Table of Links
Abstract and 1. Introduction
2 Concepts in Pretraining Data and Quantifying Frequency
3 Comparing Pretraining Frequency & “Zero-Shot” Performance and 3.1 Experimental Setup
3.2 Result: Pretraining Frequency is Predictive of “Zero-Shot” Performance
4 Stress-Testing the Concept Frequency-Performance Scaling Trend and 4.1 Controlling for Similar Samples in Pretraining and Downstream Data
4.2 Testing Generalization to Purely Synthetic Concept and Data Distributions
5 Additional Insights from Pretraining Concept Frequencies
6 Testing the Tail: Let It Wag!
7 Related Work
8 Conclusions and Open Problems, Acknowledgements, and References
Part I
Appendix
A. Concept Frequency is Predictive of Performance Across Prompting Strategies
B. Concept Frequency is Predictive of Performance Across Retrieval Metrics
C. Concept Frequency is Predictive of Performance for T2I Models
D. Concept Frequency is Predictive of Performance across Concepts only from Image and Text Domains
E. Experimental Details
F. Why and How Do We Use RAM++?
G. Details about Misalignment Degree Results
H. T2I Models: Evaluation
I. Classification Results: Let It Wag!
3 Comparing Pretraining Frequency & “Zero-Shot” Performance
Having obtained frequency estimates for our downstream concepts, we now establish the relationship between image-text matched pretraining concept frequencies and zero-shot performance across classification, retrieval, and generation tasks. We first detail our experimental approach and then discuss key results.
3.1 Experimental Setup
We analyze two classes of multimodal models: Image-Text and Text-to-Image. For both, we detail the pretraining and testing datasets, along with their associated evaluation parameters.
3.1.1 Image-Text (CLIP) Models
Datasets. Our evaluation consists of 4 pretraining datasets, 2 downstream retrieval datasets, and 17 downstream classification datasets, presented in Tab. 1, covering a broad spectrum of objects, scenes, and fine-grained distinctions.
Models. We test CLIP [91] models with both ResNet [53] and Vision Transformer [36] architecture, with ViT-B-16 [81] and RN50 [48, 82] trained on CC-3M and CC-12M, ViT-B-16, RN50, and RN101 [61] trained on YFCC-15M, and ViT-B-16, ViT-B-32, and ViT-L-14 trained on LAION400M [102]. We follow open clip [61], slip [81] and cyclip [48] for all implementation details.
Prompting. For zero-shot classification, we experiment with three prompting strategies: {classname} only, “A photo of a {classname}” and prompt-ensembles [91], which averages over 80 different prompt variations of {classname}. For retrieval, we use the image or the caption as input corresponding to I2T (image-to-text) or T2I (text-to-image) retrieval respectively.
Metrics. We compute mean zero-shot classification accuracy for classification tasks [91]. For retrieval, we assess performance using traditional metrics for both text-to-image and image-to-text retrieval tasks [91] (Recall@1, Recall@5, Recall@10).
3.1.2 Text-to-Image Models
Datasets. Our pretraining dataset is LAION-Aesthetics [103], with downstream evaluations done on subsampled versions of eight datasets as released by HEIM [71]: CUB200 [121], Daily-DALLE [33],




Detection [30], Parti-Prompts [130], DrawBench [98], COCO-Base [73], Relational Understanding [32] and Winoground [114]. Please refer to HEIM [71] for more details on the evaluation datasets used.
Models. We evaluate 24 T2I models, detailed in Tab. 2. Their sizes range from 0.4B parameters (DeepFloyd-IF-M [9] and DALL·E Mini [34]) to 4.3B parameters (DeepFloyd-IF-XL [9]). We include various Stable Diffusion models [96] as well as variants tuned for specific visual styles [6, 4, 5].
Prompting. Text prompts from the evaluation datasets are used directly to generate images, with 4 image samples generated for each prompt.
Metrics. Evaluation consists of image-text alignment and aesthetic scores. For automated metrics [71], we use expected and max CLIP-score [57] to measure image-text alignment along with expected and max aesthetics-score [102] to measure aesthetics. To verify reliability of the automated metrics, we compare them with human-rated scores (measured on a 5-point grading scale) for both image-text alignment and aesthetics [71]. To supplement the human-rated scores provided by HEIM [71], we confirm our findings by performing a small-scale human evaluation as well (see Appx. C).


