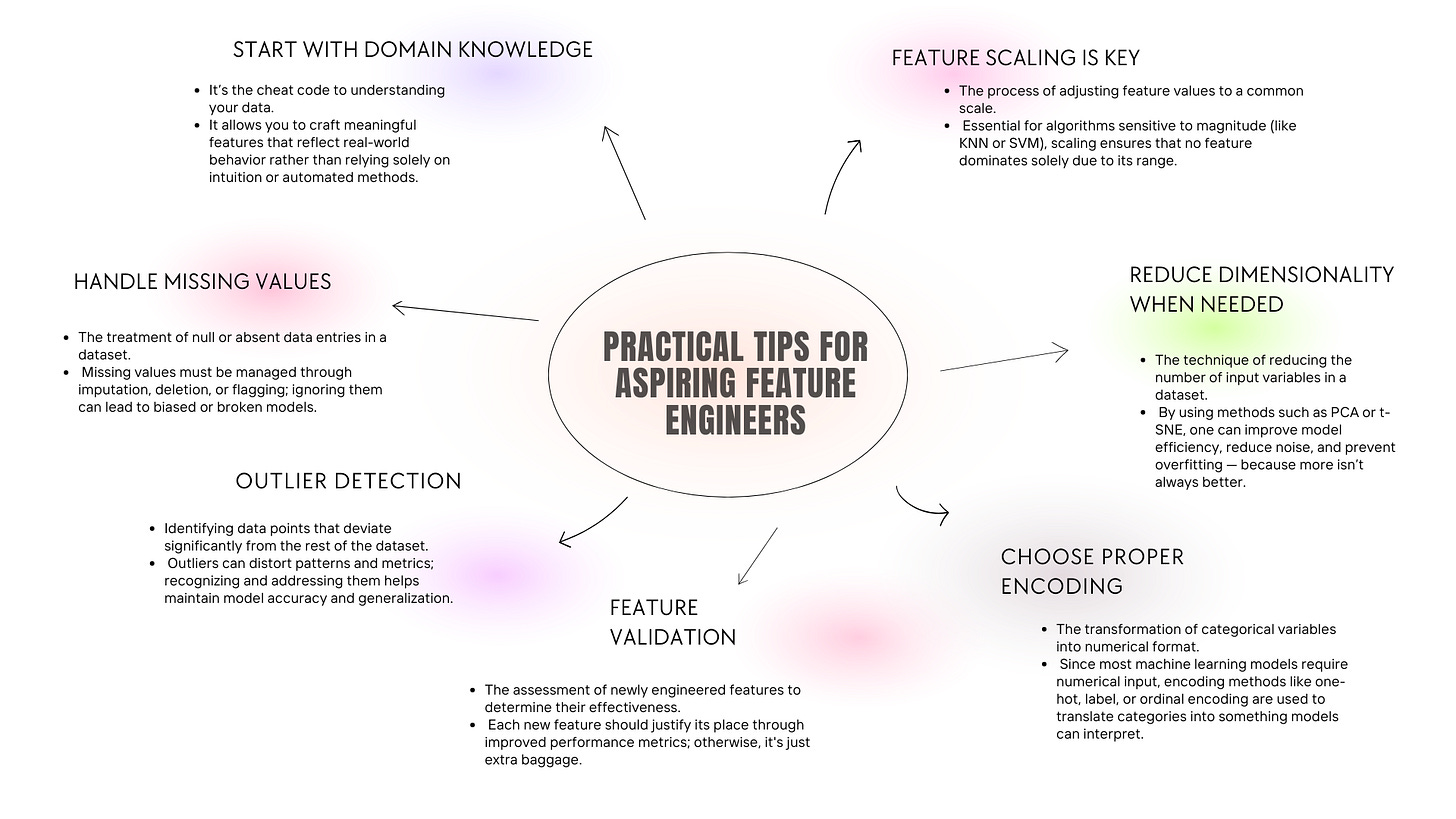


In Conclusion…
Feature engineering is not just a technical step — it’s a creative process. It’s where your understanding of data meets the mathematical machinery of machine learning.
We explored the landscape — from filter methods to wrappers, from Lasso to trees, from handcrafted interaction terms to fully automated systems. While tools are evolving and models are becoming smarter, your insight as a data scientist remains irreplaceable.
Next Edition Teaser: In my next issue, we’ll tackle the mysterious world of Dimensionality Reduction — what it is, when to use it, and why PCA might just become your new best friend.
Warm regards,
Thanks for reading my post.Subscribe for free to receive new posts and support my work.



{kind=link}