
If you are a Product Manager feeling overwhelmed with your days caught in a whirlwind of customer feedback, you are not alone! Here is where Retrieval Augmented Generation (RAG) steps in as a powerful ally, helping to transform the way you engage with information quietly.
Imagine you are running an e-commerce store website with hundreds of products, each with its own documentation (manual, FAQs, troubleshooting guides, etc.). Customers often inquire about particular product features, warranty information, or common concerns and issues. A regular chatbot, trained solely on general internet data, would likely struggle to provide accurate and up-to-date answers specific to your products, resulting in frustrated customers and an increase in support tickets.
This is where Retrieval Augmented Generation (RAG) comes to the rescue! (as an example!) RAG combines the power of Large Language Models (LLMs) with a custom knowledge base, allowing the LLM to access and leverage specific, relevant information that it was not originally trained on.
The problem with traditional LLMs
Large Language Models like GPT-4 or Gemini offer powerful capabilities for language understanding, generation, and even writing code. However, their knowledge is “frozen” at the time of their last training data. They cannot access real-time information, your company’s proprietary documents, or niche details not widely available on the internet. Being susceptible to:
- Hallucinations: Fabricating answers instead of admitting that they do not know the correct answer.
- Outdated Information: Providing answers based on outdated data is insufficient.
- Lack of Specificity: Unable to answer questions requiring particular domain knowledge. In the context of customer support and internal knowledge sharing, it requires constant feedback from product managers to clarify any points that may be unclear.


Using RAG with an LLM helps tackle some of these challenges. When the LLM has access to all the vital information for your specific application, it can better answer questions on topics it was not specifically trained for, which helps to minimise the chances of it making errors, or “hallucinations.”
Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by identifying the most relevant document chunks from an external knowledge base, thanks to sophisticated calculations of semantic similarity.


A RAG Solution: The “Smart Chatbot” example
Let’s use our e-commerce customer support chatbot as a practical RAG application. Instead of depending on a pre-trained LLM’s static knowledge, our chatbot will “augment” its responses by retrieving pertinent information from a small, simulated knowledge base of product documents.
Building the knowledge base (Ingestion phase)
We will develop a specialised knowledge base containing some dummy text files that our RAG system will “read” to acquire its knowledge. These files will represent our fictional “XYZ Product” documentation.
We’ll use Python to create these files directly.
import os
# Define the directory for our simulated documents
DOCS_DIR = "product_docs"
os.makedirs(DOCS_DIR, exist_ok=True)
# Content for our dummy product documents
doc_contents = {
"product_manual_xyz.txt": """
Product Manual for XYZ Wireless Earbuds
1. Introduction:
Welcome to your new XYZ Wireless Earbuds! These earbuds offer high-quality audio and a comfortable fit.
2. Charging:
To charge your earbuds, place them in the charging case. The LED indicator on the case will show battery status. A full charge takes approximately 1.5 hours.
3. Pairing:
Open the charging case. The earbuds will automatically enter pairing mode. On your device (phone/laptop), go to Bluetooth settings and select "XYZ Earbuds". The earbuds will emit a sound upon successful connection.
4. Controls:
- Single tap (left/right): Play/Pause
- Double tap (right): Next song
- Double tap (left): Previous song
- Triple tap (left/right): Activate voice assistant
5. Troubleshooting:
- If earbuds are not connecting, ensure they are charged and try resetting them (see section 6).
- If audio is distorted, check your device's volume and ensure no interference.
6. Resetting the Earbuds:
To reset your XYZ Wireless Earbuds to factory settings, place both earbuds in the charging case. Press and hold the button on the charging case for 15 seconds until the LED light blinks red three times. Then, close the case and reopen it.
""",
"faq_warranty.txt": """
Frequently Asked Questions (FAQ) - XYZ Wireless Earbuds
Q: What is the warranty period for the XYZ Earbuds?
A: The XYZ Wireless Earbuds come with a 1-year limited warranty from the date of purchase. Please retain your proof of purchase for warranty claims.
Q: How do I claim warranty?
A: To claim warranty, please visit our support page at [www.xyztech.com/support](https://www.xyztech.com/support) and fill out the warranty claim form, attaching your receipt. Our team will contact you within 2-3 business days.
Q: Are the XYZ Earbuds waterproof?
A: The XYZ Earbuds are splash-resistant (IPX4 rating), meaning they can withstand light rain and sweat. They are NOT designed for submersion in water.
Q: What devices are compatible?
A: The earbuds are compatible with any Bluetooth-enabled device, including smartphones, tablets, and laptops.
""",
"troubleshooting_guide.txt": """
Troubleshooting Guide for XYZ Wireless Earbuds
Issue: Earbuds not charging.
Solution: Ensure the charging case has power. Check the charging cable and adapter. Clean the charging contacts on both earbuds and the case with a dry cotton swab. If still not charging, contact support.
