Authors:
(1) Albert Gu, Machine Learning Department, Carnegie Mellon University and with equal contribution;
(2) Tri Dao, Department of Computer Science, Princeton University and with equal contribution.
Table of Links
Abstract and 1 Introduction
2 State Space Models
3 Selective State Space Models and 3.1 Motivation: Selection as a Means of Compression
3.2 Improving SSMs with Selection
3.3 Efficient Implementation of Selective SSMs
3.4 A Simplified SSM Architecture
3.5 Properties of Selection Mechanisms
3.6 Additional Model Details
4 Empirical Evaluation and 4.1 Synthetic Tasks
4.2 Language Modeling
4.3 DNA Modeling
4.4 Audio Modeling and Generation
4.5 Speed and Memory Benchmarks
4.6 Model Ablations
5 Discussion
6 Conclusion and References
A Discussion: Selection Mechanism
B Related Work
C Mechanics of Selective SSMs
D Hardware-aware Algorithm For Selective SSMs
E Experimental Details and Additional Results
4 Empirical Evaluation
In Section 4.1 we test Mamba’s ability to solve the two synthetic tasks motivated in Section 3.1. We then evaluate on three domains, each evaluated on autoregressive pretraining as well as downstream tasks.
• Section 4.2: language model pretraining (scaling laws), and zero-shot downstream evaluation.
• Section 4.3: DNA sequence pretraining, and fine-tuning on a long-sequence classification task.
• Section 4.4: audio waveform pretraining, and the quality of autoregressively generated speech clips.
Finally, Section 4.5 shows Mamba’s computational efficiency at both training and inference time, and Section 4.6 ablates various components of the architecture and selective SSMs.
4.1 Synthetic Tasks
Full experiment details for these tasks including task details and training protocol are in Appendix E.1.
4.1.1 Selective Copying
The Copying task is one of the most well-studied synthetic tasks for sequence modeling, originally designed to test the memorization abilities of recurrent models. As discussed in Section 3.1, LTI SSMs (linear recurrences and global convolutions) can easily solve this task by only keeping track of time instead of reasoning about the data; for example, by constructing a convolution kernel of exactly the right length (Figure 2). This was explicitly validated in earlier work on global convolutions (Romero et al. 2021). The Selective Copying task prevents this shortcut by randomizing the spacing between tokens. Note that this task has been introduced before as the Denoising task (Jing et al. 2019).
Note that many previous works argue that adding architecture gating (multiplicative interactions) can endow models with “data-dependence” and solve related tasks (Dao, Fu, Saab, et al. 2023; Poli et al. 2023). However, we find this explanation insufficient intuitively because such gating does not interact along the sequence axis, and cannot affect the spacing between tokens. In particular architecture gating is not an instance of a selection mechanism (Appendix A).
Table 1 confirms that gated architectures such as H3 and Mamba only partially improve performance, while the selection mechanism (modifying S4 to S6) easily solves this task, particularly when combined with these more powerful architectures.




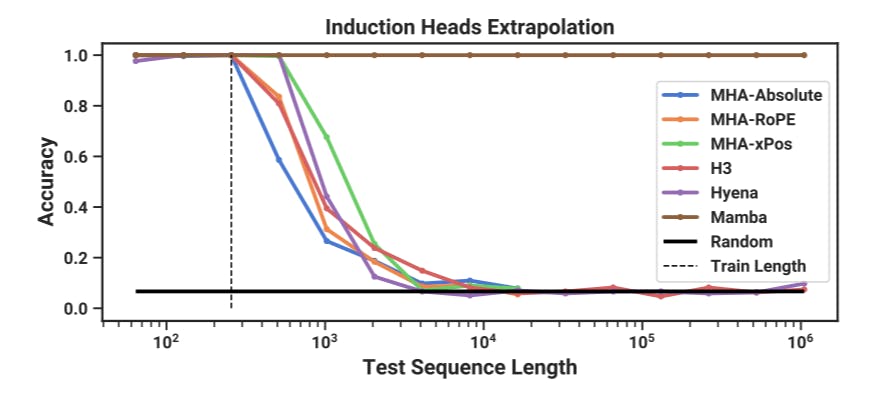
4.1.2 Induction Heads
Induction heads (Olsson et al. 2022) is a simple task from the mechanistic interpretability lens (Elhage et al. 2021) that is surprisingly predictive of the in-context learning ability of LLMs. It requires models to perform associative recall and copy: for example, if the model has seen a bigram such as “Harry Potter” in the sequence, then the next time “Harry” appears in the same sequence, the model should be able to predict “Potter” by copying from history.


Models. Following established work on induction heads, we use 2 layer models, which allows attention to mechanistically solve the induction heads task (Olsson et al. 2022). We test both multi-head attention (8 heads, with various positional encodings) and SSM variants. We use a model dimension D of 64 for Mamba and 128 for the other models.
Results. Table 2 shows that Mamba—or more precisely, its selective SSM layer—has the ability to solve the task perfectly because of its ability to selectively remember the relevant token while ignoring everything else in between. It generalizes perfectly to million-length sequences, or 4000× longer than it saw during training, while no other method goes beyond 2×.







{kind=link}