


Modern distributed systems are all about tradeoffs. Performance, reliability, scalability, and consistency don’t come for free — you always pay a price somewhere. That’s where the CAP theorem comes in: it’s the starting point for understanding the unavoidable compromises in distributed design.
Why is the CAP theorem true? What does it actually explain? And, most importantly, is it enough? In this post, we’ll explore the CAP theorem, its limitations, the critiques it has faced, and how newer ideas like PACELC are pushing the conversation forward. Let’s dive in.
CAP Theorem
The first version of the CAP theorem started as a debate between ACID vs. BASE. But over time, it evolved, got a formal proof, and graduated to become the CAP theorem as we know it today.
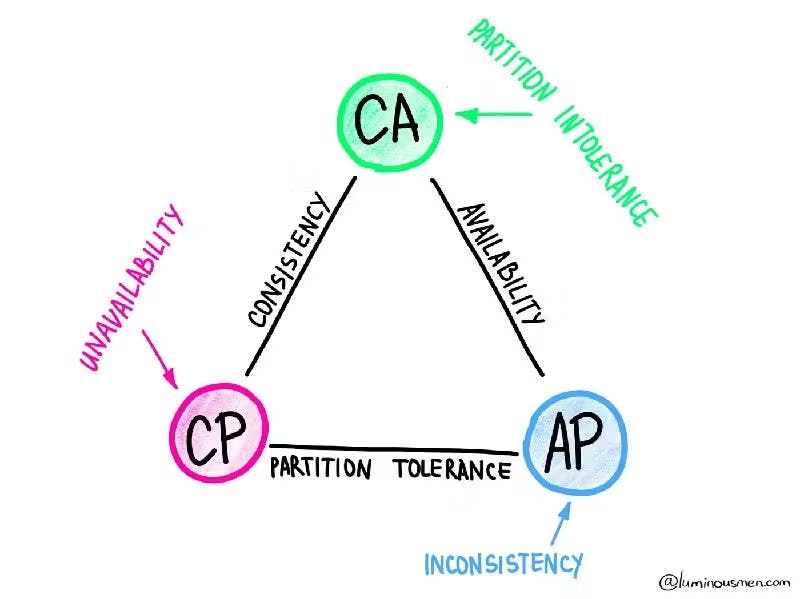
The CAP theorem states that a distributed system can satisfy at most two out of three properties simultaneously:
- Consistency
- Availability
- Partition Tolerance
This limitation forces engineers to make tough tradeoffs depending on the system’s goals and the realities of their distributed environments.
Consistency




Consistency in CAP is not the same as the consistency in ACID transactions. In CAP theorem it refers to linearizability or strong consistency. It means that all nodes in a distributed system must always present a single, up-to-date view of the data, regardless of which node processes the request. This means that every read operation reflects the most recent write, no matter which node you query.
💡 Consistency in ACID, on the other hand, focuses on ensuring that a transaction brings the database from one valid state to another valid state, following the rules defined by the database schema. It’s more about enforcing integrity constraints (like foreign keys, unique constraints, etc) and ensuring the database isn’t left in an invalid state, even in the face of crashes.
Availability


Availability in CAP means that every non-failing node must return a response for every request it receives, regardless of network partitions. In other words, if a healthy node gets a request, it must process and respond to it. However, CAP does not guarantee the response will always be “correct” or up-to-date — it just ensures the node doesn’t fail silently (for example, in AP system nodes might respond with stale data during a partition to ensure availability).
💡 Eric Brewer (the original author of CAP) originally described this property a bit more flexibly as: “almost all queries should get a response”. However, in the formal proof of CAP, availability was made stricter, requiring “every query to receive a response as long as the node handling it is healthy”.
In practice, though, availability is not an absolute guarantee — it often depends on system-specific constraints, like how long you’re willing to wait for a response. For real-world systems, response time (or timeouts) plays a critical role in shaping your SLA (service-level agreement), even though CAP itself does not directly account for latency. More on it in this blog post.
Partition tolerance

