
Table of Links
Abstract and I. Introduction
II. Background
III. Paranoid Stateful Lambda
IV. SCL Design
V. Optimizations
VI. PSL with SCL
VII. Implementation
VIII. Evaluation
IX. Related Work
X. Conclusion, Acknowledgment, and References
VIII. EVALUATION
SCL leverages DataCaspules as the data representation to support inter-enclave communication. To quantify the benefits and limitations, we ask: (1) How does SCL perform as a KVS(§VIII-B)? (2) How do circular buffer (§VIII-D), and replication (§VIII-C) affect the overhead? (3) How long does it take to securely launch a PSL task? (§VIII-E) (4) How much does SCL pay to run in-enclave distributed applications(§VIII-F)?
A. Experiment Setup
We evaluate PSL on fifteen Intel NUCs 7PJYH, equiped with Intel(R) Pentium(R) Silver J5005 CPU @ 1.50GHz with 4 physical cores (4 logical threads). The processor has 96K L1 data cache, a 4MiB L2 cache, and 16GB memory. The machine uses Ubuntu 18.04.5 LTS 64bit with Linux 5.4.0- 1048-azure. We run Asylo version 0.6.2. We report the average of experiments that are conducted 10 times. For each NUC, it runs two PSL threads by default.
B. End-To-End Benchmark of SCL
Benchmark Design: An end-to-end evaluation of SCL starts the worker sends the first acknowledgement to the user, and ends when the client receives its last request’s response from the workers. We evaluate the performance using a workload generated by YCSB workload generators. Due to the difference between get and put protocols, we focus on the read-only and write-only workloads. All workloads comply zipfian distribution, where keys are accessed at non-uniform frequency. For each get, we evaluate the performance of getting from the local memtable of the lambda(get(cached)), and of getting the data from CapsuleDB(get(uncached)). Each get request is synchronous that the next request is sent only if it gets the value of the previous get request.
Overall Performance: Figure 9 shows the throughput of the end-to-end YCSB benchmark. The aggregated throughput of put. The get(CapsuleDB) throughput is flattened as we increate the number of the lambdas, because we run one single CapsuleDB instance that handle all the queries, which is bottlenecked as the number of lambdas that issue get(CapsuleDB) increases.
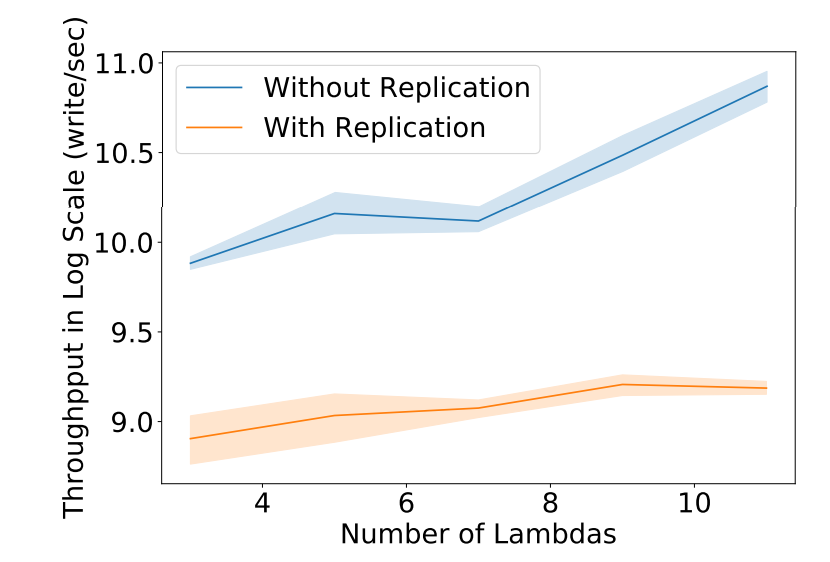
C. Replication-enabled End-To-End Benchmark
Benchmark Design: Replication-enabled end-to-end evaluation measures the performance of the SCL layer with durability. In particular, it includes the overhead of workers sending each write to the DataCapsule replicas, a quorum of DataCapsule replicas receive data and persist it on disk, and then acking the worker. We evaluate the performance using a workload generated by YCSB workload generators. Since replication involves only write operations, we evaluate a writeonly workload. The workload involves a zipfian distribution, with keys accessed at a non-uniform frequency.