Issue: One earbud not working.
Solution:
1. Ensure both earbuds are charged.
2. Try resetting the earbuds (refer to the product manual for instructions).
3. Re-pair the earbuds with your device.
4. If the issue persists, it might be a hardware problem.
Issue: Low volume or distorted sound.
Solution:
1. Check the volume level on your connected device.
2. Ensure there's no obstruction in the earbud's speaker grill.
3. Try playing audio from a different source to rule out the media file.
4. Clean the earbuds.
"""
}
# Write the content to files
for filename, content in doc_contents.items():
filepath = os.path.join(DOCS_DIR, filename)
with open(filepath, "w") as f:
f.write(content.strip()) # .strip() removes leading/trailing whitespace for cleaner files
print(f"Created: {filepath}")
Answering a user query (Retrieval & Augmentation phases)
When a customer asks a question like “How do I reset my XYZ product?”, here’s what happens:
- Chunking: We break down these large documents into smaller, manageable “chunks” (e.g., paragraphs, sections). To retrieve particular pieces of information.
- Embedding: Each of these text chunks is converted into a numerical representation called an “embedding” (a vector of numbers), using an “embedding model.” Think of embeddings to capture the meaning of the text in a mathematical form. Text chunks with similar meanings will have embeddings that are “close” to each other in a multi-dimensional space.
- Vector Database: These embeddings are stored in a specialised database called a “vector database” (e.g., Pinecone, Weaviate, or even a simple in-memory one for small scale). This database is optimised for speedy similarity searches.
- Query Embedding: The customer’s question is also converted into an embedding using the same embedding model used for our knowledge base.
- Similarity Search: The system performs a “similarity search” in the vector database to find the product document chunks whose embeddings are most similar to the customer’s query embedding. Efficiently retrieving the most relevant pieces of information from our product knowledge base.
When we say, “embeddings are close,” we’re essentially talking about measuring the distance or similarity between these vectors. A standard method for doing this is to use cosine similarity.


import numpy as np
from typing import List, Dict, Tuple
import glob # To find our created text files
class DocumentChunk:
"""Represents a chunk of text from our knowledge base."""
def __init__(self, text: str, source_file: str, chunk_id: str):
self.text = text
self.source_file = source_file
self.chunk_id = chunk_id
self.embedding: List[float] = [] # To be filled by the embedding model
def __repr__(self):
return f"DocumentChunk(id='{self.chunk_id}', source='{self.source_file}', text='{self.text[:50]}...')"
class EmbeddingModel:
"""
A conceptual embedding model.
In a real scenario, this would use a pre-trained model to convert text into meaningful vectors.
For simplicity, we're generating dummy embeddings based on a hash.
"""
def get_embedding(self, text: str) -> List[float]:
# Generating a very simple, non-semantic dummy embedding
# In a real application, use a library like 'sentence-transformers' or a model API
np.random.seed(hash(text) % (2**32 - 1)) # Seed for reproducibility based on text
return np.random.rand(768).tolist() # Return a list of 768 random floats
def cosine_similarity(self, vec1: List[float], vec2: List[float]) -> float:
"""Calculates cosine similarity between two vectors."""
vec1_np = np.array(vec1)
vec2_np = np.array(vec2)
dot_product = np.dot(vec1_np, vec2_np)
norm_vec1 = np.linalg.norm(vec1_np)
norm_vec2 = np.linalg.norm(vec2_np)
if norm_vec1 == 0 or norm_vec2 == 0:
return 0.0 # Avoid division by zero
return dot_product / (norm_vec1 * norm_vec2)
class VectorDatabase:
"""
A highly simplified in-memory vector database.
In a real system, this would be a dedicated vector database for efficient large-scale search.
"""
def __init__(self, embedding_model: EmbeddingModel):
self.store: Dict[str, DocumentChunk] = {}
self.embedding_model = embedding_model
self._chunk_counter = 0
def add_document(self, filepath: str):
"""Reads a file, chunks its content, and adds to the store with embeddings."""
with open(filepath, 'r') as f:
full_text = f.read()
# Simple chunking: split by paragraphs or double newlines
# For more advanced chunking, consider libraries like LangChain's TextSplitter
chunks = [c.strip() for c in full_text.split('nn') if c.strip()]
print(f"Processing {len(chunks)} chunks from {filepath}...")
for i, text in enumerate(chunks):
chunk_id = f"{os.path.basename(filepath).replace('.', '_')}_chunk_{self._chunk_counter}"
doc_chunk = DocumentChunk(text=text, source_file=filepath, chunk_id=chunk_id)
doc_chunk.embedding = self.embedding_model.get_embedding(text)
self.store[chunk_id] = doc_chunk
self._chunk_counter += 1
print(f"Finished processing {filepath}.")
def find_similar_chunks(self, query_embedding: List[float], top_k: int = 3) -> List[Tuple[DocumentChunk, float]]:
"""
Finds the top_k most similar document chunks to the query embedding.
