Table of Links
Abstract and 1 Introduction
2 Pre-Training
2.1 Tokenization
2.2 Pre-Training Data
2.3 Stability
2.4 Inference
3 Alignment and 3.1 Data
3.2 Fine-Tuning Strategy
4 Human Evaluations and Safety Testing, and 4.1 Prompts for Evaluation
4.2 Baselines and Evaluations
4.3 Inter-annotator Agreement
4.4 Safety Testing
4.5 Discussion
5 Benchmark Evaluations and 5.1 Text
5.2 Image-To-Text
6 Related Work
7 Conclusion, Acknowledgements, Contributors, and References
Appendix
A. Samples
B. Additional Information of Human Evaluations
4 Human Evaluations and Safety Testing
Chameleon has significant new mixed modal understanding and generation abilities that cannot be measured with existing benchmarks. In this section, we detail how we conduct human evaluations on large multi-modal language models’ responses to a set of diverse prompts that regular users may ask daily. We first introduce how we collect the prompts and then describe our baselines and evaluation methods, along with the evaluation results and analysis. A safety study is also included in this section.
4.1 Prompts for Evaluation
We work with a third-party crowdsourcing vendor to collect a set of diverse and natural prompts from human annotators. Specifically, we ask annotators to creatively think about what they want a multi-modal model to generate for different real-life scenarios. For example, for the scenario of “imagine you are in a kitchen”, annotators may come up with prompts like “How to cook pasta?” or “How should I design the layout of my island? Show me some examples.” The prompts can be text-only or text with some images, and the expected responses should be mixed-modal, containing both text and images.
After collecting an initial set of prompts, we ask three random annotators to evaluate whether the prompts are clear and whether they expect the responses to contain images. We use a majority vote to filter unclear prompts and prompts that don’t expect mixed-modal responses. In the end, our final evaluation set contains 1,048 prompts: 441 (42.1%) are mixed-modal (i.e., containing both text and images), and the remaining 607 (57.9%) are text-only.
To better understand the tasks users would like a multi-modal AI system to fulfill, we manually examine


the prompts and classify them into 12 categories. The description of these task categories[1], as well as their example prompts, can be found in Figure 8.
4.2 Baselines and Evaluations
We compare Chameleon 34B with OpenAI GPT-4V and Google Gemini Pro by calling their APIs. While these models can take mixed-modal prompts as input, their responses are text-only. We create additional baselines by augmenting GPT-4V and Gemini responses with images to have even stronger baselines. Specifically, we instruct these models to generate image captions by adding the following sentence at the end of each original input prompt: “If the question requires an image to be generated, then generate an image caption instead and enclose the caption in a pair of ⟨caption⟩ ⟨/caption⟩ tags.” We then use OpenAI DALL-E 3 to generate images conditioned on these captions and replace the captions in the original responses with those generated images. We denote the enhanced responses as GPT-4V+ and Gemini+ in this section. Working with the same third-party crowdsourcing vendor, we conduct two types of evaluations to measure the model performance: absolute and relative.
4.2.1 Absolute Evaluation
For absolute evaluations, the output of each model is judged separately by asking three different annotators a set of questions regarding the relevance and quality of the responses. Below, we give detailed results and analysis on the most critical question, whether the response fulfills the task described in the prompt.
