
LangChain has rapidly become a go-to framework for building powerful applications leveraging Large Language Models (LLMs). While LLMs excel at understanding human language, accessing the vast amounts of structured data locked away in SQL databases typically requires specialized query knowledge. This raises a key question: how can we empower more users to interact with databases, such as MySQL, using simple, natural language?
This article chronicles my practical journey using LangChain to build exactly that — a natural language interface capable of querying a MySQL database. I’ll share the steps involved in setting up the system using Docker, the inevitable hurdles encountered (including managing LLM token limits, ensuring sensitive data privacy, and handling ambiguous prompts), and the multi-step, multi-LLM solutions I developed. Follow along to explore the challenges and successes of bringing conversational AI to relational databases.
The entirety of the Python code implementing the natural language querying tool discussed here was generated with the assistance of AI models, primarily ChatGPT and Gemini. My role involved defining the requirements, structuring the prompts, reviewing and evaluating the generated code for functionality and potential issues, guiding the AI through necessary revisions, integrating the various components, and performing the crucial testing and debugging phases.
Step 1: Establishing the Foundation with Docker
- The Goal: Create a stable, isolated multi-container environment.
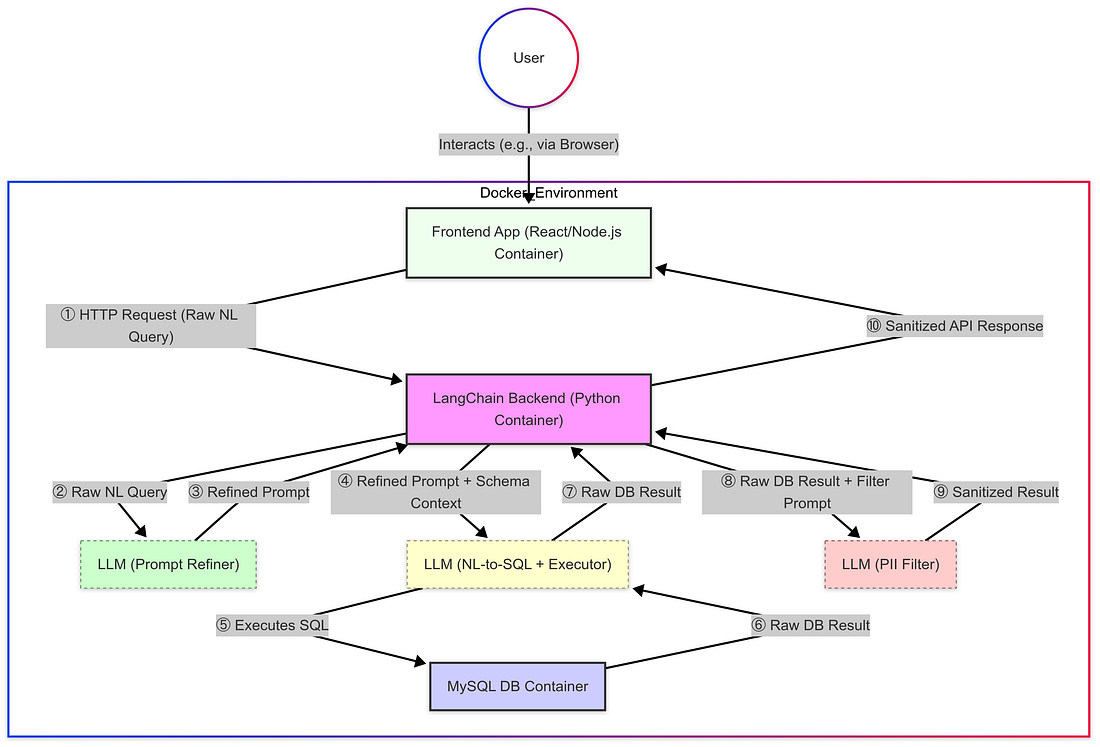
- The Method: My first practical step was to create a reliable and reproducible environment using Docker. The architecture involved three distinct containers: one running the Frontend application (React/Node.js), one for the Backend service (Python with LangChain), and another dedicated to the MySQL database instance. This containerized approach became necessary after encountering frustrating difficulties installing the required Python libraries locally due to dependency conflicts and platform incompatibilities.
- Setup Details: Using Docker provided a clean slate. Leveraging AI assistance helped accelerate the creation of the
Dockerfiles anddocker-compose.ymlneeded to define these three services and their dependencies (like Python, LangChain, Node.js, MySQL connector). Critical configuration included setting up Docker networking for necessary inter-container communication (e.g., allowing the Frontend to talk to the Backend) and securely handling database credentials using environment variables. - Outcome & Transition: Once running, the containers could communicate appropriately, providing the necessary infrastructure. With this foundation established, the following steps will zoom in specifically on the architecture design and challenges encountered within the Backend Python service, as this is where the core LangChain logic, LLM orchestration, and data processing pipeline were implemented.


Step 2: First Queries and the Schema Size Challenge
- Initial Success: The containerized setup worked, enabling successful natural language queries against the database. Simple requests yielded correct query logic and data via LangChain and the primary LLM.
- The Challenge: Token Limits: However, a major bottleneck quickly emerged: API errors due to exceeding token limits. This happened because the context provided to the LLM often includes database schema details (table/column names, types), and with hundreds of tables, this schema information made the prompts too large for the LLM’s limits.
- The Workaround: Subsetting: My immediate solution was to restrict the schema information provided to the LLM, perhaps by only considering a small, manually defined subset of the database tables or using parameters like
top_k=1if applicable to the LangChain component handling schema representation. This significantly reduced prompt size and avoided the errors for queries within that subset. - Limitations: While functional, this is a brittle fix. The LLM remains unaware of tables outside this limited view, preventing more complex queries and requiring manual updates. This clearly indicated that handling large database schemas efficiently requires a more advanced approach.