Returns a list of (DocumentChunk, similarity_score) tuples.
"""
if not self.store:
return []
similarities = []
for chunk_id, chunk in self.store.items():
if chunk.embedding:
score = self.embedding_model.cosine_similarity(query_embedding, chunk.embedding)
similarities.append((chunk, score))
# Sort by similarity score in descending order
similarities.sort(key=lambda x: x[1], reverse=True)
return similarities[:top_k]
def simulated_llm(prompt: str) -> str:
"""
A simplified Large Language Model (LLM) stand-in.
In a real application, this would be an API call to a powerful LLM.
It tries to give a slightly more "aware" response if relevant keywords are in the prompt context.
"""
prompt_lower = prompt.lower()
if "reset" in prompt_lower and "xyz wireless earbuds" in prompt_lower and "button" in prompt_lower:
return "Based on the provided information, to reset your XYZ Wireless Earbuds, place both earbuds in the charging case, then press and hold the button on the charging case for 15 seconds until the LED light blinks red three times. After that, close the case and reopen it."
elif "warranty" in prompt_lower and "xyz wireless earbuds" in prompt_lower and "1-year" in prompt_lower:
return "The XYZ Wireless Earbuds come with a 1-year limited warranty from the date of purchase. Remember to keep your proof of purchase for any warranty claims."
elif "pairing" in prompt_lower and "bluetooth" in prompt_lower:
return "According to the manual, to pair your XYZ Earbuds, open the charging case to enter pairing mode. Then, go to your device's Bluetooth settings and select 'XYZ Earbuds'."
elif "waterproof" in prompt_lower or "submersion" in prompt_lower:
return "The XYZ Earbuds are splash-resistant (IPX4 rating) and can handle light rain or sweat. However, they are NOT designed for submersion in water."
elif "low volume" in prompt_lower or "distorted sound" in prompt_lower:
return "If you're experiencing low volume or distorted sound, check your device's volume, ensure no obstruction in the earbud's speaker grill, and try playing audio from a different source. Cleaning the earbuds might also help."
else:
return "I couldn't find specific information about that in my current knowledge base. Could you please rephrase your question or provide more details? You can also visit our website for comprehensive support."
Now, let’s load the content from our simulated text files into our VectorDatabase. Each relevant section will be turned into a DocumentChunk section and embedded.
# Initialize the embedding model and vector database
embedding_model = EmbeddingModel()
vector_db = VectorDatabase(embedding_model)
# Find all text files in our DOCS_DIR
document_files = glob.glob(os.path.join(DOCS_DIR, "*.txt"))
# Add each document to our vector database
if document_files:
for doc_file in document_files:
vector_db.add_document(doc_file)
print(f"nKnowledge base built with {len(vector_db.store)} chunks from {len(document_files)} files.")
else:
print("No document files found. Please ensure files were created correctly.")
Generating the response (generation phase)
During the generation phase, what happens is:
- LLM Processing: The LLM now receives the customer’s question along with the highly relevant context from our product documents.
- Grounded Response: With this specific information at hand, the LLM can generate a precise, accurate, and helpful answer, directly referencing the product manual or FAQ. It’s “grounded” in our proprietary data.
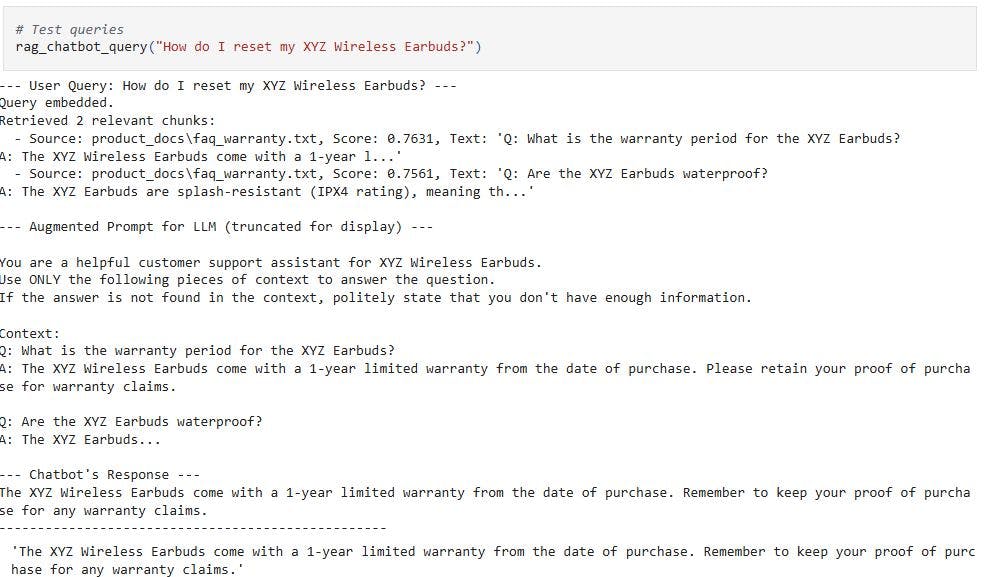
def rag_chatbot_query(user_query: str, top_k_chunks: int = 2):
"""
Main RAG chatbot function.
