
Table of Links
Abstract and 1. Introduction
- Background and Motivation
- PowerInfer-2 Overview
- Neuron-Aware Runtime Inference
- Execution Plan Generation
- Implementation
- Evaluation
- Related Work
- Conclusion and References
4 Neuron-Aware Runtime Inference
4.1 Polymorphic Neuron Engine
PowerInfer-2 introduces a polymorphic neuron engine that dynamically combines neurons into neuron clusters to take advantage of distinct computational characteristics of LLM inference stages and heterogeneous XPUs.
4.1.1 NPU-Centric Prefill
In the prefill phase, all prompt tokens are processed concurrently. Even though each of these tokens shows high sparsity and activates distinct neurons, there is a considerable decrease in overall sparsity due to the aggregation of these activations. Consequently, PowerInfer-2 does not calculate activated neurons by using predictors in the prefill stage, choosing instead to directly merge all neuron into a big neuron cluster. Given that NPUs excel at handling large matrix-matrix multiplications compared to CPU cores, PowerInfer-2 leverages NPUs for the prefill phase.
Although CPU cores do not take part in matrix calculations, PowerInfer-2 utilizes them to perform essential preparatory tasks for the NPU in the prefill phase. First, due to limited memory, PowerInfer-2 relies on a CPU core to load weights stored in Flash into memory during the prefill phase. Second, as current NPUs do not support direct computation with quantized weights, PowerInfer-2 uses CPU cores to dequantize the data before computation by the NPU[2].
Fig.3-a demonstrates how CPUs and NPU collaborate to perform prefill-phase inference in the transformer layer granularity. The NPU computation requires to use a limited amount of memory that it shares with the CPU. Hence, before NPU computation starts, the CPU should preload the needed matrix weights into this shared memory. Within a specific LLM layer, before the NPU conducts any matrix multiplication, Multiple CPU mid-cores read quantized matrix weights from the neuron cache and dequantize these matrix weights into fp16 ahead of time, eventually storing the results in the shared memory between the CPU and NPU. Meanwhile, PowerInfer-2 uses another big-core to asynchronously preload all matrix weights for the next layer into the neuron cache. The midcore’s dequantization, NPU’s computation, and the big-core’s I/O operations proceed concurrently to reduce the I/O overhead. It is noteworthy that, as the prefill stage involves dense matrix rather than sparse calculations, weight loading via I/O can leverage sequential reads to load a large block of data into memory, thereby maximizing the use of UFS’s I/O bandwidth.
4.1.2 CPU-Centric Decoding
Unlike the prefill phase, the decoding phase concentrates on a single token during each iteration, demonstrating significant sparsity as only a small fraction of neurons (approximately 10%) in the weight matrix are activated and participate in the computation. Thus, when transitioning from the prefill phase to the decoding phase, the polymorphic neuron engine divides the weight matrix computations into small neuron clusters whose elements are identified as active by a predictor. We observe that when the batch size is one the latency of matrix-vector calculations on CPU cores is lower than that on NPUs. Furthermore, given the reduced number of activated neurons due to sparsity, CPU cores are optimally suited for these lighter and sparse computations among XPUs. Therefore, PowerInfer-2 exclusively utilizes CPU cores for neuron cluster computations during the decoding phase.
Specifically, PowerInfer-2 utilizes CPU cores to compute both the attention and FFN blocks during the decoding phase. Although the attention block does not exhibit sparsity, CPU cores still provide lower computational latency when the input is just a single vector. For the FFN block, PowerInfer-2 initially passes the FFN block’s input vector to a predictor, which predicts which neurons in the FFN’s weight matrices need to be activated and merges them into a neuron cluster. Each CPU core then takes a cluster and computes these neurons within the cluster and the input vector.
Fig.3-b illustrates the decoding-phase inference conducted by different CPU cores. CPU cores first read the weights of the attention block from the neuron cache and compute them with the input vector. Then then run the predictor to determine the activation status of neurons in subsequent weight matrices. In the third step, CPU cores divide the activated neurons into several clusters, with each core responsible for computing the activated neurons within its cluster with the input vector, and ultimately aggregating the results at a barrier. If these neurons are within the neuron cache, CPU cores will compute them with the input vector. In cases of a cache miss, where neurons are not in the neuron cache, an I/O thread running on a CPU core to asynchronously load the neurons into the cache, ultimately notifying the computation thread to complete the calculation.
4.2 In-Memory Neuron Cache
Efficient cache design can prevent costly storage I/O activities, thereby optimizing end-to-end inference performance. The effectiveness of a caching system depends on the presence of locality in the inference process. However, traditional LLM inference requires traversing all weights for generating each token, showing no locality and rendering any cache design ineffective.
