Popular imagination is currently framing The Future as an inexorable, relentless march towards the age of Skynet, Hal 9000 and R2-D2. The reality is both subtler and more demanding. While today’s headlines are filled with dreams of
In fact, as models grow in complexity and computational demands, experts are warning that foundational technologies enabling AI development may soon not evolve fast enough to create anything better than OpenAI’s o3 model.
A handful of fault‑lines will determine the outcome. Any structural weakness surrounding these foundational elements of AI’s present and future could burst ambitions that may very well have already reached bubble territory.
But first… we need a framework
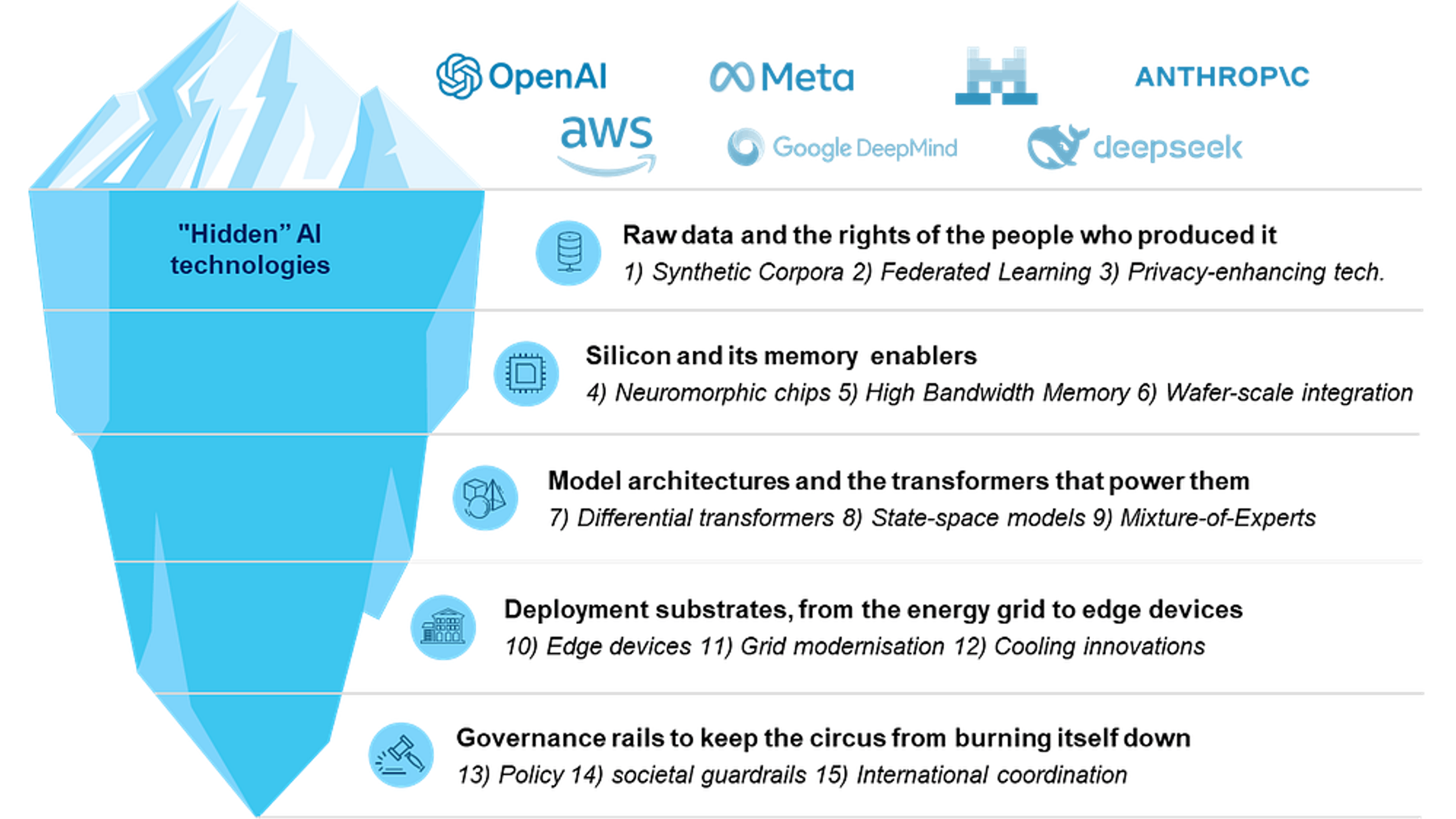
Large-scale AI is less a single marvel than a relay race of inter-locking technologies. Skip one baton pass and the whole spectacle face-plants. For the purpose of this article, the interlocks needed to have working AI models look roughly like this:
- Raw data and the rights of the people who produced it
- Silicon and its memory enablers
- Model architectures and the transformers that power them
- Deployment substrates, from the energy grid to edge devices
- Governance rails to keep the circus from burning itself down
Raw data and the rights of the people who produced it
AI algorithms need data to create text, images and video. Over the past half-decade, the internet has offered OpenAI, Google, Meta, Anthropic and their colleagues access to a free and broad database to train their foundation models on. Lawsuits aside, it has worked well for them. But the feast is now near over; the internet may well be too small for AGI to emerge, and regulators are starting to care about data privacy when data is harvested straight from users. Three technologies need to fully emerge to ensure raw data can continue to be AI’s life-blood.
