Authors:
(1) Vishaal Udandarao, Tubingen AI Center, University of Tubingen, University of Cambridge, and equal contribution;
(2) Ameya Prabhu, Tubingen AI Center, University of Tubingen, University of Oxford, and equal contribution;
(3) Adhiraj Ghosh, Tubingen AI Center, University of Tubingen;
(4) Yash Sharma, Tubingen AI Center, University of Tubingen;
(5) Philip H.S. Torr, University of Oxford;
(6) Adel Bibi, University of Oxford;
(7) Samuel Albanie, University of Cambridge and equal advising, order decided by a coin flip;
(8) Matthias Bethge, Tubingen AI Center, University of Tubingen and equal advising, order decided by a coin flip.
Table of Links
Abstract and 1. Introduction
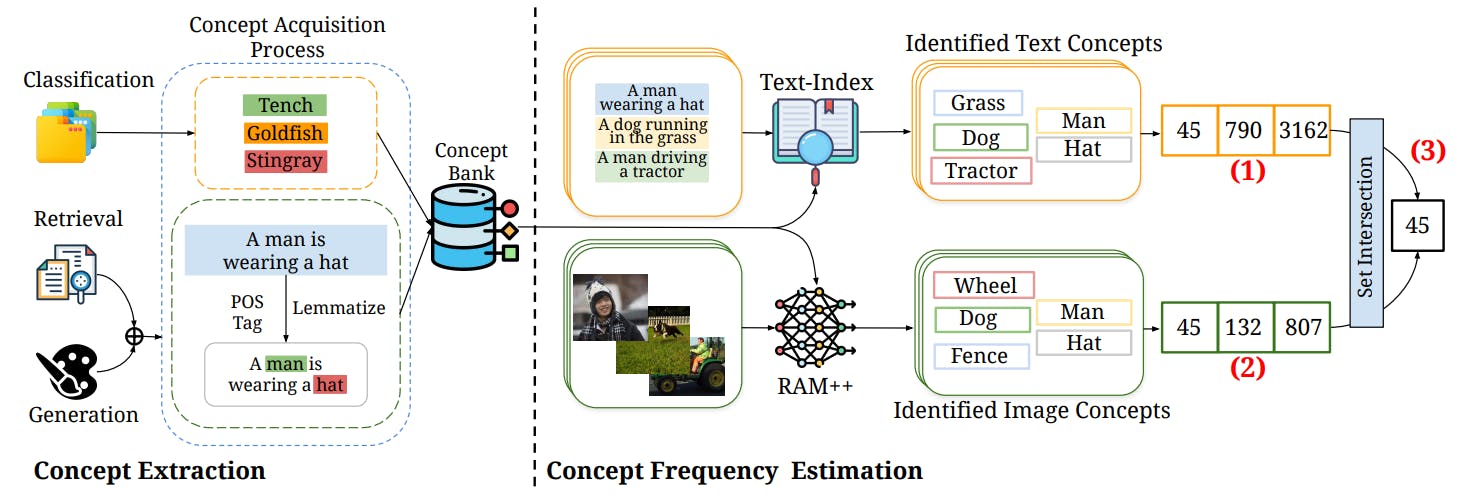
2 Concepts in Pretraining Data and Quantifying Frequency
3 Comparing Pretraining Frequency & “Zero-Shot” Performance and 3.1 Experimental Setup
3.2 Result: Pretraining Frequency is Predictive of “Zero-Shot” Performance
4 Stress-Testing the Concept Frequency-Performance Scaling Trend and 4.1 Controlling for Similar Samples in Pretraining and Downstream Data
4.2 Testing Generalization to Purely Synthetic Concept and Data Distributions
5 Additional Insights from Pretraining Concept Frequencies
6 Testing the Tail: Let It Wag!
7 Related Work
8 Conclusions and Open Problems, Acknowledgements, and References
Part I
Appendix
A. Concept Frequency is Predictive of Performance Across Prompting Strategies
B. Concept Frequency is Predictive of Performance Across Retrieval Metrics
C. Concept Frequency is Predictive of Performance for T2I Models
D. Concept Frequency is Predictive of Performance across Concepts only from Image and Text Domains
E. Experimental Details
F. Why and How Do We Use RAM++?
G. Details about Misalignment Degree Results
H. T2I Models: Evaluation
I. Classification Results: Let It Wag!
Abstract
Web-crawled pretraining datasets underlie the impressive “zero-shot” evaluation performance of multimodal models, such as CLIP for classification/retrieval and Stable-Diffusion for image generation. However, it is unclear how meaningful the notion of “zero-shot” generalization is for such multimodal models, as it is not known to what extent their pretraining datasets encompass the downstream concepts targeted for during “zero-shot” evaluation. In this work, we ask: How is the performance of multimodal models on downstream concepts influenced by the frequency of these concepts in their pretraining datasets?
