Table of Links
Abstract and 1 Introduction
2 COCOGEN: Representing Commonsense structures with code and 2.1 Converting (T,G) into Python code
2.2 Few-shot prompting for generating G
3 Evaluation and 3.1 Experimental setup
3.2 Script generation: PROSCRIPT
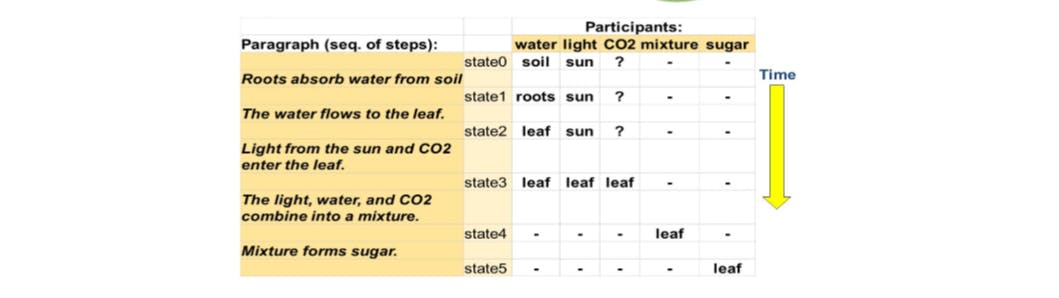
3.3 Entity state tracking: PROPARA
3.4 Argument graph generation: EXPLAGRAPHS
4 Analysis
5 Related work
6 Conclusion, Acknowledgments, Limitations, and References
A Few-shot models size estimates
B Dynamic prompt Creation
C Human Evaluation
D Dataset statistics
E Sample outputs
F Prompts
G Designing Python class for a structured task
H Impact of Model size
I Variation in prompts
4 Analysis


Structured Prompts vs. Code-LLMs Which component is more important, using a Code-LLMs or the structured formatting of the input as code? To answer this, we experimented with a text prompt with a Code-LLM CODEX, and a code prompt with an NL-LLM, DAVINCI. Table 5 shows that both contributions are indeed important: performance


improves for the NL-LLM DAVINCI both when we use a code prompt, and when we use a Code-LLM. However when using both a Code-LLM and a code prompt – the improvement is greater than the sum of each of these solely.




The results indicate that the efficacy of dynamic prompts depends on both the training data and task. In the edge-prediction sub-task of PROSCRIPT, edges between events in similar scripts are helpful, and Table 6 shows that the model was able to effectively leverage this information. In the script generation sub-task of PROSCRIPT, Table 8 shows that KST provides gains as well (Appendix B).
In EXPLAGRAPHS, we observed that the training data had multiple examples which were nearly identical, and thus dynamically created prompts often included such duplicate examples, effectively reducing diversity and prompt size (Table 9).
Python Formatting We performed an extensive study of the effect of the Python format on the downstream task performance in Appendix G. We find that: (i) there are no clear task-agnostic Python class designs that work uniformly well; and that (ii) larger models are less sensitive to prompt (Python class) design. In general, our approach benefits the most from code formats that as similar as possible to the conventions of typical code.
Human evaluation We conduct human evaluation of the graphs generated by COCOGEN and DAVINCI to supplement automated metrics. The results (Appendix C) indicate that human evaluation is closely correlated with the automated metrics: for EXPLAGRAPHS, graphs generated by COCOGEN are found to be more relevant and correct. For PROSCRIPT generation, both DAVINCI and COCOGEN have complementary strengths, but COCOGEN is generally better in terms of relevance.
Authors:
(1) Aman Madaan, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]);
(2) Shuyan Zhou, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]);
(3) Uri Alon, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]);
(4) Yiming Yang, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]);
(5) Graham Neubig, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]).







{kind=link}