Pinterest recently replaced its Hadoop-based data platform with Moka, a Kubernetes-native system running Spark on AWS EKS. Moka enables containerized job isolation, supports ARM-based instances, improves scheduling via YuniKorn, and simplifies deployment, while reducing infrastructure costs and increasing efficiency across data processing workloads.
Pinterest made a strategic decision to transition from a legacy Hadoop-based architecture to a Spark-on-Kubernetes model, better aligning with modern infrastructure practices. It chose Kubernetes for its native support for container orchestration and security, as well as its flexibility in deploying on mixed instance types, such as ARM and x86:
Armed with these requirements, we performed a comprehensive evaluation of running Spark on various platforms during 2022. We leaned towards Kubernetes-focused frameworks for the following advantages they offered: Container-based isolation and security as first-class platform citizens, ease of deployment, built-in frameworks, and performance tuning options.
In addition, Moka introduced key cost and efficiency improvements over the legacy platform. By leveraging container-based isolation, Pinterest consolidated workloads with different security requirements onto shared clusters, thereby reducing the need for multiple clusters.
Pinterest’s engineers also acknowledge that the “greater isolation provided by a container-based system allowed removal of dedicated yet underutilized Hadoop environments in favor of running jobs with differing security requirements on the same Moka cluster.” The platform’s support for ARM-based instances and opportunistic autoscaling, scaling up clusters during off-peak hours, further contributed to infrastructure cost savings.
Replacing Hadoop required re-engineering several critical components tied to job submission, scheduling, storage, and observability – “Over the years, Hadoop and Monarch [Pinterest’s Hadoop platform] have come to encompass a tremendous amount of functionality. Building an alternative implies developing replacements…”. Pinterest developed new services, such as Archer for job submission, adopted Apache YuniKorn for queue-based scheduling, migrated storage from HDFS to S3, and integrated the Apache Celeborn Remote Shuffle Service to maintain performance at scale.
Initial Moka High Level Design (Source)
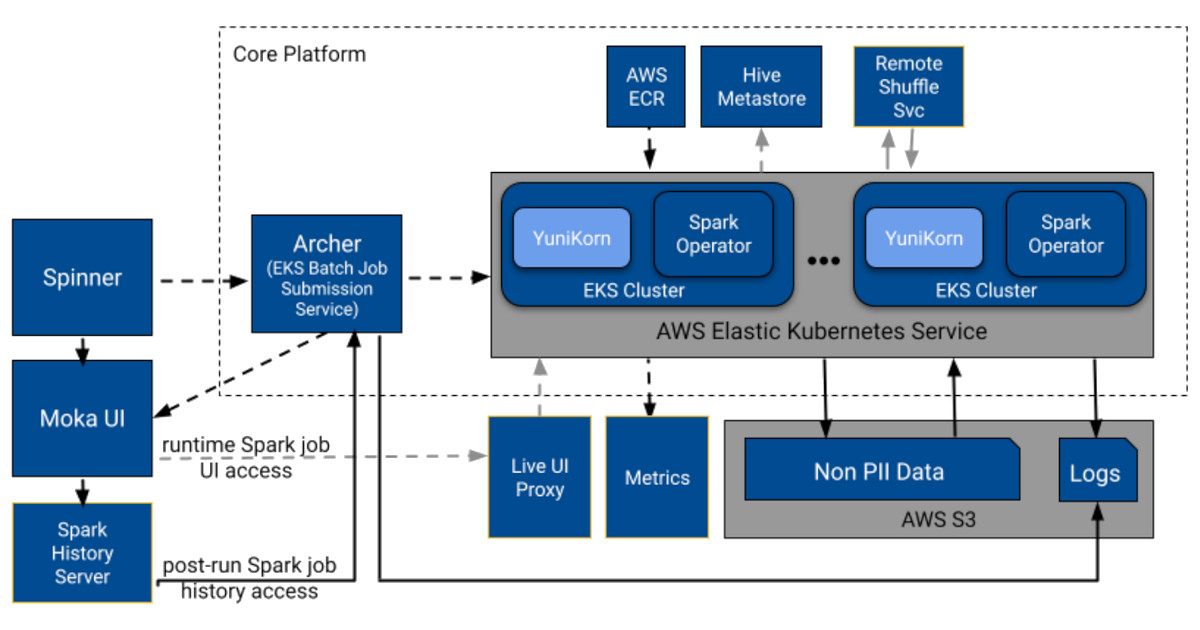
In Moka’s initial design, Spinner, Pinterest’s Airflow-based orchestration system, breaks down scheduled workflows into individual job submissions and sends them to Archer, the EKS job submission service. Archer translates each job into a Kubernetes custom resource and submits it to a Spark-enabled EKS cluster. Archer handles job queuing, status tracking, and integration with the Kubernetes API, enabling reliable deployment and efficient resource routing across clusters while maintaining compatibility with existing workflows.

Spark Operator (Source)
Pinterest’s engineers chose to utilize Spark Operator for native execution of Spark on Kubernetes and Apache YuniKorn for batch scheduling. The Spark Operator exposes the SparkApplication Custom Resource Definition (CRD), allowing for the declarative definition of Spark applications and leaving the Spark Operator to handle all the underlying submission details. Internally, Spark Operator still utilizes the native spark-submit command.

Moka Resource Management (Source)
YuniKorn offers queue-based scheduling, application quotas, and preemption, and enables Pinterest to enforce resource isolation across teams and dynamically prioritize jobs based on workload tiers and business criticality.
Once YuniKorn schedules jobs, SparkSQL jobs connect to the Hive Metastore, and workloads are executed using container images from AWS ECR. During execution, Archer tracks job status, and the system uploads logs to S3 and metrics to internal dashboards. Users can access running job UIs via network proxies and retrieve historical logs through the Spark History Server, all of which are surfaced via the read-only Moka UI.





{kind=link}