1. Synthetic corpora are needed to create endless training sets
Instead of relying on human‑created data, AI companies now use AI to create texts and images for other models to learn from. This allows them to produce unlimited data points without running out, or compromising sensitive information. This is particularly powerful in settings where broad data sets are not available (healthcare, financial, autonomous vehicle development, etc). These collections are synthetic corpora… and yes, there is a catch.
If data created by one model to train another is imprecise, and those flaws are allowed to cascade without human correction, wording and ideas will quickly loop back on themselves. The result is model collapse: each generation a blurrier photocopy, errors and clichés compounding until scale alone can’t buy improvement.
Guardrails, in the form of rich domain variation, human‑data refresh cycles, and filters, are essential to keep the well from getting poisoned.
- Why it matters*:* If synthetic corpora is not well implemented (as it is undoubtedly needed), tomorrow’s large models will hit a hard ceiling no matter how much compute we throw at them.
2. Federated learning is needed to respect data privacy
Human-created data will always be needed, but does this mean we have to give up the idea of privacy to serve the all-powerful algo? Maybe not. Through a process called federated learning, our devices could teach “shared” AI models on the devices themselves, doing away with the need to send raw data back to a large data-center.
In this process, only the model’s “lessons learned” (tiny weight updates, not the raw photos or messages) are sent back, so nothing personal ever leaves the device. To keep those updates secret in transit, systems wrap them in a special kind of math called fully homomorphic encryption. FHE is like a locked box the server can shake and stir without ever opening; it can calculate new model weights on the encrypted numbers and still never see what’s inside.
Finally, it’s possible to shrink each update with low‑rank adaptation, which stores only the most important tweak directions instead of rewriting the whole model. That keeps the files small enough for phones with modest bandwidth and memory.
Put together, these tricks let millions of devices co‑train a powerful language model, keep everyone’s data private, and do it efficiently enough to scale.
- Why it matters*:* Skynet needs not happen. By learning about our privacy options, we can influence the future of AI, and ask large AI companies to do right by us. Done right, edge learning keeps regulators and customers happy while models improve.
3. Privacy‑enhancing technologies can help build better guardrails
If federated learning isn’t widely implemented, companies may turn to differential privacy, sprinkling a little mathematical “static” into the training mix. The noise is tuned so the AI model still learns broad patterns (how viruses spread, what a purchase looks like, etc.), yet nothing can be traced back to one person’s medical record or shopping cart.
Two other major privacy‑enhancing technologies exist: secure multiparty computation (several cooks each own part of a secret recipe and bake the cake together without any one cook seeing the whole recipe) and trusted execution environments (a tiny vault iscreated inside a chip: data goes in, computation happens in the vault, results come out, data stays in the vault).
Each layer helps, but they aren’t free. More noise or heavier cryptography means privacy‑versus‑accuracy trade‑off, as well as performance hits and higher-than-expected energy bills.
- Why it matters*:* Differential privacy and other privacy-enhancing technologies let companies share and train AI without sharing raw secrets. But the knobs must be set with care, balancing privacy, speed, and accuracy. We must crusade for more privacy while being mindful that the answer from companies will be “OK but it will make the algorithm worse”. When they say that, we should remind them that they’re the ones with the burden of innovation. They claim to be all-knowing harbingers of the future, after all.
Silicon and its memory enablers
Silicon (aka chips, semiconductors, GPUs, etc.) is where AI “happens”. Entire books have been written about these small technological marvels, which now sit at the center of many geopolitical discussions. But Moore’s Law is slowing, and Dennard scaling has been dead since 2006. The industry now faces a choice: redesign silicon or redesign expectations.
