Table of Links
Abstract and 1. Introduction
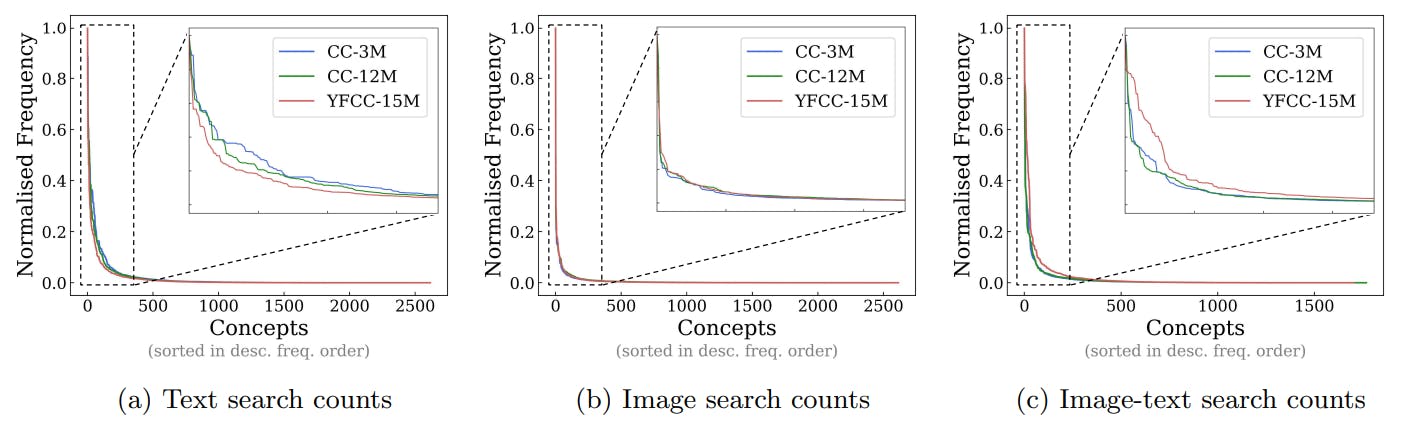
2 Concepts in Pretraining Data and Quantifying Frequency
3 Comparing Pretraining Frequency & “Zero-Shot” Performance and 3.1 Experimental Setup
3.2 Result: Pretraining Frequency is Predictive of “Zero-Shot” Performance
4 Stress-Testing the Concept Frequency-Performance Scaling Trend and 4.1 Controlling for Similar Samples in Pretraining and Downstream Data
4.2 Testing Generalization to Purely Synthetic Concept and Data Distributions
5 Additional Insights from Pretraining Concept Frequencies
6 Testing the Tail: Let It Wag!
7 Related Work
8 Conclusions and Open Problems, Acknowledgements, and References
Part I
Appendix
A. Concept Frequency is Predictive of Performance Across Prompting Strategies
B. Concept Frequency is Predictive of Performance Across Retrieval Metrics
C. Concept Frequency is Predictive of Performance for T2I Models
D. Concept Frequency is Predictive of Performance across Concepts only from Image and Text Domains
E. Experimental Details
F. Why and How Do We Use RAM++?
G. Details about Misalignment Degree Results
H. T2I Models: Evaluation
I. Classification Results: Let It Wag!
4 Stress-Testing the Concept Frequency-Performance Scaling Trend
In this section, we seek to isolate the effect of concept frequency on zero-shot performance by controlling a widely known influential factor [127, 79]: similarity in distribution between pretraining and downstream test data. Additionally, we aim to validate our hypothesis further by examining the relationship between concept frequency and downstream performance on models trained on pretraining data with synthetically controlled concept distributions, images and captions.
4.1 Controlling for Similar Samples in Pretraining and Downstream Data
Motivation. Prior work has suggested that sample-level similarity between pretraining and downstream datasets impacts model performance [62, 79, 127, 94]. This leaves open the possibility that our frequency-performance results are simply an artifact of this factor, i.e., as concept frequency increases, it is likely that the pretraining dataset also contains more similar samples to the test sets. We hence investigate whether concept frequency remains predictive of downstream performance after controlling for sample-level similarity.
Setup. We use the LAION-200M [10] dataset for this experiment. We first verified that a CLIP-ViT-B-32 model trained on LAION-200M dataset (used to study sample similarity in prior work [79]) exhibits a similar log-linear trend between concept frequency and zero-shot performance. Then, we use the near pruning method from Mayilvahanan et al. [79] to eliminate 50 million samples most similar to the test sets from the pretraining LAION-200M dataset. We provide details for this in Appx. E.1. This removes the most similar samples between pretraining and test sets. We verify that this procedure influences the performance of the model drastically in performance across our aggregate classification and retrieval tasks respectively, replicating the findings of Mayilvahanan et al. [79].
Key Finding: Concept Frequency still Predictive of Performance. We repeat our analysis on models trained with this controlled pretraining dataset with 150M samples, and report results on the same downstream classification and retrieval datasets in Fig. 4 (left). Despite the removal of the most similar samples between pretraining and test sets, we still consistently observe a clear log-linear relationship between pretraining frequency of test set concepts and zero-shot performance.
Conclusion. This analysis reaffirms that, despite removing pretraining samples closely related to the test sets, the log-linear relationship between concept frequency and zero-shot performance persists. Note that this is despite substantial decreases in absolute performance, highlighting the robustness of concept frequency as a performance indicator.


4.2 Testing Generalization to Purely Synthetic Concept and Data Distributions
Motivation. Sampling across real-world data might not result in significant differences in concept distribution, as we will later show in Sec. 5. Hence, we repeat our analysis on a synthetic dataset designed with an explicitly different concept distribution [51]. This evaluation aims to understand if pretraining concept frequency remains a significant performance predictor within a synthetic concept distribution, generalizing even on models pretrained on entirely synthetic images and captions.
Setup. The SynthCI-30M dataset [51] introduces a novel concept distribution, generating 30 million synthetic image-text pairs. Utilizing the publicly available data and models from this benchmark, we explore the relationship between concept frequency and model performance in this synthetic data regime.
Key Finding: Concept Frequency is still Predictive of Performance. We report results on models trained with their controlled dataset in Fig. 4 (right). We still consistently observe a clear log-linear relationship between concept frequency and zero-shot performance.
Conclusion. This consistency highlights that concept frequency is a robust indicator of model performance, extending even to entirely synthetically constructed datasets and pretraining concept distributions.
Authors:
(1) Vishaal Udandarao, Tubingen AI Center, University of Tubingen, University of Cambridge, and equal contribution;
(2) Ameya Prabhu, Tubingen AI Center, University of Tubingen, University of Oxford, and equal contribution;
(3) Adhiraj Ghosh, Tubingen AI Center, University of Tubingen;
(4) Yash Sharma, Tubingen AI Center, University of Tubingen;
(5) Philip H.S. Torr, University of Oxford;
(6) Adel Bibi, University of Oxford;
(7) Samuel Albanie, University of Cambridge and equal advising, order decided by a coin flip;
(8) Matthias Bethge, Tubingen AI Center, University of Tubingen and equal advising, order decided by a coin flip.






{kind=link}