We comprehensively investigate this question across 34 models and five standard pretraining datasets (CC-3M, CC-12M, YFCC-15M, LAION-400M, LAION-Aesthetics), generating over 300GB of data artifacts. We consistently find that, far from exhibiting “zero-shot” generalization, multimodal models require exponentially more data to achieve linear improvements in downstream “zero-shot” performance, following a sample inefficient log-linear scaling trend. This trend persists even when controlling for sample-level similarity between pretraining and downstream datasets [79], and testing on purely synthetic data distributions [51]. Furthermore, upon benchmarking models on long-tailed data sampled based on our analysis, we demonstrate that multimodal models across the board perform poorly. We contribute this long-tail test set as the Let it Wag! benchmark to further research in this direction. Taken together, our study reveals an exponential need for training data which implies that the key to “zero-shot” generalization capabilities under large-scale training paradigms remains to be found.
1 Introduction
Multimodal models like CLIP [91] and Stable Diffusion [96] have revolutionized performance on downstream tasks—CLIP is now the de-facto standard for “zero-shot” image recognition [133, 72, 126, 48, 132] and imagetext retrieval [46, 64, 24, 117, 129], while Stable Diffusion is now the de-facto standard for “zero-shot” text-to-image (T2I) generation [93, 17, 96, 41]. In this work, we investigate this empirical success through the lens of zero-shot generalization [69], which refers to the ability of the model to apply its learned knowledge to new unseen concepts. Accordingly, we ask: Are current multimodal models truly capable of “zero-shot” generalization?
To address this, we conducted a comparative analysis involving two main factors: (1) the performance of models across various downstream tasks and (2) the frequency of test concepts within their pretraining datasets. We compiled a comprehensive list of 4, 029 concepts[1] from 27 downstream tasks spanning classification, retrieval, and image generation, assessing the performance against these concepts. Our analysis spanned five large-scale pretraining datasets with different scales, data curation methods and sources (CC-3M [107], CC-12M [27], YFCC-15M [113], LAION-Aesthetics [103], LAION-400M [102]), and evaluated the performance of 10 CLIP models and 24 T2I models, spanning different architectures and parameter scales. We consistently find across all our experiments that, across concepts, the frequency of a concept in the pretraining dataset is a strong predictor of the model’s performance on test examples containing that concept. Notably, model performance scales linearly as the concept frequency in pretraining data grows exponentially i.e., we observe a consistent log-linear scaling trend. We find that this log-linear trend is robust to controlling for correlated factors (similar samples in pretraining and test data [79]) and testing across different concept distributions along with samples generated entirely synthetically [51].
Our findings indicate that the impressive empirical performance of multimodal models like CLIP and Stable Diffusion can be largely attributed to the presence of test concepts within their vast pretraining datasets, thus their reported empirical performance does not constitute “zero-shot” generalization. Quite the contrary, these models require exponentially more data on a concept to linearly improve their performance on tasks pertaining to that concept, highlighting extreme sample inefficiency.
In our analysis, we additionally document the distribution of concepts encountered in pretraining data and find that:
• Concept Distribution: Across all pretraining datasets, the distribution of concepts is long-tailed (see Fig. 5 in Sec. 5), which indicates that a large fraction of concepts are rare. However, given the extreme sample inefficiency observed, what is rare is not properly learned during multimodal pretraining.
• Concept Correlation across Pretraining Datasets: The distribution of concepts across different pretraining datasets are strongly correlated (see Tab. 4 in Sec. 5), which suggests web crawls yield surprisingly similar concept distributions across different pretraining data curation strategies, necessitating explicit rebalancing efforts [11, 125].
• Image-Text Misalignment between Concepts in Pretraining Data: Concepts often appear in one modality but not the other, which implies significant misalignment (see Tab. 3 in Sec. 5). Our released data artifacts can help image-text alignment efforts at scale by precisely indicating the examples in which modalities misalign. Note that the log-linear trend across both modalities is robust to this misalignment.
To provide a simple benchmark for generalization performance for multimodal models, which controls for the concept frequency in the training set, we introduce a new long-tailed test dataset called “Let It Wag!”. Current models trained on both openly available datasets (e.g., LAION-2B [103], DataComp-1B [46]) and closed-source datasets (e.g., OpenAI-WIT [91], WebLI [29]) have significant drops in performance, providing evidence that our observations may also transfer to closed-source datasets. We publicly release all our data artifacts (over 300GB), amortising the cost of analyzing the pretraining datasets of multimodal foundation models for a more data-centric understanding of the properties of multimodal models in the future.
Several prior works [91, 46, 82, 42, 83, 74] have investigated the role of pretraining data in affecting performance. Mayilvahanan et al. [79] showed that CLIP’s performance is correlated with the similarity between training and test datasets. In other studies on specific areas like question-answering [62] and numerical reasoning [94] in large language models, high train-test set similarity did not fully account for observed performance levels [127]. Our comprehensive analysis of several pretraining image-text datasets significantly adds to this line of work, by (1) showing that concept frequency determines zero-shot performance and (2) pinpointing the exponential need for training data as a fundamental issue for current large-scale multimodal models. We conclude that the key to “zero-shot” generalization capabilities under large-scale training paradigms remains to be found.
[1] class categories for classification tasks, objects in the text captions for retrieval tasks, and objects in the text prompts for generation tasks, see Sec. 2 for more details on how we define concepts.







{kind=link}