4. Neuromorphic chips can reduce energy use and allow on-device compute
Nvidia has managed to capture over 90% of the AI accelerator market. But it may not be the winner in 10 years. Companies like BrainChip, Intel and IBM are going into a completely different direction to GPUs: neuromorphic architectures.
Inspired by the biological structure of the brain, this way of building chips offer a more energy-efficient and adaptable alternative to traditional GPUs. Picture a million fireflies in a dark field. A GPU forces every bug to flash in lock‑step, whether or not there’s anything interesting to signal. A neuromorphic chip lets each firefly blink only when it actually has news, and only the nearby insects that care about this news will notice. Most of the field therefore stays dark… and their strength lasts all night. That’s the trick: the “neurons” on a chip like the SpiNNaker 2 sit silent until they need to pass a one‑bit “spike” down the line, so the whole board runs on about the same juice as a household lightbulb.
In practice that means glasses that can translate sign language or a pocket drone that autonomously dodges branches. The hardware listens for whispers instead of shouting through a megaphone, and the savings in power are enormous.
- Why it matters*:* Cheap cognitive power everywhere also means more surveillance toys, so the societal debate shifts from “can we run the model?” to “should we run it at all?”.
5. Memory breakthroughs are needed more than anything else
Even the fastest GPU turns into a very expensive paperweight the moment it has to wait for data. A chip can’t do B if another is still working on A, or if the message that A is done is taking ages to arrive. That bottleneck is the “memory wall”… and that’s where High Bandwidth Memory comes in.
Its 4th iteration (HBM4, due in 2026) is specifically optimized for use in high-performance computing environments, delivering twice as much information per second as HBM3. In practice that means fewer idle clock cycles, shorter training runs, and the headroom to scale models without setting the power budget on fire.
NB: if this section seems short, it’s because explaining what DRAM and compute dice are would take another 500 words.
- Why it matters*:* If the tech falters, we will hit a wall where bigger models just wait around for memory; progress stalls even with shinier GPUs. And a lot of use cases are dependent on this technology being deployed properly and on time.
6. Wafer-scale integration could solve many latency issues (but would create energy issues)
If it takes too long for information to go from one chip to another, why not combine them into one very large chip? That’s the idea behind wafer-scale integration.
In practical terms that means a trillion-parameter model can sit on a single chip instead of being scattered across 16 GPU boards and a byzantine network fabric.
It’s not just theory: Cerebras Systems is building a processor featuring 900,000 cores and 7,000 times more memory bandwidth than leading GPUs. This architecture enables 10 times lower latency for generative AI inference. That’s the good news for companies planning AI-enabled products. However, these chips need a lot of power: as much as 30 NVIDIA H100 GPUs. This makes for rather complex math on pros and cons, and perhaps only very specific use cases. Manufacturing has also proven… tricky.
- Why it matters*:* If wafer-scale proves reliable, training times will drop from weeks to hours and experimentation will flourish. Companies implementing them would however be solving a latency problem by creating an energy problem.
Model architectures and the transformers that power them
Modern generative AI systems are powered by a neural‑network architecture called transformers. Transformers work by using an internal table (the “attention mechanism”) that asks, for every word in the input, “how strongly should I pay attention to every other word?”
This mechanism means that the compute work required goes up quadratically as the size of queries increases. 3 words mean 9 connections, 4 mean 16, 5 means 25, and so on. This creates fundamental bottlenecks for processing extended contexts. Three approaches are being explored.
7. Differential transformers make attention mechanisms “smarter”
While classical transformers “pay attention” to all words, differential techniques first apply noise‑cancelling attention, automatically turning down the volume on irrelevant signals, so only useful information stands out.
The concept also introduces “negative attention”, letting the system actively label pairs of tokens that should push away from each other, helping the model avoid false connections rather than merely paying them less mind.
Finally, the training process penalises duplicated behaviour among “attention heads” so each head learns a different pattern instead of wasting effort on the same one. Together, these tweaks let the model learn faster, use memory more efficiently, and deliver more accurate, consistent results.
- Why it matters*:* Differential transformers allow for fewer hallucinations, sharper long‑context recall and 30% to 40% less compute for the same accuracy in small‑to‑mid LLMs. This lowers the financial and carbon cost of building powerful language systems, widening access beyond the richest labs. The transformer paradigm is however unchanged: compute needed grows quadratically the more tokens are added to a prompt.
8. State-Space Models create “attention-free” recurrence
While “regular” transformers reread the whole conversation every time they add a new word (like someone who flips back to page 1 before writing each sentence) state‑space models (e.g. Mamba, S4) carry a learned “state” forward. This means that doubling a prompt only doubles the work (instead of the quadratic alternative).