Step 3: Implementing PII/PHI Filtering via a Dedicated LLM Prompt
- The Critical Need for Compliance: After enabling basic queries, the next priority was data privacy compliance. For companies, particularly in regulated sectors like healthcare and banking, filtering sensitive PII/PHI is often a strict legal requirement (e.g., due to HIPAA or financial regulations) needed to avoid severe penalties. Exposing raw data also breaks customer trust, harms reputation, and violates internal security and ethics. Robust filtering before displaying results was therefore essential to meet these compliance needs, especially for wider team access.
- The Solution: A “Data Security Bot”: My approach involved adding a dedicated data sanitization layer… (the rest of the paragraph describing the LLM filter implementation remains the same)
- Filtering Logic: Inside, a detailed prompt (
get_sanitize_prompt) instructed this second LLM to act as a “data privacy filter.” Its primary task was to review the raw text response and redact identified PHI and PII.


- Example: A result like
{'member_id': 12345, 'member_name': 'Jane Doe', 'address': '123 Main Street, Mercy City'}would be transformed by the filter LLM to{'member_id': 12345, 'member_name': '[REDACTED]', 'address': '[REDACTED]'}.
Here is the entire diagram after the change


Step 4: Refining Prompts for Raw SQL Generation
- The Challenge: Misinterpretation: After implementing the PII filter, I tackled the challenge of ensuring the main NL-to-SQL LLM (
MainLLM) accurately understood the user’s intent before executing potentially complex or ambiguous queries against the database. Vague prompts could leadMainLLMto execute incorrect SQL, retrieve irrelevant data, or fail. - The Solution: A “Prompt Refinement Bot”: To improve execution reliability, I introduced a preliminary “Prompt Refinement Bot” — a third LLM call. This bot acted as an “expert prompt engineer,” taking the original user query and database schema to rewrite the request into a highly explicit and unambiguous instruction for the
MainLLM. - Goal of Refinement: The goal was to formulate a prompt that clearly guided
MainLLMon what tables, columns, and conditions were needed, maximizing the chance it would execute the correct query against the database and retrieve the intended data. - Outcome: This pre-processing step significantly improved the consistency and accuracy of the data retrieved by
MainLLM.

Step 5: Enhancing Context with Conversation Memory
- The Need: To elevate the user experience beyond single queries and enable more natural dialogue, remembering the conversation context was crucial for handling follow-up questions.
- The Implementation: I integrated LangChain’s memory capabilities using
ConversationSummaryMemory. This approach uses an LLM (gpt-3.5-turboin this case) to progressively summarize the conversation, keeping key context accessible while managing token usage (configured withmax_token_limit=500). - Integration: This summarized
{history}was then incorporated directly into the prompt template used when interacting with theMainLLM(the NL-to-SQL + Executor), alongside the user’s current (potentially refined){query}. - Benefit: Adding this memory layer allowed the system to consider the ongoing dialogue, significantly improving usability for more coherent and context-aware conversations about the database contents.
Conclusion: Lessons from Building a Multi-LLM SQL Interface
Building this natural language interface to MySQL using LangChain was a revealing journey into the power and complexities of modern AI development. What started as a goal to query a database using plain English evolved into a multi-stage pipeline involving three distinct LLM calls: one for refining user prompts, one for translating natural language to SQL and executing it directly against the database, and a critical third one for filtering sensitive PII/PHI from the results. Integrating conversation memory further enhanced the usability, allowing for more natural, context-aware interactions.
Key challenges like managing LLM token limits with large schemas, ensuring data privacy through filtering, and improving prompt understanding required iterative solutions. While leveraging AI for code generation accelerated parts of the process, designing the overall architecture, implementing specific logic like the PII filter exceptions, integrating components, and rigorous testing remained crucial human-driven tasks.
Next Steps: Exploring Retrieval-Augmented Generation (RAG)
The success rate, especially for more complex or ambiguous queries, indicates clear opportunities for improvement beyond the current prompt engineering and filtering techniques.
One promising avenue I plan to explore next to further boost accuracy is Retrieval-Augmented Generation (RAG). Instead of solely relying on the LLM’s internal knowledge or a static view of the schema, RAG introduces a dynamic retrieval step. Before generating the SQL, a RAG system would search a specialized knowledge base for information highly relevant to the user’s current query.
In this NL-to-SQL context, this could involve retrieving:
- Detailed descriptions or documentation for the specific database tables and columns deemed most relevant to the query.
- Examples of similar natural language questions previously mapped to their correct SQL counterparts.
- Relevant business rules or definitions pertaining to the data requested.
This retrieved, targeted information would then be added (“augmented”) to the prompt sent to the main NL-to-SQL LLM (MainLLM), providing it with richer, just-in-time context. The hypothesis is that this dynamic context will significantly enhance the LLM’s understanding and ability to generate accurate SQL, potentially offering substantial improvements without the extensive dataset requirements of fine-tuning. Implementing and evaluating an effective RAG strategy represents the next exciting phase in enhancing this conversational database interface.






{kind=link}