At the recent AWS Summit in New York City, AWS announced the preview of Amazon S3 Vectors, claiming to be the first cloud object store with native support to storing large vector datasets. The new option offers subsecond query performance, reducing the cost of storing AI-ready data compared to traditional vector databases.
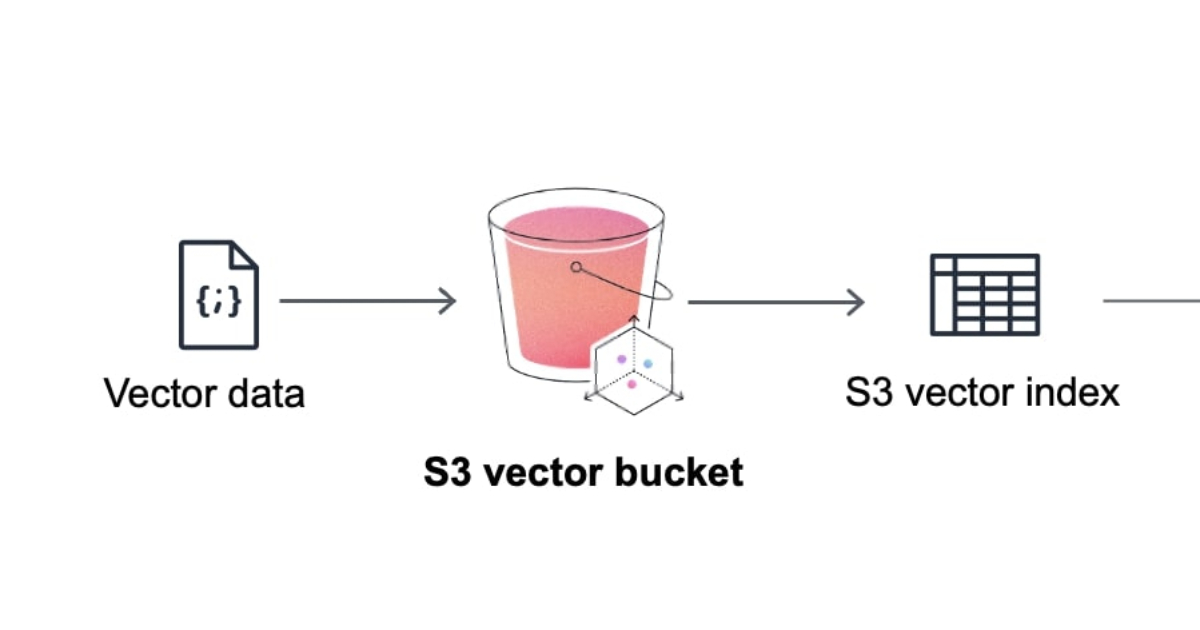
S3 Vectors introduces the concept of vector buckets, a new bucket type with a dedicated set of APIs that differs from the existing S3 standard buckets and S3 Tables. Channy Yun, principal developer advocate at AWS, explains:
With S3 Vectors, you can now economically store the vector embeddings that represent massive amounts of unstructured data such as images, videos, documents, and audio files, enabling scalable generative AI applications including semantic and similarity search, RAG, and build agent memory.
Once an S3 vector bucket is created, developers can organize vector data within vector indexes and run similarity search queries against the dataset. According to the documentation, each vector bucket can have up to 10,000 vector indexes, and each vector index can hold tens of millions of vectors.
Source: AWS blog
Developers can attach metadata as key-value pairs to vectors, and by default all metadata is filterable, with vector indexes supporting string, number, boolean, and list types.
As a standalone solution, S3 Vectors is designed for workloads where queries are not frequent. To build RAG applications on AWS, S3 Vectors integrates with Bedrock Knowledge Bases and OpenSearch. Yun adds:
Through its integration with Amazon OpenSearch Service, you can lower storage costs by keeping infrequent queried vectors in S3 Vectors and then quickly move them to OpenSearch as demands increase or to support real-time, low-latency search operations.
Andrew Warfield, VP and distinguished engineer at Amazon, clarifies the goal on LinkedIn:
This is an exciting time for the S3 team because we are actively watching as the workloads on S3 change (…) S3 Vectors costs considerably less than traditional vector stores. It also, at least for the moment, doesn’t offer the same levels of high-TPS and low latency that are common in DRAM-based stores. Our reasoning was that, just like with other data types, builders would appreciate a highly durable and low-cost foundation layer for vectors, and would be happy to move data up into higher-performance, and more feature-rich layers as necessary.
To simplify the process of working with vector embeddings in S3 Vectors, the cloud provider released the S3 Vectors Embed CLI repository, a standalone command-line tool to create, store, and query vector embeddings on S3. A tutorial “getting started with S3 Vectors” using the SDK for Python is available as well.
On a popular Reddit thread, most developers appreciate the new feature, with Travis Cunningham writing:
This move turns every S3 bucket into a mini vector store, fattens margins on hardware Amazon’s already amortized, and slams the door on competitors trying to siphon off AI workloads.
On Hacker News, user bob1029 comments instead:
I still contend that what most people want is traditional full text search, not another layer of black box weirdness behind the LLM. You already have a model with incredibly powerful semantic understanding. Why do we need the document store to also be a smartass? The model can project multiple OR clauses into the search term based upon its interpretation of the context.
In a separate announcement, Amazon S3 Metadata introduced live inventory tables for all objects in a bucket. A managed Apache Iceberg table provides a complete and current snapshot of the objects and their metadata in a bucket, including existing objects.
Leaked by mistake a few days ahead of the conference, S3 Vectors is currently in preview in a subset of regions, including Northern Virginia, Ohio, and Frankfurt in Europe.







{kind=link}