These models also chop long prompts into bite‑sized chunks that GPUs can chew on in parallel, then stitching the pieces back together so the answer is identical to what could have been otherwise accomplished, but arrives much faster.
The entire update fits inside one tightly packed set of instructions, eliminating memory round‑trips. Because it can recompute little pieces on the fly, it hardly stores anything in slow memory, which slashes energy use.
- Why it matters*:* Put together, these tricks let tomorrow’s assistants digest much, much longer streams (hour‑long podcasts, week‑long chats, etc). This opens the door for new use cases (particularly around genomics).
9. Mixture-of-Experts tricks allow for more parameters
And then, we have Mixture-of-Experts tricks, which basically switch on only the parts of a network (the experts) that matter for a given prompt. DeepSeek’s low-budget “R-1” model showed how these ideas reduce training bills by 40% without reducing quality.
Whereas differential transformers clean up what attention is already doing and state‑space models replace attention altogether with something that scales linearly, MOE adds capacity sparsely so only the most relevant sub‑network fires per token. Together they mark three orthogonal bets on the future: smarter attention, attention‑free recurrence, and smart scaling.
However, all those dormant experts must still live in GPU memory, routers must juggle tokens to avoid “hot” experts.
- Why it matters*:* Efficiency breakthroughs bite into the “scale is all you need’’ mantra, potentially democratising the creation of very large foundation models.
Deployment substrates, from edge devices to the energy grid
AI is often thought of as incorporeal. It is, after all, an algorithm. It has no weight. One cannot touch it. It however very much lives in the real world. It runs on devices. It needs energy to become alive. And that energy makes the devices hot, requiring new and innovative types of cooling.
10. Edge devices put generative models in your pocket
Since the creation of GPUs, models have lived in the cloud, which itself lives in physical data centres. In this world, every prompt requires a round‑trip to the cloud. Now the tide is reversing: phones and laptops are shipping with processing units that can handle inference locally (meaning one could use an LLM even on airplane mode).
Google’s Gemini Nano framework, for example, lets Android apps summon a trimmed foundation model in milliseconds. No network, no server fees, and tighter privacy guarantees.
These deployments don’t change the mathematics of AI, but they do feed off other required advances: smarter attention heads cut compute waste, state‑space recurrence slashes context cost, and “Experts” keep most parameters cold until they’re needed. The net effect is that what once required a building now fits in one’s pocket.
- Why it matters****: On‑device inference eliminates the latency and privacy penalties of the cloud, drops serving costs to zero, and spreads powerful AI to billions of phones and low‑cost PCs. It enables always‑available assistants in areas with poor connectivity, keeps sensitive data (health logs, camera feeds) local by default, and reduces the embodied carbon of every token generated. This is all good news for us, maybe bad news for pure AI players, who would not be able to charge a monthy fee to users (but rather a one-off).
11. Grid‑modernisation and flexible power sourcing keep the lights on
We need a lot of electricity to power AI. And we need to heat our homes and keep factories running. But the high‑voltage “highways” that would deliver that extra energy is already congested. In the US, the median wait to connect a new energy source to the electricity grid is five years. If the wires don’t bulk up as fast as the silicon, GPUs will sit throttled or idle, and our Ai dreams will be held back years, if not decades.
Three parallel options are emerging to unblock the situation:
Layered together, these tactics buy time. But not forever.
- Why it matters: if unlimited, green energy becomes a reality, AI can keep scaling without torching climate targets or bankrupting electricity companies. Miss the window and we get moratoria (Dublin already has one), wasted IT budgets and a dirtier air as major players will not hesitate to use electricity-creating diesel generators fill the gap.
12. Cooling innovations remove the heat bottleneck
A few facts. One, AI is made possible by processing units. Two, these units require ever-more energy to work on ever-complex algorithms. Three, energy cannot be created or destroyed. Put together: the electricity brought to power AI creates heat. And a lot of it.
For a while, fans were able to do the job. But they are now no longer enough, and liquid cooling needs to be implemented across the board, in most AI data centers. Direct‑to‑chip and immersion cooling, for example, swap server fans for cold plates or baths that move heat 1,000× faster than air.
Liquid cooling is, by definition, also a water access story. Evaporative cooling (heat makes steam that goes in the air) can gulp up to 5 million gallons a day (same as a town of 25,000 people). Closed loops are needed to ensure a resource that is already in short supply is not monopolised by the AI overlords.
