Table of Links
Abstract and 1 Introduction
2 LongFact: Using LLMs to generate a multi-topic benchmark for long-form factuality
3 Safe:LLM agents as factuality autoraters
4 LLMs agents can be better factuality annotators than humans
5 F1@k: Extending F1 with recall from human-preferred length
6 Larger LLMs are more factual
7 Related Work
8 Limitations
9 Conclusion, Acknowledgments, Author Contribution, and References
Appendix
A. Frequently asked questions
B. LongFact details
C. SAFE details
D. Metric details
E. Further analysis
D METRIC DETAILS
D METRIC DETAILS
Our implementation of F1@K assumes that a given model response does not contain repeated facts, as F1@K does not account for the possibility of a model attempting to maximize its score by continuously repeating a supported fact. We therefore operate under the assumption that each individual fact in a model response should be distinct, which we posit is a reasonable assumption in practice for the following reasons.
First, the language models that we benchmarked in Section 6 did not exhibit any cases of repeating the same information to maximize response length, which indicates that in many practical settings, this assumption is already fulfilled. Second, we contend that repeating information is better measured by other metrics such as fluency or usefulness of model responses. This is because a model response that repeats a single supported fact (e.g., “The Eiffel Tower is a tower.”) to score highly on F1@K is indeed, from the perspective of factuality evaluation, very factual. The response is not helpful for a user, however, because the user only learns a single piece of information.
D.2 CASE ANALYSIS
Here, we discuss how F1@K accounts for several examples of hypothetical model responses where one set of model responses is clearly more factual than the other. In these cases, we assume that the evaluation method functions perfectly and instead focus on analyzing how F1@K aggregates the raw metrics from the evaluator into a single number. Case 1 shows the need to measure precision, Case 2 shows the need to measure recall, and Case 3 shows how nonfactual responses are equally rated.
Case 3. A model response that solely contains one-hundred not-supported facts should be equally factual as a model response that comprises a singular not-supported fact because both responses fail to provide any factual information. The outputted raw metrics for the model response with onehundred not-supported facts should be zero supported facts, zero irrelevant facts, and one-hundred not-supported facts, which yields an F1 of 0. The outputted raw metrics for the model response with a single not-supported fact should be zero supported facts, zero irrelevant facts, and one not-supported fact, which also yields an F1 of 0. So we see that F1@K expectedly identifies that these two responses are equally not factual.
D.3 SELECTING K
As shown in Section 5, F1@K requires setting a hyperparameter K, which represents the number of supported facts required for a response to achieve full recall. Intuitively, F1@K evaluates a response’s factuality for a user who is indifferent to having additional supported facts after the Kth supported fact, and the choice of K can thus be viewed as a choice in how one models the preferences of end users.[23] Because the responses of large language models have been tuned towards human preferences, in Section 6 we choose to report F1@K for K = 64, the median number of relevant facts among all model responses. On the other hand, one may also wish to measure long-form factually with a metric that continues to increase with each additional supported fact. We thus also present results in Section 6 for K = 178, the maximum number of relevant facts among tested model responses. Additionally, we showed model performance with other K values in Appendix E.3.

