Table of Links
Abstract and 1. Introduction
2 Concepts in Pretraining Data and Quantifying Frequency
3 Comparing Pretraining Frequency & “Zero-Shot” Performance and 3.1 Experimental Setup
3.2 Result: Pretraining Frequency is Predictive of “Zero-Shot” Performance
4 Stress-Testing the Concept Frequency-Performance Scaling Trend and 4.1 Controlling for Similar Samples in Pretraining and Downstream Data
4.2 Testing Generalization to Purely Synthetic Concept and Data Distributions
5 Additional Insights from Pretraining Concept Frequencies
6 Testing the Tail: Let It Wag!
7 Related Work
8 Conclusions and Open Problems, Acknowledgements, and References
Part I
Appendix
A. Concept Frequency is Predictive of Performance Across Prompting Strategies
B. Concept Frequency is Predictive of Performance Across Retrieval Metrics
C. Concept Frequency is Predictive of Performance for T2I Models
D. Concept Frequency is Predictive of Performance across Concepts only from Image and Text Domains
E. Experimental Details
F. Why and How Do We Use RAM++?
G. Details about Misalignment Degree Results
H. T2I Models: Evaluation
I. Classification Results: Let It Wag!
6 Testing the Tail: Let It Wag!
Motivation. From the previous sections, we have identified a consistent long-tailed concept distribution, highlighting the scarcity of certain concepts on the web. This observation forms the basis of our hypothesis that models are likely to underperform when tested against data distributions that are heavily long-tailed. To test this, we carefully curate 290 concepts that were identified as the least frequent across all pretraining datasets. This includes concepts like an A310 aircraft, a wormsnake, and a tropical kingbird. We then use these concepts to create a classification test set, “Let It Wag! ”.
Dataset Details. The “Let It Wag!” classification dataset comprises 130K test samples downloaded from the web using the method of Prabhu et al. [90]. The test samples are evenly distributed across 290 categories that represent long-tailed concepts. From the list of curated concepts, we download test set images, deduplicate them, remove outliers, and finally manually clean and hand-verify the labels.
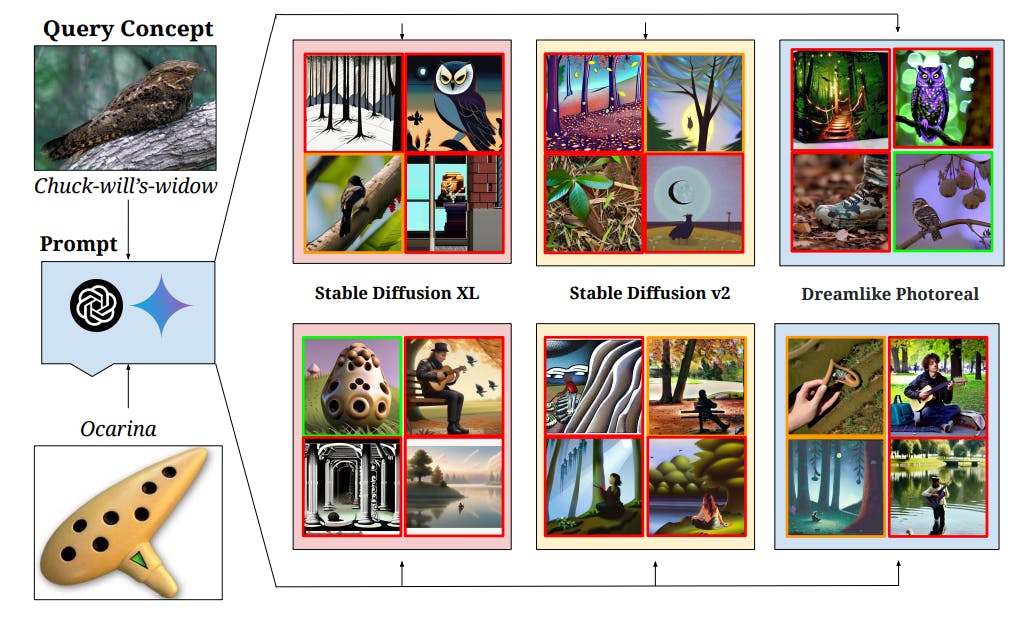
![Figure 7: Qualitative results on the “Let It Wag!” dataset categories demonstrate failure cases of state-of-the-art T2I models on long-tailed concepts. In our experiments, we create 4 text prompts for each category using Gemini [112] and GPT4 [12] which are fed to 3 Stable Diffusion [96] models. Generation with red border is incorrect, with green border is correct and with yellow border is ambiguous. We observe that despite advances in high-fidelity image generation, there is scope for improvement for such concepts.](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)
![Figure 7: Qualitative results on the “Let It Wag!” dataset categories demonstrate failure cases of state-of-the-art T2I models on long-tailed concepts. In our experiments, we create 4 text prompts for each category using Gemini [112] and GPT4 [12] which are fed to 3 Stable Diffusion [96] models. Generation with red border is incorrect, with green border is correct and with yellow border is ambiguous. We observe that despite advances in high-fidelity image generation, there is scope for improvement for such concepts.](https://hackernoon.imgix.net/images/fWZa4tUiBGemnqQfBGgCPf9594N2-sh832c5.png?auto=format&fit=max&w=3840)
