Table of Links
Abstract and 1. Introduction
-
Related Work
2.1 Text to Vocal Generation
2.2 Text to Motion Generation
2.3 Audio to Motion Generation
-
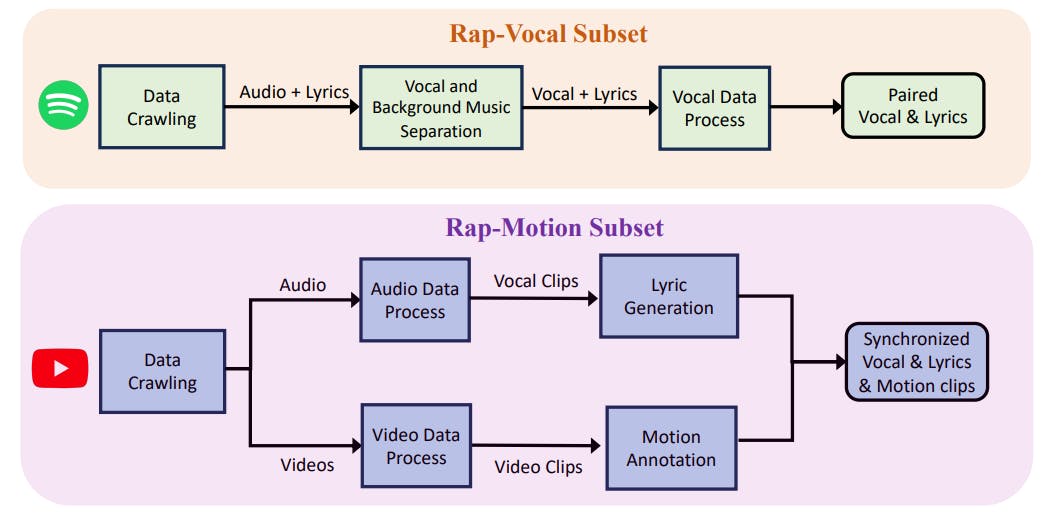
RapVerse Dataset
3.1 Rap-Vocal Subset
3.2 Rap-Motion Subset
-
Method
4.1 Problem Formulation
4.2 Motion VQ-VAE Tokenizer
4.3 Vocal2unit Audio Tokenizer
4.4 General Auto-regressive Modeling
-
Experiments
5.1 Experimental Setup
5.2 Main Results Analysis and 5.3 Ablation Study
-
Conclusion and References
A. Appendix
2.1 Text to Vocal Generation
Text-to-audio Dataset. There exists several singing vocal datasets, yet they each has constraints. For instance, PopCS [32] and OpenSinger [22] are limited to Chinese, while NUS-48E [8] and NHSS [55] have only a few hours of songs. Nevertheless, JVS-MuSiC [58] and NUS-48E [8] offer a few hours of songs from dozens of singers, whereas OpenSinger [22] provides a more extensive collection with tens of hours from a single singer. Notably, our dataset represents the first to be specifically curated for rap songs of multiple singers with 108 hours.
Text-to-vocal Models. Recent advancements in text-to-speech (TTS) models, including WavNet [40], FastSpeech 1 and 2 [52, 51], and EATS [7], have significantly improved the quality of synthesized speech. However, singing voice synthesis (SVS) presents a greater challenge due to its reliance on additional musical scores and lyrics. Recent generation models [32, 16, 16, 74, 26] perform excellently in generating singing voices. However, their performance tends to deteriorate when encountering out-of-distribution data. To handle this, StyleSinger [73] introduces a Residual Style Adaptor and an Uncertainty Modeling Layer Normalization to handle this.
2.2 Text to Motion Generation
Text-to-motion Dataset. Current text-motion datasets, such as KIT [44], AMASS [35], and HumanML3D [13], are constrained by limited data coverage, typically spanning only tens of hours and lacking whole-body motion representation. To overcome these shortcomings, Motion-X [30] was developed, providing an extensive dataset that encompasses whole-body motions.
Text-to-motion Models. Text-to-motion models [43, 71, 14, 13, 34, 4] have gained popularity for their user convenience. Recent advancements have focused on diffusion models [71, 25, 61], which, unlike deterministic generation models [2, 11], enable finer-grained and diverse output generation. Chen et al. [4] proposed a motion latent-based diffusion model to enhance generative quality and reduce computational costs. However, the misalignment between natural language and human motions presents challenges. Lu et al. [34] introduced the Text-aligned Whole-body Motion generation framework to address these issues by generating high-quality, diverse, and coherent facial expressions, hand gestures, and body motions simultaneously.
2.3 Audio to Motion Generation
Audio-to-motion Dataset. Co-Speech Datasets can be classified into 1: pseudo-labeled (PGT) and 2: motion-captured (mocap). PGT datasets [3, 15, 12, 68] utilize disconnected 2D or 3D key points to


represent the body, allowing extracting at a lower cost but with limited accuracy. On the other hand, mocap datasets provide annotations for limited body parts, with some focusing solely on the head [9, 5, 65] or the body [57, 10]. Differing from them, BEATX [31] contains mesh data of both head and body. However, these datasets typically focus on speech to motion generation. Our RapVerse, in contrast, contains paired text-vocal-motion data, enabling simultaneous motion and vocal generation.
Audio-to-motion Models. Audio-to-motion models [59, 56, 72, 31, 68] aim to produce human motion from audio innputs. Recognizing the intricate relationship between audio and human face, TalkSHOW [68] separately generates face parts and other body parts. However, this approach exhibits limitations, such as the absence of generating lower body and global motion. EMAGE [31] utilizes masked gestures together with vocals for a generation. Our model, however, goes a step further by being the first to generate paired audio-motion data directly from text.


Authors:
(1) Jiaben Chen, University of Massachusetts Amherst;
(2) Xin Yan, Wuhan University;
(3) Yihang Chen, Wuhan University;
(4) Siyuan Cen, University of Massachusetts Amherst;
(5) Qinwei Ma, Tsinghua University;
(6) Haoyu Zhen, Shanghai Jiao Tong University;
(7) Kaizhi Qian, MIT-IBM Watson AI Lab;
(8) Lie Lu, Dolby Laboratories;
(9) Chuang Gan, University of Massachusetts Amherst.







{kind=link}