LLM in a Flash [4] proposes leveraging sparse activations to selectively load weights during inference. It also bundles co-activated neurons and loads them together from Flash to reduce I/O operations. However, this method overlooks the skewed distribution of neuron activations, where a few hot neurons activate more frequently and are highly connected to most other neurons. This brings challenges to designing effective cache strategies. First, these popular neurons reside in different neuron bundles and are redundantly loaded from Flash, wasting I/O bandwidth. Second, our findings show that removing these hot neurons reduces the likelihood of co-activation among the remaining neurons to below 20%, rendering the bundling mechanism ineffective in reducing I/O operations.
To address this, PowerInfer-2 introduces a segmented neuron cache design tailored for various data types within LLMs. It divides the cache into multiple regions, each with specific prefetching and eviction policies. The attention block weights, being smaller and less sparsely activated, are preloaded and retained throughout runtime.
In contrast, the FFN block, prone to frequent activations of hot neurons, uses a dynamic eviction strategy based on Least Recently Used (LRU) for these neurons. This approach ensures that hot neurons are more likely to remain in the cache, while cold neurons are frequently evicted and loaded on demand from Flash. Importantly, the eviction process does not involve writing to storage but simply discards weights from memory.
PowerInfer-2 leverages a classic dual-queue approach to implement its LRU neuron cache, which manage LLM weights at the granularity of individual neurons. The system maintains two doubly linked list queues, labeled active and inactive, where the order of neurons within the queues is determined by the time of their most recent accesses, with the most recently accessed neurons at the head of the queue.
At runtime, all neurons initially join the inactive queue. Upon re-access, they are promoted to the front of the active queue. Neurons already in the active queue are moved to the head upon subsequent access. To manage cache capacity, when the active queue fills up to 90% of the cache space, neurons from the tail of the active queue are moved to the inactive queue until the active queue’s occupancy drops below 90%. If the cache reaches capacity, neurons at the tail of the inactive queue are discarded to make room for new entries.
4.3 Flexible Neuron Loading
Equipped with the neuron cache that effectively stores active neurons, the inference process still inevitably incurs I/O operations for uncached neurons. To optimize I/O read throughput and minimize I/O operations, PowerInfer-2 also bundles associated neurons. Although co-activation within a single FFN weight matrix becomes infrequent once hot neurons are removed, neurons at corresponding positions across different matrices often activate together. For instance, the co-activation probability of the i-th neurons across the Gate, Up, and Down matrices is as high as 80%. Therefore, PowerInfer-2 opts to store neuron weights based on neuron granularity rather than matrix structure, concatenating weights of the i-th neurons from the Gate, Up, and Down matrices into a single entry.
PowerInfer-2 further introduces distinct I/O loading strategies for different models, considering their quantization methods and the inherent characteristics of UFS I/O. For models without quantization, owing to the large storage space each neuron occupies, PowerInfer-2 uses random reads with a larger granularity to boost I/O bandwidth. For example, an individual neuron in Llama-7B-FP16 occupies 8KB, the combined size of neurons from the Gate, Up, and Down matrices amounts to 24KB. PowerInfer-2 efficiently transfers the entire 24KB activated bundle into memory through a single random I/O read.
For 4-bit quantized models, the bundle size is set at 8KB. Considering the Llama-7B model as an example, where each neuron is quantized to 4-bit precision and occupies 2.5KB (2KB for quantized int4 values, and 0.5KB for FP16 scales of quantization groups), the combined bundle size reaches 7.5KB. To align with the storage medium’s minimum read granularity of 4KB, PowerInfer-2 supplements the bundle with an additional 0.5KB, rounding the total to 8KB. However, rather than loading these 8KB bundles in a single I/O operation, PowerInfer-2 opts for a 4KB granularity. This choice is based on our analysis in §2.3 showing that the bandwidth from two separate 4KB random reads exceeds that from a single 8KB read, thereby optimizing the I/O reading process.
Moreover, considering the co-activation likelihood of 80% within these bundles, there is still nearly 20% probability that these bundled neurons are not co-activated. Thus, combining the two 4KB random reads could potentially lead to bandwidth wastes. To mitigate this, for models using 4-bit quantization, PowerInfer-2 delays the second 4KB read until the outcomes from the Gate neuron multiplications are obtained. Specifically, PowerInfer-2 uses the predictor to determine the activation of neurons within the Gate matrix, initiating the load for the first part of the bundle based on this information. Afterwards, if the output from the Gate neuron (passing through the activation function) is non-zero, PowerInfer-2 proceeds to load the second part of the bundle, thus minimizing unnecessary I/O operations.