Analysis Details. We ran both classification and image generation experiments on “Let It Wag!”. For classification, we assessed the performance of 40 text-image (CLIP) models on the “Let It Wag!” classification dataset, using an ensemble of 80 prompts from Radford et al. [91]. For the generative task, we utilized SD-XL [89] , SD-v2 [96], and Dreamlike-Photoreal-v2.0 [3] to generate images for the long-tailed concepts. For each model, we ran 50 diffusion steps, maintaining default settings for all other parameters.
Text-Image Classification Results. We showcase the results of our long-tailed classification task in Fig. 6—we plot results of all models on both “Let It Wag!” (y-axis) and ImageNet (x-axis). We observe that all models underperform by large margins on the long-tailed “Let It Wag!” dataset (upto 20% lower absolute accuracies compared to ImageNet). This performance drop-off generalises across all model scales and 10 different pretraining data distributions, reinforcing the notion that all web-sourced pretraining datasets are inherently constrained to be long-tailed. With that said, note that the higher capacity models (fitted line with slope=1.58 in Fig. 6) seem to be closing the gap to ImageNet performance, indicating improved performance on the long-tailed concepts.
T2I Generation Results. We provide a qualitative analysis on image generation for assessing T2I models on rare concepts in Fig. 7. For diversity, we generate prompts using Gemini [112] (top row of generated images) and GPT4 [12] (bottom row of generated images). Green borders represent correct generations, red borders represent incorrect generations and yellow borders represent ambiguous generation. While descriptive prompting generally aids in improving the quality of generated images [52], we still observe T2I models failing to comprehend and accurately represent many concepts in our “Let It Wag!” dataset. Some failure cases involve misrepresenting activities (such as Pizza Tossing or Cricket Bowling as shown in Fig. 24), generating the wrong concept (Chuck-will’s-widow as shown in Fig. 7 top), as well as not comprehending the concept at all (Ocarina in Fig. 7 bottom). We can see that Stable Diffusion models are prone to the long tail qualitatively—we also provide quantitative results in Appx. H.1.
Conclusion. Across both the classification and generation experiments, we have showcased that current multimodal models predictably underperform, regardless of their model scale or pretraining datasets. This suggests a need for better strategies for sample-efficient learning on the long-tail.
Authors:
(1) Vishaal Udandarao, Tubingen AI Center, University of Tubingen, University of Cambridge, and equal contribution;
(2) Ameya Prabhu, Tubingen AI Center, University of Tubingen, University of Oxford, and equal contribution;
(3) Adhiraj Ghosh, Tubingen AI Center, University of Tubingen;
(4) Yash Sharma, Tubingen AI Center, University of Tubingen;
(5) Philip H.S. Torr, University of Oxford;
(6) Adel Bibi, University of Oxford;
(7) Samuel Albanie, University of Cambridge and equal advising, order decided by a coin flip;
(8) Matthias Bethge, Tubingen AI Center, University of Tubingen and equal advising, order decided by a coin flip.






{kind=link}