AI models are great at writing poems, summarizing emails, or pretending to be philosophers. But can they extract a due date from an invoice? Can they understand a broken table with merged cells and half-missing headers?
That’s what I wanted to find out.
So I tested 5 popular AI models—from cloud APIs to bleeding-edge LLMs—on two of the most boring and useful tasks in real business workflows:
(1) invoice field extraction and (2) structured table parsing.
The setup was simple: 20 real invoices and 20 tables taken from actual business documents. Some were clean, most weren’t. I looked at how each model handled missing data, inconsistent layouts, OCR artifacts, and nested structures. Then I measured four things:
Accuracy, speed, cost, and stability under messy input.
Each model had to process 20 invoices and 20 tables, and return structured outputs: totals, invoice dates, vendor names, tax fields, and row-level values.
Inputs were given as plain OCR text, not pre-labeled or fine-tuned. The only thing the models had to work with was the raw content, plus a prompt.
Some models impressed. Others hallucinated totals or ignored headers.
What follows is a field guide to what each of these models actually can and can’t do—if you’re planning to use them in production, this is what you need to know.
Performance: Textract delivered reliable results on invoice extraction. It scored 91.3% without line items and 91.1% with them.
It handled standard fields well—totals, invoice numbers, dates—and didn’t hallucinate values or invent structure. If the input was clear, it performed consistently. If a field was missing or ambiguous, it left it blank without guessing.
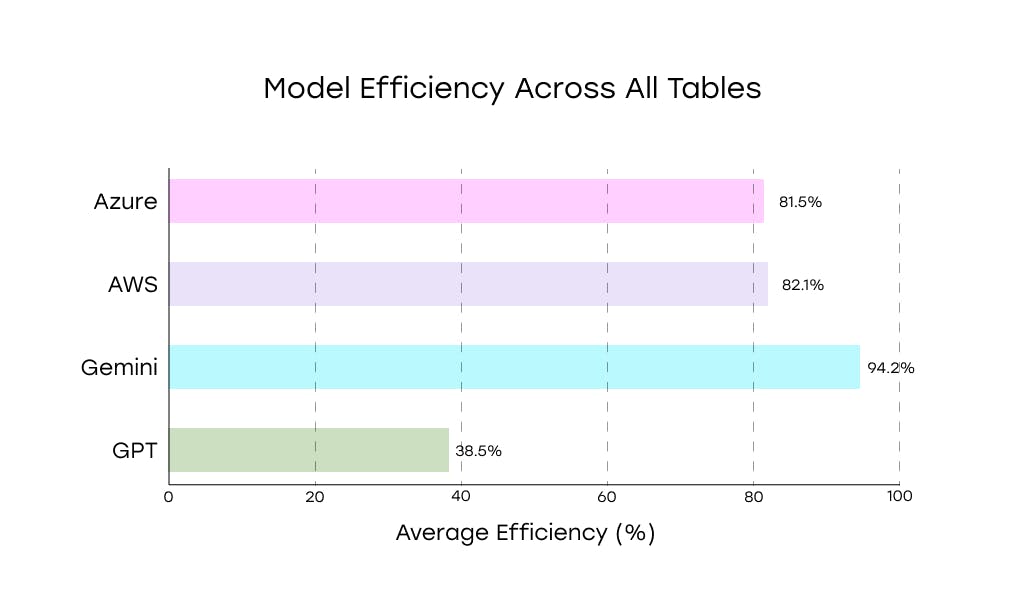
On tables, Textract reached 82.1% accuracy, outperforming GPT-4o and slightly edging out Azure. It handled flat structures smoothly and made fewer structural mistakes than models reliant on generative reasoning.
But it struggled with deeply nested headers or inconsistent cell alignment.
When table formatting broke down, Textract returned partial or flattened outputs rather than trying to interpret intent.
It also handled low-resolution scans (200–300 DPI) without a drop in performance, keeping field accuracy stable even when documents were slightly blurred.
Speed: Excellent. Average processing time: 2.1 seconds per page, making it the fastest model tested with consistent accuracy.
Cost: Low. $10 per 1,000 pages using the AnalyzeExpense endpoint, as reported in the benchmark. Straightforward pricing, no tokens, no surprises.
Verdict: Textract is built for scale. It’s not creative, but that’s exactly the point. It won’t infer structure or adapt to chaos, but it won’t break under pressure either.
Best used in pipelines where document format is controlled, and you need predictable results at speed.
For messy layouts or irregular tables, you’ll need to look elsewhere—but for well-formed business docs, it’s one of the most efficient tools available.
Azure Document Intelligence: Clean Output, Limited Nerve
Performance: Azure handled invoices reliably, scoring 85.8% accuracy without line items and 85.7% with them. It consistently extracted core fields—invoice number, date, total—but often missed edge cases like split vendor names or less common labels. It avoided hallucinations and rarely mislabeled data, but it also didn’t recover well from ambiguity.
It struggled with multi-word item descriptions in invoice tables—like full employee names or long service lines—which caused accuracy to collapse in some cases.
On tables, it reached 81.5% accuracy, just behind AWS and well below Gemini.
It performed well on flat, regular layouts, reading rows and columns without major errors. But it struggled with structural complexity—merged cells, stacked headers, or inconsistent alignment led to dropped values or misclassified columns. It stayed functional, but cautious.