Partition tolerance is all about surviving network failures. If nodes can’t communicate due to a network split (partition), the system must still meet its consistency or availability guarantees, depending on its design choices. A partition happens when nodes can’t communicate due to dropped packets, timeouts, or network splits.
Distributed systems don’t live in a fairy-tale world with perfect networks. Packets get dropped, timeouts happen, and latency spikes are unavoidable. Because of this, partition tolerance is non-negotiable in any distributed system — partitions will happen sooner or later, so you can’t “choose” to ignore it, no matter how tempting it might sound.
In CAP, partition tolerance doesn’t mean the system keeps running as if nothing happened. It means the system has to decide whether to prioritize availability (AP) or consistency (CP) during a partition. If you were to ignore partition tolerance, you’d essentially be building a non-distributed monolithic system.
CAP explained
The easiest way to understand CAP is to consider a network partition — a situation where two parts of a distributed system cannot communicate with each other. In such a scenario, the system faces three possible outcomes:
- If one part of the system accepts updates while the other is isolated, the two parts will have inconsistent states. This results in a loss of C (Consistency).
- If the system chooses to remain consistent, it must block updates in one or both parts of the partition to ensure a unified state across all nodes. This leads to a loss of A (Availability) because some requests will be denied or delayed indefinitely.
- If the system chooses to remain available (A) and consistent (C) without tolerating the partition (P), it isn’t truly distributed. This would require the nodes to interact and reconcile state, which is impossible during a partition.
Thus, during a partition, the system can only satisfy two of the three properties (C, A, or P). Once the partition is resolved (i.e. the nodes interact again), the system can regain all three properties, but during the partition itself, tradeoffs are unavoidable.
Implications of the theorem
A consequence of the theorem for asynchronous systems is that only three combinations of consistency, availability, and partition tolerance are possible:
AP (Availability + Partition Tolerance)
Systems of this type respond to queries, but the data returned may not always be up-to-date, with slower updates of the data but “always” available. Examples of such a system are DNS, DynamoDB, and Cassandra.
CP (Consistency + Partition Tolerance)
Systems of this type always return up-to-date data, but some, or even all, nodes in the system may not respond if partitioned. It gives atomic updates but can lead to timeouts. NoSQL databases such as Google BigTable, MongoDB, HBase, and Redis are all systems of this type.
CA (Consistency + Availability)
Systems of this type always return up-to-date data when there are no partitions. Because of the last limitation, usually, such systems are used only within one machine. Examples are classical relational databases.
In reality, we choose between CP and AP because CA is basically a monolith without partitions. For large-scale systems, designers cannot abandon P and therefore have a difficult choice between C and A.
In CA, node failure means complete unavailability of the service. But this does not disable scalability, since we can clone independent monoliths and distribute the load over them
Critique of the CAP Theorem
The CAP theorem has been a foundational concept in distributed systems, but it’s not without its limitations. For all its clarity in presenting the idea of tradeoffs, the CAP theorem has often been criticized for oversimplifying complex realities, which has led to misunderstandings and misapplications.
1. Tradeoffs Only Apply During Partitions
One of the most common critiques is that the CAP theorem’s tradeoffs — choosing between consistency (C) and availability (A) — only apply when a network partition (P) actually occurs. In normal operation, when the network is stable and no partitions exist, there’s no inherent tradeoff between consistency and availability.
Furthermore, these tradeoffs aren’t universal across the entire system. Within the same distributed system:
- Different parts of the system may experience different tradeoffs based on context (like user location, type of data).
- Specific operations might prioritize consistency while others prioritize availability.
- Decisions can vary at runtime depending on factors like load, latency, or user requirements.
This nuance is often lost in high-level discussions of CAP, leading to oversimplified classifications of systems as “CP” or “AP” across the board.
2. CAP Ignores Latency
Another important critique is that the CAP theorem does not account for latency, even though latency and partitioning are deeply connected in practice. For example:
- A slow network (high latency) may look indistinguishable from a partition.
- Timeouts—used to detect failures—are subjective and heavily dependent on system design and network conditions. What one system defines as a “partition” might just be a transient delay for another.
In real-world distributed systems, when a partition or high latency occurs, the system must make a decision within a timeout period: prioritize availability by returning a possibly stale result, or prioritize consistency by waiting longer (and potentially failing to respond). CAP’s binary view doesn’t capture the complexity of these decisions.
3. CAP Properties Are Not Binary
The CAP theorem presents consistency, availability, and partition tolerance as binary properties—you either have them or you don’t. But in practice, all three properties exist on a spectrum:
- Availability isn’t a binary “on/off” property—it ranges from 0% to 100%. For instance, a system may guarantee 99.99% availability, but that still allows for small periods of unavailability.
- Consistency has varying levels, from eventual consistency to causal consistency to strong consistency. Not every application requires full linearizability.
- Partition tolerance itself isn’t a clear-cut event. Systems may disagree on whether a partition exists (like one node sees a timeout as a failure, while another continues operating normally).
This continuous nature of the properties makes CAP overly simplistic for modeling the complexities of modern distributed systems.
PACELC Theorem
While CAP revolutionized our understanding of tradeoffs in distributed systems, it’s not the final word on the subject. The PACELC theorem described by Daniel J. Abadi’s is considered an alternative approach to the design of distributed systems. It is based on the CAP model, but in addition to consistency, availability, and partition tolerance it also includes latency and logical exclusion between combinations of these concepts.
PACELC introduces two distinct modes of operation for distributed systems:
- Partition mode (PAC): What tradeoff does the system make when a partition occurs? Here, we revisit the classic CAP tradeoff between availability (A) and consistency (C).
- Else mode (ELC): What tradeoff does the system make when there’s no partition, and the network is functioning normally? In this mode, the system faces a different tradeoff — between latency (L) and consistency (C).

