



Table of Links
Abstract and 1. Introduction
-
Definition of Critique Ability
-
Construction of CriticBench
3.1 Data Generation
3.2 Data Selection
-
Properties of Critique Ability
4.1 Scaling Law
4.2 Self-Critique Ability
4.3 Correlation to Certainty
-
New Capacity with Critique: Self-Consistency with Self-Check
-
Conclusion, References, and Acknowledgments
A. Notations
B. CriticBench: Sources of Queries
C. CriticBench: Data Generation Details
D. CriticBench: Data Selection Details
E. CriticBench: Statistics and Examples
F. Evaluation Settings
D CRITICBENCH: DATA SELECTION DETAILS
D.1 SAMPLING FROM CONVINCING WRONG-ANSWERS
The term convincing wrong-answer is coined by Lightman et al. (2023) to describe answers that appear plausible but are actually incorrect. Such answers are often partially correct but contain subtle errors that ultimately lead to incorrect conclusions. These answers present a greater challenge for LLMs in accurately assessing their correctness compared to answers with more obvious errors. Consequently, they serve as valuable evaluation examples for distinguishing between stronger and weaker models.
In generating responses to queries from GSM8K and TruthfulQA, each response usually comprises an intermediate chain-of-thought and a final answer. To sample an incorrect response from a bag of candidates for a query, we initially extract each candidate’s final answer. Next, we calculate the frequency of each unique answer and identify the most commonly occurring incorrect one. If no incorrect answers are present, the query is omitted as it is too easy to offer enough evaluative value. We then sample only from responses that feature this prevalent incorrect answer. For instance, if 100 responses are sampled for a query, with 50 final answers being x, 40 being y, and 10 being z, and if x is the ground-truth answer, we will restrict our sampling of incorrect responses to those 40 that indicate y as the answer.
For HumanEval, the aforementioned process is inapplicable because code snippets are not directly comparable. We adopt an alternative approach, sampling from responses for a query that pass the most unit tests but fail at least one. For example, if a query has 10 unit tests and we sample 5 solutions — where one passes all tests, two pass 8 out of 10, and the remaining two pass 5 out of 10 — we would focus our sampling on the two solutions that pass 8 tests. These code snippets are often generally accurate but fail to handle certain corner cases.
D.2 COMPLEXITY-BASED SELECTION
Fu et al. (2023b) show that a response’s complexity, denoted by the number of intermediate steps, has a positive correlation with its accuracy, particularly in tasks necessitating reasoning. To leverage this finding, we employ a complexity-based sampling strategy when selecting from either correct or commonly incorrect responses.
Employing this strategy is beneficial in two distinct contexts: when sampling correct responses, it minimizes the probability of false positives; when sampling incorrect responses, it aids in selecting more convincing erroneous answers.
D.3 FILTERING BY GENERATOR
During development, we find that smaller models, specifically PaLM-2-XXS and PaLM-2-XS, yield responses of very low quality. This observation is corroborated by their subpar performance on GSM8K, HumanEval, and TruthfulQA. Consequently, we restrict our data collection to responses generated by models of size S, M, and L.
D.4 CERTAINTY-BASED SELECTION


E CRITICBENCH: STATISTICS AND EXAMPLES
E.1 STATISTICS
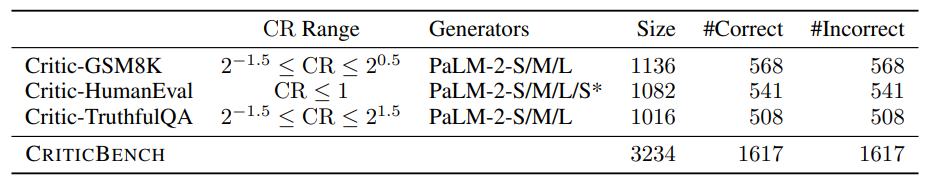
Table 2 presents the detailed statistics of CRITICBENCH and each subset.

E.2 EXAMPLES
Figure 8, 9 and 10 provide examples in CRITICBENCH.
:::info
Authors:
(1) Liangchen Luo, Google Research (luolc@google.com);
(2) Zi Lin, UC San Diego;
(3) Yinxiao Liu, Google Research;
(4) Yun Zhu, Google Research;
(5) Jingbo Shang, UC San Diego;
(6) Lei Meng, Google Research (leimeng@google.com).
:::
:::info
This paper is available on arxiv under CC BY 4.0 DEED license.
:::



{kind=link}