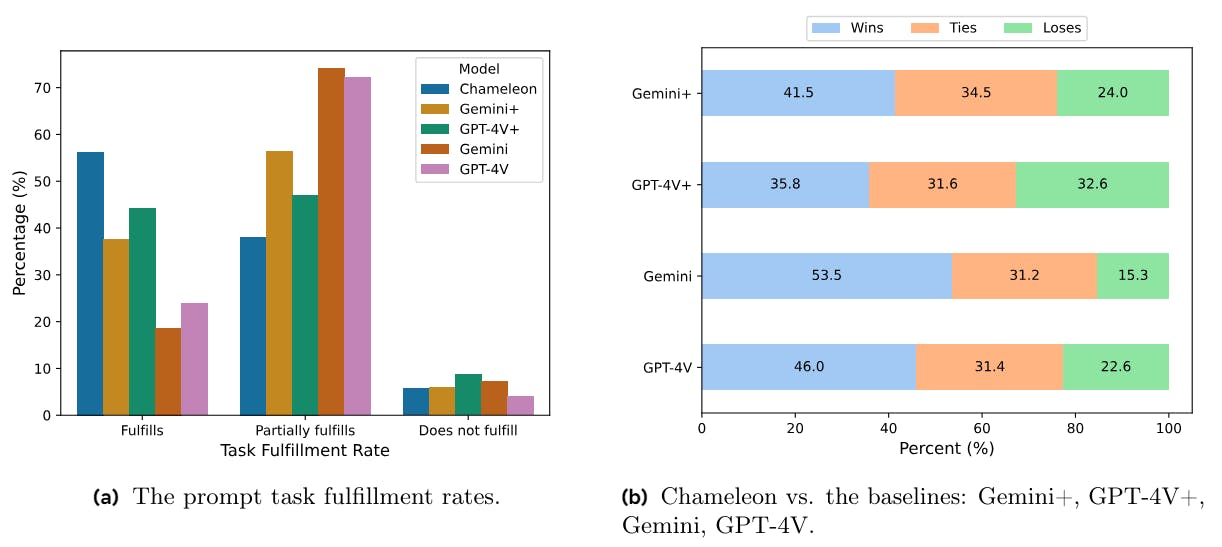
On task fulfillment, we ask annotators whether the response fulfills, partially fulfills, or does not fulfill the task described in the prompt. As shown in Figure 9a, much more of Chameleon’s responses are considered to have completely fulfilled the tasks: 55.2% for Chameleon vs. 37.6% of Gemini+ and 44.7% of GPT-4V+. When judging the original responses of Gemini and GPT-4V, the annotators consider much fewer prompts to be fully fulfilled: Gemini completely fulfills 17.6% of the tasks and GPT-4V 23.1%. We suspect that because all the prompts expect mixed-modal output, the text-only responses from Gemini and GPT-4V might be viewed as only partially completing the tasks by the annotators.
The task fulfillment rates in each category and in each input modality can be found in Appendix B. The task categories that Chameleon performs well include Brainstorming, Comparison, and Hypothetical, and the categories Chameleon needs to improve include Identification and Reasoning. On the other hand, we don’t see that the model performance differs a lot when comparing mixed-modality and text-only prompts, although Chameleon seems to perform slightly better on text-only prompts, while Gemini+ and GPT-4V+ are slightly better on mixed-modal ones. Figure 2 shows an example of Chameleon’s response to a brainstorming prompt.
4.2.2 Relative Evaluation
For relative evaluations, we directly compare Chameleon with each baseline model by presenting their responses to the same prompt in random order and asking human annotators which response they prefer. The options include the first response, the second response, and about the same. Figure 9b shows Chameleon’s win rates[2] over the baselines. Compared with Gemini+, Chameleon’s responses are better in 41.5% of the cases, 34.5% are tie, and 24.0% are inferior. Annotators also think that Chameleon’s responses are slightly more often better than GPT-4V+, with 35.8% win, 31.6% tie, and 32.6% loss. Overall, Chameleon has win rates of 60.4% and 51.6% over Gemini+ and GPT-4V+, respectively. When compared with the original responses from Gemini without the augmented images, Chameleon’s responses are considered better in 53.5% of the cases, 31.2% are tied, and 15.3% are inferior. Chameleon’s responses are also considered better than GPT-4V more frequently, with 46.0% win, 31.4% tie, and 22.6% loss. Chameleon’s win rates over Gemini and GPT-4V are 69.1% and 61.7%, respectively.
Author:
(1) Chameleon Team, FAIR at Meta.
[1] While not instructed specifically, certain image understanding tasks that require identifying the text in an image, such as OCR (Optical character recognition), do not appear in our evaluation set of prompts.







{kind=link}