Processes a user query by retrieving relevant context and augmenting an LLM prompt.
"""
print(f"n--- User Query: {user_query} ---")
# 1. Embed the user's query
query_embedding = embedding_model.get_embedding(user_query)
print("Query embedded.")
# 2. Retrieve relevant chunks from the vector database
# Get (chunk, similarity_score) tuples
relevant_chunks_with_scores = vector_db.find_similar_chunks(query_embedding, top_k=top_k_chunks)
if not relevant_chunks_with_scores:
print("No relevant chunks found.")
context = "No specific context found in the knowledge base."
else:
print(f"Retrieved {len(relevant_chunks_with_scores)} relevant chunks:")
for chunk, score in relevant_chunks_with_scores:
print(f" - Source: {chunk.source_file}, Score: {score:.4f}, Text: '{chunk.text[:100]}...'")
# 3. Augment the prompt with retrieved context
context = "nn".join([chunk.text for chunk, _ in relevant_chunks_with_scores])
# Construct the augmented prompt for the LLM
augmented_prompt = f"""
You are a helpful customer support assistant for XYZ Wireless Earbuds.
Use ONLY the following pieces of context to answer the question.
If the answer is not found in the context, politely state that you don't have enough information.
Context:
{context}
Question: {user_query}
Answer:
"""
print("n--- Augmented Prompt for LLM (truncated for display) ---")
print(augmented_prompt[:500] + "..." if len(augmented_prompt) > 500 else augmented_prompt)
# 4. Generate the response using the LLM
response = simulated_llm(augmented_prompt)
print("n--- Chatbot's Response ---")
print(response)
print("-" * 50)
return response

Benefits of RAG
RAG enhances LLM-only methodologies by adding supplementary specific context to the language model, while also offering advantages over retrieval-only systems.
- Accuracy & Factuality: Reduces “hallucinations” by grounding responses in verifiable data.
- RAG application can incorporate proprietary data.
- Up-to-date Information: Can incorporate new data by simply updating the knowledge base, without retraining the entire LLM.
- Reduced Training Costs: No need to fine-tune massive LLMs for specific domains.
- Transparency: This potentially allows for citing sources, as the retrieved chunks serve as the basis for the answer.
Essentially, RAG boosts the intelligence and dependability of LLMs for domain-specific tasks and opens up a wide range of possibilities, from advanced customer support to personalised research assistants and internal knowledge management systems.
The benefits of RAG for Product Managers
As a Product Manager, you’re constantly seeking ways to enhance user experience, streamline internal operations, and make data-driven decisions. This is where Retrieval Augmented Generation (RAG) shines, silently transforming how you interact with information and ultimately, how you create and support your product.
Consider our e-commerce store example. As a Product Manager, you are highly concerned with customer satisfaction (CSAT scores) and the efficiency of support operations (cost centres). A RAG-powered chatbot has the potential to transform these aspects significantly:
- Improving how we help our customers by giving quick and accurate answers makes their experience more pleasant. Everyone benefits when we make things easier and more friendly!.
- Most customer requests can be automated, enabling the support team to focus on more complex issues. Improving operational efficiency and reducing costs.
- There is no need to wait for LLM retraining when features change; documentation can be updated, rendered, and the RAG system is updated automatically.
- Data-driven insights: Logging questions and document retrievals reveal where customers struggle, pointing to documentation improvements or new features.
- Internal Knowledge Management: RAG isn’t just for external chatbots. Imagine an internal RAG system that enables your sales team to find answers on product comparisons quickly, allows marketing to verify claims, and facilitates faster access to internal documentation.
- Competitive analysis & market research: Use RAG with external data (public reports, competitor websites) to quickly synthesise insights on market trends or competitors, supporting your product strategy.
In essence, RAG transforms LLMs from general knowledge providers into domain-specific experts, directly addressing many pain points of a Product Manager. By leveraging your proprietary data, RAG enables you to deliver a more accurate, responsive, and intelligent product experience, making your life easier and your product more successful.
I hope you enjoyed my musings. For further code reference, feel free to check out my GitHub. If you have any thoughts or feedback, I’d love to hear from you. Happy coding!







{kind=link}