Finally, once the heat generated by compute is absorbed by water, it becomes a feature, not a bug. Equinix’s Paris PA10 campus warmed the Olympic Aquatics Centre, while Meta’s Odense site already heats 11,000 Danish homes.
- Why it matters: Crack cooling and every other elements in the AI value chain (super‑pods, memory fabrics, serverless inference…) gets room to breathe. Efficiency improves, grid headroom rises, water use plummets, and the waste‑heat dividend buys social licence in cities already wary of AI’s footprint. Ignore it and we strand billions in silicon that can’t run flat‑out without melting the place.
Governance rails to keep the circus from burning itself down
Technology alone won’t decide AI’s fate. Politicians will. Policy, social safety nets, and cross‑border rules form the outer cage that lets the inner machinery run without sparking revolt or sanctions.
13. Policy sets the tone for it all
AI is dangerous. That’s just a fact. Tools being created today are already being used to propagate fake news, to encourage self-harm, to reproduce biases. Laws are needed.
Europe’s AI Act is already there. by August 2026, any “high‑risk” system (credit, hiring, medical, etc.) will need to clear an external audit. In Washington, the 2025 administration tore up parts of the previous White House safety order, so federal agencies now lean on the voluntary (lol) NIST risk framework while states such as Colorado pass their own binding rules.
Output labels are also under a microscope. The EU Act both insists on visible watermarks and hidden provenance tags so deepfakes can be traced in court as easily as they travel online.
Finally, regulators have started to squeeze the hardware. The US Commerce Department now requires a licence for some chips and training runs. Europe is drafting a similar “compute logbook.”
- Why it matters: There is a reason compliance tooling is rapidly becoming a profitable market. Audits, labels and chip controls have become as real a cost as GPUs. AI players need to adapt. Sure, it’s mostly Europe now, but when the inevitable deaths start to pile up, other nations will pay attention, too.
14. Social‑economic cushions are clearly needed
Even the smartest silicon cannot outrun political backlash if workers feel discarded.
Countries that survived earlier automation waves show a repeatable formula: flexible labour markets paired with generous safety nets and relentless re‑skilling. Denmark’s “flexicurity” model, for example, allows firms to hire and shed staff with minimal red tape while unemployment insurance, wage‑replacement schemes and rapid retraining soften the blow of redundancy. Singapore puts cash in citizens’ digital wallets through its SkillsFuture programme, letting any mid‑career worker spend credits on AI‑related micro‑credentials the moment their job mutates.
At the EU level, the €19B Just Transition mechanism is already underwriting wage bridges, coding boot camps and start‑up grants in regions most exposed to upheaval. Meanwhile, the US’ CHIPS Act and Japan’s reskilling tax credits are carving out similar funds on the other side of the world.
- Why it matters: The quicker displaced workers land a fresh paycheque, the less oxygen there is for anti‑tech populism, punitive taxes or blanket moratoria. Economic cushions buy society the time it needs to adapt, preserve consumer demand and keep the political licence for AI experimentation intact. American companies haven’t yet learned this… but they will.
15. International coordination is needed more than ever
Governance loses bite at the water’s edge. Recognising this, the G7 launched the “Hiroshima Process”, a voluntary (lol) code that asks signatories to watermark synthetic content, publish safety evaluations and install incident‑reporting hotlines.
The United Nations has also convened a High‑Level Advisory Body to weld national rules into a shared risk taxonomy and draft the blueprint for a global AI governance framework.
Meanwhile, the United States, the Netherlands and Japan have tightened export controls on extreme‑ultraviolet lithography, just as China calls for an international AI coordination agency to police model misuse. The result is a fragile but unmistakable drift toward common baseline rules governing compute exports, model audits and emergency take‑down procedures.
- Why it matters: Without a minimal layer of harmonisation, firms will migrate to the laxest jurisdiction, adversarial actors will train red‑line models in secrecy, and AI “safe states” will become juicy espionage targets. Shared guardrails turn the technology race from a zero‑sum sprint into a managed relay.
Treating progress based on the performance of AI models is comfortable but deceitful. Cerebras can churn a trillion-parameter network in hours, yet without HBM4 bandwidth it starves. Federated learning preserves privacy, but without sparse architectures your phone’s battery dies trying. Each link multiplies, rather than adds, value along the chain; weakness anywhere devalues everything upstream.
The decade-long score card will therefore read less like “AI won, AI lost” and more like “did enough links upgrade in time?” Right now the answer hovers at maybe.
Either way, the only reliable prediction is that the next breakthrough will look suspiciously boring at first glance. Keep an eye on the plumbing.
Good luck out there.






{kind=link}