The Latency-Consistency Tradeoff
While partitions are inevitable in distributed systems, they are rare compared to the challenges that arise during normal operation. In modern distributed systems, latency is often a bigger bottleneck than network partitions, particularly for global-scale applications. This is where PACELC focuses — by addressing the tradeoffs that occur when the system operates without partitions. Unlike CAP, which focuses solely on behavior during failure scenarios, PACELC emphasizes the decisions architects must make every day to balance latency (L) and consistency (C):
- Strong consistency requires coordination and synchronization between nodes to maintain a unified view of the data. This overhead introduces delays, slowing down response times.
- Low-latency systems (like those adopting eventual consistency) prioritize speed by relaxing consistency guarantees. These systems respond faster but may occasionally return stale or inconsistent data.
By extending the conversation beyond partitions to include normal operation, PACELC ensures that the everyday performance of distributed systems is treated with the importance it deserves.
Wrapping it Up
The formulation of the CAP theorem has been a significant event in the community, and studies of its impact on distributed systems design have shown that designers of distributed systems should not limit the system to two properties – they should strive to maximize the guarantees required in each particular case. For this purpose, it is reasonable to divide the system into segments, each of which has its own requirements, and to design the system based on the requirements of each of the segments.
The CAP theorem has been a cornerstone of distributed systems thinking for decades. It gave us a framework to reason about the inherent tradeoffs of consistency, availability, and partition tolerance. But in many ways, it’s a simplification of reality, assuming binary choices and ignoring critical factors like latency.
PACELC builds on CAP, acknowledging that:
- Tradeoffs exist even when partitions don’t.
- Latency is a first-class concern in distributed system design.
Both CAP and PACELC are valuable tools, but neither is a step-by-step recipe for building systems. Instead, they provide mental models for evaluating tradeoffs and understanding the limits of distributed architectures.
Additional materials
Thank you for reading!
Curious about something or have thoughts to share? Leave your comment below! Check out my blog or follow me via LinkedIn, Substack, or Telegram.



{kind=link}