Thus, we see that for sufficiently-large K, F1@K ranks responses in increasing order of the number of supported facts in the response.
Finally, we show how K can be set to encourage a model to completely fill its response with supported facts. Consider a language model whose maximum output length is T tokens. Let W represent the average number of words contained in a token generated by this language model. We can generate responses from the language model on a large number of long-form factuality questions (e.g., all prompts in LongFact) and use SAFE to compute the number of facts in each response. Combined with calculating the number of words in each response, we can estimate the average number of facts per word in a generated response F. Next, we can approximate the maximum number of facts that the model can fit in its output sequence length as T × W × F. Computing F1 at K = T × W × F thereby only allows a response to achieve a score of 1 when it contains as many supported facts as can be fit in the output sequence length and when all provided facts are supported.
D.4 FACTUAL PRECISION–RECALL CURVES
In Section 6, we use SAFE to verify and score model response on LongFact-Objects, and we aggregate a response’s factual precision and recall via F1@K for various choice of K. The prompts used to evaluate these models, however, do not provide any information on the desired response length, so the results in Section 6 can be viewed as measuring the “default behavior” of models. While it is important to evaluate this default behavior, a language model is also capable of generating a variety of responses to a question given different instructions. Thus, this section investigates long-form factuality when considering the impact of instructions that control the response length.
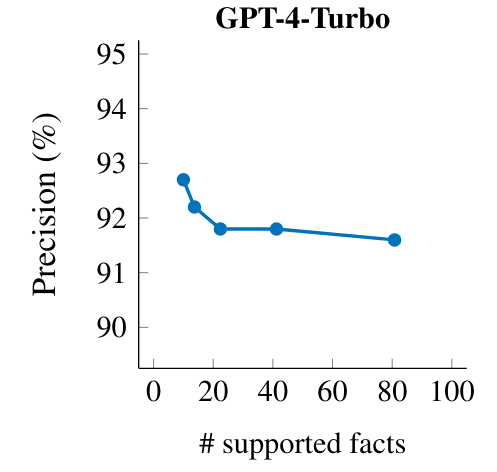
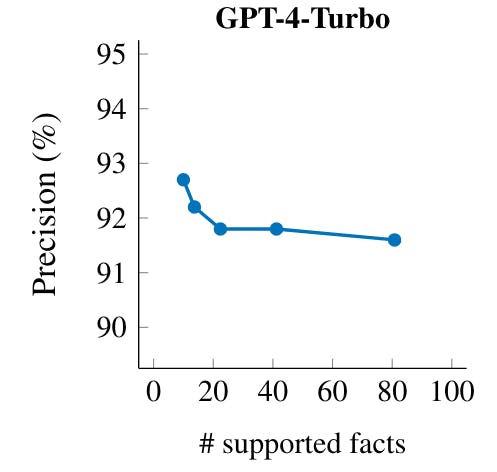
We investigate the behavior of GPT-4-Turbo by generating responses on the same prompt set used in Section 6 and adding the instruction “Respond in N sentences.” (or “Respond in 1 sentence.” if N = 1) to roughly[25] control the length of responses.[26] We do this for N ∈ {1, 2, 4, 8, 16}. Table 24 shows an example prompt with model responses corresponding to each N that we used. For the model responses from each N, we evaluate the precision as defined in Section 5 and the recall as the number of supported facts.
As shown in Figure 12, a response’s precision is higher when the language model is prompted for shorter responses, which matches the intuition that it is easier to only provide supported facts when providing a shorter response. As we instruct the model to give longer responses, we see an increase in factual recall (i.e., the number of supported facts), but also a larger proportion of factual errors (i.e., lower precision). In other words, one can trade-off between precision and recall in long-form factuality by varying the response length. This mirrors the precision–recall trade-off in a traditional classification setting where the classification threshold is varied. Considering that a model’s factual precision–recall curve allows for evaluating its long-form factuality with respect to response length, future work may explore how to apply this metric to measure a model’s long-form factuality.

:::info
This paper is available on arxiv under CC by 4.0 Deed license.
:::
[23] K must be positive, which naturally follows the intuition that when asking a long-form factuality question, a user expects to receive at least one supported fact in response.
[24] This rescaling does not change the relative ranking of responses by our metric.
[25] We fix response length using sentences rather than individual facts because we did not want to add complexity to this instruction by explaining our definition of an individual fact.
[26] This method of controlling the response length only works for language models that have strong instruction following capabilities, as is the case with GPT-4-Turbo.
:::info
Authors:
(1) Jerry Wei, Google DeepMind and a Lead contributors;
(2) Chengrun Yang, Google DeepMind and a Lead contributors;
(3) Xinying Song, Google DeepMind and a Lead contributors;
(4) Yifeng Lu, Google DeepMind and a Lead contributors;
(5) Nathan Hu, Google DeepMind and Stanford University;
(6) Jie Huang, Google DeepMind and University of Illinois at Urbana-Champaign;
(7) Dustin Tran, Google DeepMind;
(8) Daiyi Peng, Google DeepMind;
(9) Ruibo Liu, Google DeepMind;
(10) Da Huang, Google DeepMind;
(11) Cosmo Du, Google DeepMind;
(12) Quoc V. Le, Google DeepMind.
:::







{kind=link}