Speed: Fast. Around 3.5 seconds per page on average. Slightly slower than AWS, but stable and production-ready.
Cost: Approximately $10 per 1,000 pages using the prebuilt invoice model. Fixed pricing through Azure’s API, no tuning required.
Verdict: Azure gets the job done if the job is clearly defined. It’s a low-risk choice for structured invoices and clean tables, but it’s not the model you call when layout gets messy.
It’s reliable, but it doesn’t push boundaries—and it won’t keep up with models that do. Best used in document flows where consistency beats adaptability.
Google Document AI: Great When It’s Easy, Lost When It’s Not
Performance: On invoices, Google showed uneven performance. It reached 83.8% accuracy without line items but dropped to 68.1% when tables were included
It handled standard fields like invoice number and date, but often mislabeled tax fields, duplicated totals, or ignored line-level data. Invoices with slight layout shifts or less conventional formats caused frequent extraction errors.
Table parsing was its weakest area. Google scored 38.5% accuracy—tied with GPT-4o for the lowest result in the benchmark.
It managed clean, grid-like tables reasonably well but consistently failed on real-world cases with merged headers, blank rows, or structural irregularities. Cell relationships broke down, column labels were lost, and the final output often lacked usable structure.
It also returned line items as unstructured rows of text rather than properly segmented fields. That made quantity, unit price, and total extraction unreliable or impossible to validate.
Speed: Moderate. Around 5.1 seconds per page, slower than Azure and AWS, but not dramatically.
Cost: Roughly $10–12 per 1,000 pages, depending on configuration and region. Pricing is API-based and predictable but harder to justify at current accuracy levels.
Verdict: Google Document AI works when documents are clean, predictable, and tightly structured.
The moment layout complexity increases, accuracy drops hard. It’s not suitable for critical extraction tasks involving dynamic formats or layered tables.
Best used in controlled internal workflows where input variability is minimal and expectations are modest.
GPT-4o: Smart, Precise, Sensitive to Input
Performance: GPT-4o handled invoice extraction well. It reached 90.8% accuracy without line items and 86.5% with them using OCR-based input.
When working with document images, the scores stayed consistent: 88.3% and 89.2%, respectively. It correctly identified totals, dates, invoice numbers, and vendor names.
It was also good at choosing the right value when multiple similar ones appeared on the page.
It handled low-resolution documents without major loss in accuracy. However, it sometimes misread punctuation—dropping commas or misplacing decimal points in numeric fields.
But table parsing was a different story. GPT-4o scored just 38.5% accuracy—the lowest result among all models in the benchmark.
While it followed basic structure in simple cases, it broke down on merged headers, nested rows, and incomplete layouts.
Column relationships were often misread, and cell values misplaced or dropped entirely. It looked like a text model trying to reason its way through a visual problem—and missing key cues.
Speed: Around 17–20 seconds per page with OCR text input.
With image input, latency increases sharply—often 30 seconds or more, depending on prompt size and system load.
Cost: Moderate. Approximately $5–6 per 1,000 pages using GPT-4-turbo (text input).
Image-based input via vision API can double that, depending on prompt length and token usage.
Verdict: GPT-4o performs well on invoices and understands structured text with nuance and flexibility. But on visually complex tables, it struggles to maintain structure or produce consistent outputs.
If you’re working with documents where layout matters—and accuracy can’t dip below 40%—you’ll need to look elsewhere.
Use it when you control the input format or prioritize invoice-level intelligence over document layout.
Gemini 1.5 Pro: Quietly Dominant
Performance: Gemini handled invoice parsing with steady precision. It scored 90.0% accuracy without line items and 90.2% with them.
It consistently pulled totals, dates, invoice numbers, and vendor names—even when the format shifted or fields weren’t neatly labeled. Errors were minor: duplicate values, misread tax fields, the occasional extra symbol. But critical data rarely went missing.
On tables, Gemini outclassed every other model. It reached 94.2% accuracy, leading the benchmark.
AWS and Azure followed at 82.1% and 81.5%, while GPT-4o lagged far behind at 38.5%. Gemini parsed multi-level headers, merged cells, and uneven row structures with fewer mistakes and better structural understanding. It made occasional alignment errors, but kept the data usable.
Speed: Consistently fast. 3–4 seconds per page on average. Faster than GPT-4o, slightly behind AWS, with no unpredictable slowdowns.
Cost: Estimated $4–5 per 1,000 pages using the Gemini API in text-only experimental mode. Image input was not tested in this benchmark.
Verdict: Gemini delivers high accuracy across both invoices and tables without needing vision input or complex setup. It’s fast, structurally aware, and more resilient to layout quirks than any other model tested.
Best used when you want production-grade results from inconsistent documents and can control the input format.
Reliable under pressure—no drama, just output.
Results
Five models. Same tasks. Same documents. Very different outcomes.
- Gemini was the best all-around — fast, accurate, and sharp on structure.
- GPT-4o nailed invoices, choked on tables.
- AWS Textract was fast, rigid, and hard to break.
- Azure got the basics right, but nothing more.
- Google struggled with anything that wasn’t clean and labeled.
No model handled everything. A few handled enough. If you’re building with AI, test first — or plan to clean up later.





{kind=link}