Authors:
(1) Dan Kondratyuk, Google Research and with Equal contribution;
(2) Lijun Yu, Google Research, Carnegie Mellon University and with Equal contribution;
(3) Xiuye Gu, Google Research and with Equal contribution;
(4) Jose Lezama, Google Research and with Equal contribution;
(5) Jonathan Huang, Google Research and with Equal contribution;
(6) Grant Schindler, Google Research;
(7) Rachel Hornung, Google Research;
(8) Vighnesh Birodkar, Google Research;
(9) Jimmy Yan, Google Research;
(10) Krishna Somandepalli, Google Research;
(11) Hassan Akbari, Google Research;
(12) Yair Alon, Google Research;
(13) Yong Cheng, Google DeepMind;
(14) Josh Dillon, Google Research;
(15) Agrim Gupta, Google Research;
(16) Meera Hahn, Google Research;
(17) Anja Hauth, Google Research;
(18) David Hendon, Google Research;
(19) Alonso Martinez, Google Research;
(20) David Minnen, Google Research;
(21) Mikhail Sirotenko, Google Research;
(22) Kihyuk Sohn, Google Research;
(23) Xuan Yang, Google Research;
(24) Hartwig Adam, Google Research;
(25) Ming-Hsuan Yang, Google Research;
(26) Irfan Essa, Google Research;
(27) Huisheng Wang, Google Research;
(28) David A. Ross, Google Research;
(29) Bryan Seybold, Google Research and with Equal contribution;
(30) Lu Jiang, Google Research and with Equal contribution.
Table of Links
Abstract and 1 Introduction
2. Related Work
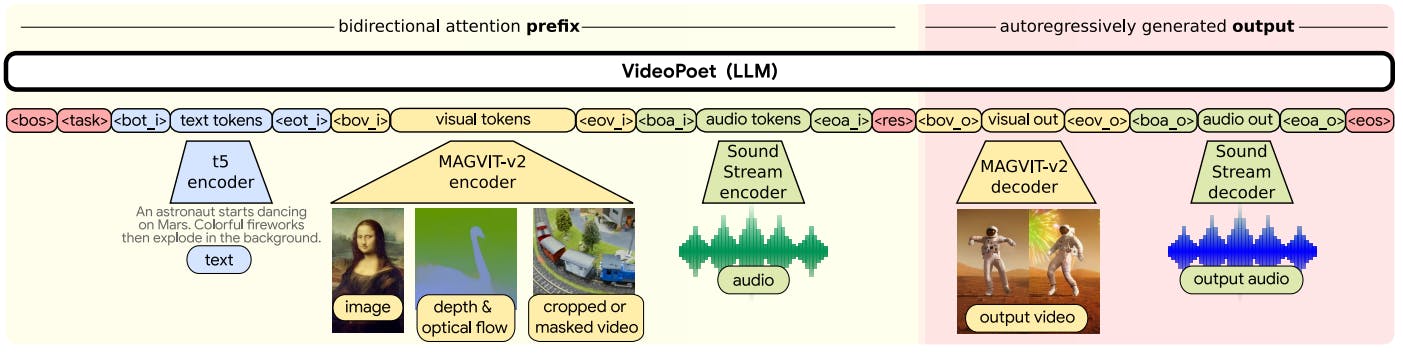
3. Model Overview and 3.1. Tokenization
3.2. Language Model Backbone and 3.3. Super-Resolution
4. LLM Pretraining for Generation
4.1. Task Prompt Design
4.2. Training Strategy
5. Experiments
5.1. Experimental Setup
5.2. Pretraining Task Analysis
5.3. Comparison with the State-of-the-Art
5.4. LLM’s Diverse Capabilities in Video Generation and 5.5. Limitations
6. Conclusion, Acknowledgements, and References
A. Appendix
Video diffusion models. Recently, numerous video generation methods use diffusion-based methods for text-to video (Ho et al., 2022a; Blattmann et al., 2023b; Zhang et al., 2023a; Blattmann et al., 2023a; He et al., 2023; Zhou et al., 2022; Wang et al., 2023a; Ge et al., 2023; Wang et al., 2023d;c; Singer et al., 2022; Zhang et al., 2023a; Zeng et al., 2023) and video-to-video editing (Liew et al., 2023; Feng et al., 2023; Esser et al., 2023; Chen et al., 2023b). As video diffusion models are usually derived from text-to-image diffusion models (Ramesh et al., 2021; Saharia et al., 2022), additional tasks and modalities are added via inference tricks (Meng et al., 2021), architectural changes (Esser et al., 2023; Liew et al., 2023) and adapter layers (Zhang et al., 2023b; Guo et al., 2023). Although these models are composable after training, they are not trained end-to-end in a unified framework. Our multitask pretraining strategy in a single model improves performance and provides zero-shot video generation capabilities.
Language models for video and image generation. Video language models are typically derived from the general family of transformer-based language models (Vaswani et al., 2017; Raffel et al., 2020) that easily combine multiple tasks in pretraining and demonstrate powerful zero-shot capabilities. Image generation language models can generate images autoregressively (Yu et al., 2022) or via masked prediction (Chang et al., 2022; 2023). Both families have


been extended to text-to-video (Hong et al., 2022; Villegas et al., 2022; Hu et al., 2023; Yan et al., 2021) using paired data. While other text-to-video work with transformers only leverages video-text pairs for training, we also leverage unpaired videos (without text) and the same video for different tasks. Since video language models can flexibly incorporate numerous tasks (Yu et al., 2023a; Nash et al., 2022), including video-to-video, we extend this family of work to text- and multimodal-conditioned tasks in this work with a synergistic pretraining strategy across various tasks.
Pretraining task design in LLMs. As language models can easily incorporate multiple training tasks, task selection is an important area of research. GPT-3 (Brown et al., 2020) and PaLM (Chowdhery et al., 2022) demonstrate that training LLMs on diverse tasks leads to positive scaling effects on zero- and few-shot tasks. Other approaches show that masking approaches are a valuable learning target (Hoffmann et al., 2022; Yu et al., 2023a;c). As the model size grows, training data must grow as well (Hoffmann et al., 2022) to maintain similar performance. Our pretraining strategy enables using the same video for multiple training tasks even without paired text. This design facilitates training on a large quantity of video-only examples, thereby decreasing the demand for video-text pairs.






{kind=link}