4.4 Neuron-Cluster-Level Pipeline
PowerInfer-2 is also designed to hide I/O overheads by overlapping computation with I/O activities. A straightforward approach is the matrix-level overlapping, which issues I/O commands to retrieve matrix neurons from storage while concurrently processing neurons already in memory. As neurons from storage are loaded, they are immediately processed. Although this matrix-level overlapping method can somewhat hide the cost of I/O operations within the computation process, it still requires the system to wait for the completion of
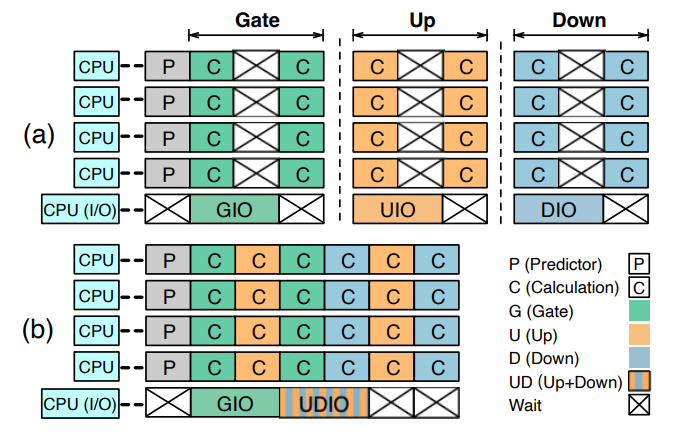
all neurons within the matrix, include those fetched from storage, before moving on to the next. As illustrated in Fig.4-a, suppose a matrix contains 8 neuron clusters, with 4 residing in memory and the remaining 4 in storage. A portion of I/O operations can be hidden behind the cached neurons computations. But due to the lengthy I/O times, there would still be instances where CPU cores have to wait for I/O completion.
To eliminate waiting times for I/O operations, PowerInfer-2 introduces a neuron-cluster-level pipeline mechanism. This mechanism is based on an insight: by focusing on the neuron cluster as the granularity, it’s possible to overlap the I/O operations within neuron cluster computations from multiple matrices. Concretely, PowerInfer-2 breaks down the barriers between matrix computations; as soon as one neuron cluster finishes computing, it immediately starts the computation of a neuron cluster in the next matrix that are in memory. This mechanism effectively reduces waiting bubbles, as illustrated in Fig.4-b.
PowerInfer-2 divides the execution process of a neuron cluster into 5 sequential stages, which are: determining whether the rows/columns of the Gate, Up, and Down matrices is activated through the predictor (Pred), reading the weights of the rows of the Gate matrix from storage (GIO), calculating the product of the rows of the Gate matrix and the input vector (GC), reading the rows/columns of the Up and Down matrices from storage (UDIO), and calculating the product of the rows/columns of the Up and Down matrices with the input vector respectively (UDC). PowerInfer-2 creates multiple computing threads and one I/O thread to handle the computations and I/O operations for these 5 stages, respectively. The specific number of these threads and the cores on
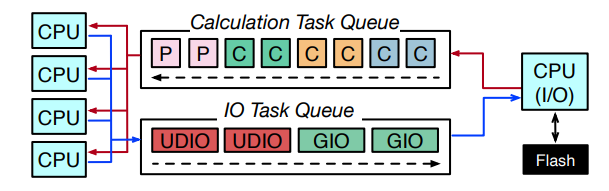
which they will execute are determined by the offline planner.
Fig.5 shows how computing and I/O threads work to implement the neuron-cluster pipeline. At the start of each FFN block, all neurons are initially in the Pred stage, are inserted into the computing queue. Computing threads process these neurons, advancing only those activated to subsequent stages. These activated neurons are then merged into neuron clusters. If the Gate weights of a neuron cluster are available in memory, the neuron cluster progresses to the GC stage and returns to the computing queue. If not, it is set to GIO and moved to the I/O queue. Meanwhile, computing threads continue to process the next neuron cluster from the queue. In parallel, I/O threads takes out neurons from the I/O queue, executing I/O tasks as needed. The execution of UDIO and UDC follows a similar pattern to GC and GIO.
:::info
Authors:
(1) Zhenliang Xue, Co-first author from Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(2) Yixin Song, Co-first author from Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(3) Zeyu Mi, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University ([email protected]);
(4) Le Chen, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(5) Yubin Xia, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(6) Haibo Chen, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University.
:::
:::info
This paper is available on arxiv under CC BY 4.0 license.
:::
[2] Although Qualcomm’s documentation states that the NPU supports direct int4 computations, the SDK does not yet support interfaces for int4 matrix calculations.







{kind=link}