
Table of Links
Abstract and 1 Introduction
2 Approach
2.1 Architecture
2.2 Multimodal Instruction Finetuning
2.3 Curriculum Learning with Parameter Efficient Finetuning
3 Experiments
4 Results
4.1 Evaluation of SpeechVerse models
4.2 Generalization Across Instructions
4.3 Strategies for Improving Performance
5 Related Work
6 Conclusion, Limitations, Ethics Statement, and References
A Appendix
A.1 Audio Encoder Pre-training
A.2 Hyper-parameters
A.3 Tasks
3 Experiments
3.1 Tasks
In this work, we use a large collection of publicly available speech datasets from a diverse set of tasks. A summary of the datasets and evaluation metrics for these tasks is provided in the Table 1, while examples and prompts are covered in the Table 10. Our training tasks include automatic speech recognition (ASR), five spoken language understanding (SLU) tasks, and five paralinguistic speech processing (PSP) tasks. The SLU tasks include those tasks which can be solved by a cascaded system of a ASR model and an LLM, while PSP tasks are classification tasks based on the audio, typically used in audio analytics. For the IC/SL tasks, we split the SLURP dataset into seen and unseen intent/slot label classes and study them separately to understand the generalization capabilities of the model. The KWE task is about finding important keywords from the audio, while in the KWS task, we learn to classify whether a particular keyword was present in the audio or not. The target labels were synthetically created for both these tasks using an LLM. All other tasks are standard and an interested reader can refer to the Appendix A.3 for more details. We create a list of at least 15 prompts per task describing the goal of the task. To further add diversity to the set of tasks, we use a text-to-speech (TTS) version of the Alpaca dataset [31]. This dataset contains a diverse collection of prompt, input, output tuples, where the prompt describes the task, input is the input for the task, and the output contains the target labels. However, there are no corresponding audios associated with the dataset. As in the existing work [17], we use a TTS system (AWS Polly in our case) to generate synthetic audios for the input text using a pool of 10 different speakers.
3.2 Models





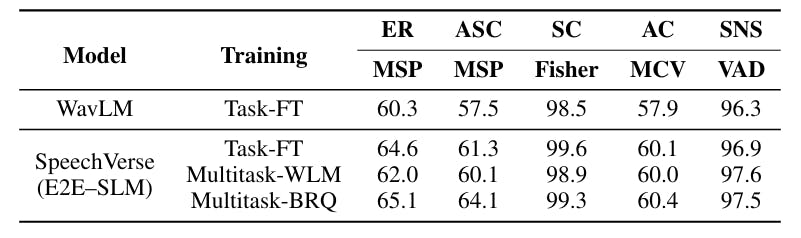
Baselines: For the SLU tasks, we compare our models with a cascaded baseline that uses an LLM on ASR hypotheses (ASR → LLM). For a fair comparison, we use a parameter-efficient fine-tuned version of Flan-T5-XL as the LLM for the baseline. The multi-task fine-tuning data is exactly the same between our models and the baseline except that the latter uses ground truth text in place of the audios. We benchmark the cascaded approach with ASR hypotheses from (1) a strong publicly available Whisper-large-v2 [20] ASR model and (2) our ASR Task-FT SpeechVerse model, enabling a true comparison between a multimodal model vs cascaded approach. Finally, we also benchmark the performance of the oracle ASR system by passing the ground truth transcripts to the baseline LLM (GT → LLM). For the KWS task, we use substring search of the keyword in ASR hypotheses as the baseline. For PSP tasks, we train task-specific classifiers that use the last layer representations from WavLM Large. The classifier contains a feed-forward layer, followed by a 2-layer Gated Recurrent Unit (GRU) with mean pooling over frames, followed by another 2 layers of feed-forward network and finally a softmax operator. These models are trained on the same task-specific data thereby allowing for direct comparison with our WavLM-based multimodal models.
Authors:
(1) Nilaksh Das, AWS AI Labs, Amazon and Equal Contributions;
(2) Saket Dingliwal, AWS AI Labs, Amazon([email protected]);
(3) Srikanth Ronanki, AWS AI Labs, Amazon;
(4) Rohit Paturi, AWS AI Labs, Amazon;
(5) Zhaocheng Huang, AWS AI Labs, Amazon;
(6) Prashant Mathur, AWS AI Labs, Amazon;
(7) Jie Yuan, AWS AI Labs, Amazon;
(8) Dhanush Bekal, AWS AI Labs, Amazon;
(9) Xing Niu, AWS AI Labs, Amazon;
(10) Sai Muralidhar Jayanthi, AWS AI Labs, Amazon;
(11) Xilai Li, AWS AI Labs, Amazon;
(12) Karel Mundnich, AWS AI Labs, Amazon;
(13) Monica Sunkara, AWS AI Labs, Amazon;
(14) Daniel Garcia-Romero, AWS AI Labs, Amazon;
(15) Kyu J. Han, AWS AI Labs, Amazon;
(16) Katrin Kirchhoff, AWS AI Labs, Amazon.




{kind=link}