
Authors:
(1) Albert Gu, Machine Learning Department, Carnegie Mellon University and with equal contribution;
(2) Tri Dao, Department of Computer Science, Princeton University and with equal contribution.
Table of Links
Abstract and 1 Introduction
2 State Space Models
3 Selective State Space Models and 3.1 Motivation: Selection as a Means of Compression
3.2 Improving SSMs with Selection
3.3 Efficient Implementation of Selective SSMs
3.4 A Simplified SSM Architecture
3.5 Properties of Selection Mechanisms
3.6 Additional Model Details
4 Empirical Evaluation and 4.1 Synthetic Tasks
4.2 Language Modeling
4.3 DNA Modeling
4.4 Audio Modeling and Generation
4.5 Speed and Memory Benchmarks
4.6 Model Ablations
5 Discussion
6 Conclusion and References
A Discussion: Selection Mechanism
B Related Work
C Mechanics of Selective SSMs
D Hardware-aware Algorithm For Selective SSMs
E Experimental Details and Additional Results
3.3 Efficient Implementation of Selective SSMs
Hardware-friendly architectures such as convolutions (Krizhevsky, Sutskever, and Hinton 2012) and Transformers (Vaswani et al. 2017) enjoy widespread application. Here we aim to make selective SSMs efficient on modern hardware (GPU) as well. The selection mechanism is quite natural, and earlier works attempted to incorporate special cases of selection, such as letting ∆ vary over time in recurrent SSMs (Gu, Dao, et al. 2020). However, as previously mentioned a core limitation in the usage of SSMs is their computational efficiency, which was why S4 and all derivatives used LTI (non-selective) models, most commonly in the form of global convolutions.
3.3.1 Motivation of Prior Models
We first revisit this motivation and overview our approach to overcome limitations of prior methods.
• At a high level, recurrent models such as SSMs always balance a tradeoff between expressivity and speed: as discussed in Section 3.1, models with larger hidden state dimension should be more effective but slower. Thus we want to maximize hidden state dimension without paying speed and memory costs.
• Note that the recurrent mode is more flexible than the convolution mode, since the latter (3) is derived from expanding the former (2) (Gu, Goel, and Ré 2022; Gu, Johnson, Goel, et al. 2021). However, this would require computing and materializing the latent state ℎ with shape (B, L, D, N), much larger (by a factor of N, the SSM state dimension) than the input x and output y of shape (B, L, D). Thus the more efficient convolution mode was introduced which could bypass the state computation and materializes a convolution kernel (3a) of only (B, L, D).
• Prior LTI SSMs leverage the dual recurrent-convolutional forms to increase the effective state dimension by a factor of Nx (≈ 10 − 100), much larger than traditional RNNs, without efficiency penalties.
3.3.2 Overview of Selective Scan: Hardware-Aware State Expansion
The selection mechanism is designed to overcome the limitations of LTI models; at the same time, we therefore need to revisit the computation problem of SSMs. We address this with three classical techniques: kernel fusion, parallel scan, and recomputation. We make two main observations:
• The naive recurrent computation uses O(BLDN) FLOPs while the convolutional computation uses O(BLD log(L)) FLOPs, and the former has a lower constant factor. Thus for long sequences and not-too-large state dimension N, the recurrent mode can actually use fewer FLOPs.
• The two challenges are the sequential nature of recurrence, and the large memory usage. To address the latter, just like the convolutional mode, we can attempt to not actually materialize the full state ℎ.
The main idea is to leverage properties of modern accelerators (GPUs) to materialize the state ℎ only in more efficient levels of the memory hierarchy. In particular, most operations (except matrix multiplication) are bounded by memory bandwidth (Dao, Fu, Ermon, et al. 2022; Ivanov et al. 2021; Williams, Waterman, and Patterson 2009). This includes our scan operation, and we use kernel fusion to reduce the amount of memory IOs, leading to a significant speedup compared to a standard implementation.

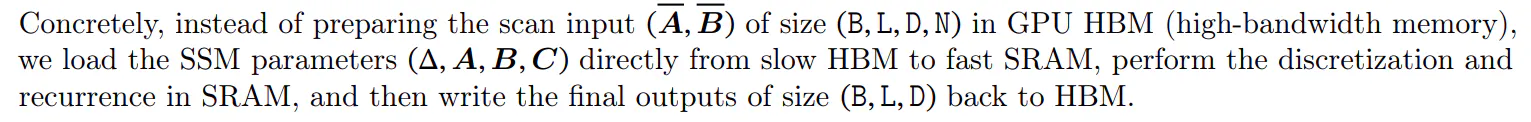
To avoid the sequential recurrence, we observe that despite not being linear it can still be parallelized with a work-efficient parallel scan algorithm (Blelloch 1990; Martin and Cundy 2018; Smith, Warrington, and Linderman 2023).
Finally, we must also avoid saving the intermediate states, which are necessary for backpropagation. We carefully apply the classic technique of recomputation to reduce the memory requirements: the intermediate states are not stored but recomputed in the backward pass when the inputs are loaded from HBM to SRAM. As a result, the fused selective scan layer has the same memory requirements as an optimized transformer implementation with FlashAttention.
Details of the fused kernel and recomputation are in Appendix D. The full Selective SSM layer and algorithm is illustrated in Figure 1.






{kind=link}