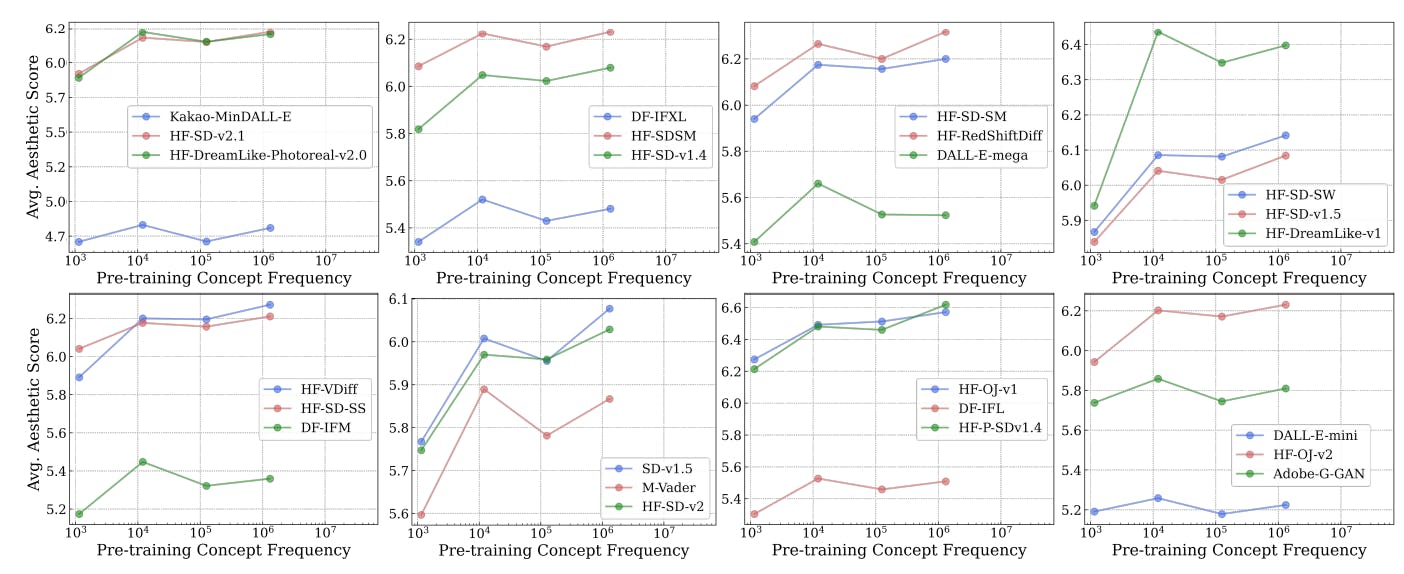
3.2 Result: Pretraining Frequency is Predictive of “Zero-Shot” Performance
We now probe the impact of concept frequency in pretraining datasets on the zero-shot performance of image-text models. We utilize the matched image-text concept frequencies for estimating frequency of concepts during pretraining. Our findings, illustrated comprehensively in Figs. 2 and 3, demonstrate the effect concept frequency has on model performance across various tasks and model types.
Understanding the Plots. The plots in the main paper present text-image (CLIP) models’ zero-shot classification results using accuracy and text-to-image retrieval performance using Recall@10. Similarly, we present T2I generative models’ performance on image generation tasks using the expected aesthetics score. For the other aforementioned metrics for retrieval as well as other automated generation metrics along with human-rated scores, we find that they show similar trends, and we provide them for reference in Apps. B and C. For clarity, the data presentation is simplified from scatter plots to a cohesive line similar to work from Kandpal et al. [62] and Razeghi et al. [94]. The x-axis is log-scaled, and performance metrics are averaged within bins along this axis for ease-of-visualization of the log-linear correlation. We removed bins containing very few concepts per bin by standard IQR removal [122] following Kandpal et al. [62]. We additionally compute the pearson correlation ρ for each line and provide significance results based on a two-tailed t-test [110].
Key Finding: Log-linear scaling between concept frequency and zero-shot performance. Across all 16 plots, we observe a clear log-linear relationship between concept frequency and zero-shot performance. Note that these plots vary in (i) discriminative vs. generative model types, (ii) classification vs. retrieval tasks, (iii) model architecture and parameter scales, (iv) pretraining datasets with different curation methods and scales, (v) different evaluation metrics, (vi) different prompting strategies for zero-shot classification, and (vii) concept frequencies isolated only from image or text domains (additional experiments which show variation along (v) are presented in Apps. B and C, across (vi) are presented in Appx. A, and across (vii) are presented in Appx. D). The observed log-linear scaling trend persists across all seven presented dimensions. Thus, our results clearly reveal data hungry learning, i.e, a lack in current multimodal models’ ability to learn concepts from pretraining datasets in a sample-efficient manner.


Authors:
(1) Vishaal Udandarao, Tubingen AI Center, University of Tubingen, University of Cambridge, and equal contribution;
(2) Ameya Prabhu, Tubingen AI Center, University of Tubingen, University of Oxford, and equal contribution;
(3) Adhiraj Ghosh, Tubingen AI Center, University of Tubingen;
(4) Yash Sharma, Tubingen AI Center, University of Tubingen;
(5) Philip H.S. Torr, University of Oxford;
(6) Adel Bibi, University of Oxford;
(7) Samuel Albanie, University of Cambridge and equal advising, order decided by a coin flip;
(8) Matthias Bethge, Tubingen AI Center, University of Tubingen and equal advising, order decided by a coin flip.







{kind=link}