Overall Performance: Figure 10 illustrates the performance of the DataCapsule backend. It shows that SCL with replication has reached a bottleneck after 9 workers while SCL without durability continues to scale. The performance drop and bottleneck are due to several reasons: 1) disk operations are inherently slow; 2) the burden on replication system’s leader is high for collecting acks from DataCapsule replicas and sending the aggregated ack back to worker. We aim to improve SCL with replication by mitigating the workload on the replication leader.
D. Circular Buffer Microbenchmark
Benchmark Design: The circular buffer provides efficient application-enclave communication. We compare the perfor-

mance of the circular buffer with the SGX SDK baseline and the state-of-the-art HotCall. We evaluate them based on the number of clock cycles required for communications in both the application to enclave direction and vice versa.
Overall Performance: As shown in Table I, baseline SGX SDK incurs a significant overhead of over 20,000 clock cycles from application to enclave, and over 8,600 clock cycles from enclave to application. For both directions, HotCall is able to reduce the overhead to under a thousand clock cycles. Our circular buffer reduces overheads even further. Our solution only requires 461.1 and 525.54 clock cycles from application to enclave and vice versa. Compared to state-of-the-art HotCall, our solution provides 103% and 44% improvements, respectively.
E. Lambda Launch Time
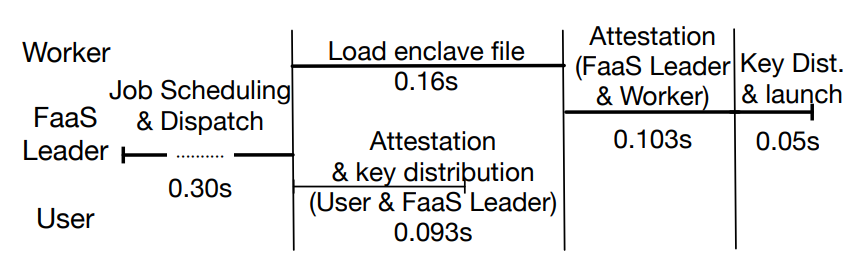
Benchmark Design: We evaluate the launching process of PSL by running Workers and FaaS leader in SGXv2 hardware mode, which the worker lambda, FaaS leader and user on different physical Intel NUCs machines. For each NUC, it runs Asylo AGE in hardware mode with PCE signed by Intel that helps enclave generates attestation assertions. We assume the machines already have the pulled the prebuilt lambda runtime binaries and execute the runtime. The cold-start bootstrapping process lasts 42 seconds on average in our experiment setting.
Lambda Launch Breakdown: Figure 11 show the latency breakdown of the launching process. It takes 0.30s for the user to reach out to the scheduler, and for the scheduler to find and forward the encrypted task to the potential workers. Then the workers load associated runtime and data to the enclave, which takes 0.16s. We parallelize the worker loading time with the attestation. that the user remotely attests the FaaS Leader to verify that the FaaS leader is running authenticated code in SGX enclave. After the worker’s enclave file is loaded, it takes 0.103s on average for the FaaS leader to remotely attest the
worker enclave. We note that this attestation latency is mostly constituted by the network delay of grpc request and the local attestation assertion generation time of the worker’s AGE, so it does not incur scalability issue with the FaaS leader when multiple workers are launched at the same time.
F. Case Study: Fog Robotics Motion Planner
We experiment with a sampling-based motion planner that is parallelized to run on multiple concurrent serverless processes, MPLambda [23], and modifying it to use SCL. Most of the porting effort done was to integrate MPLambda’s build system into Asylo. The modification is about 100 LoC. Many system calls that MPLambda uses are proxied by Asylo.
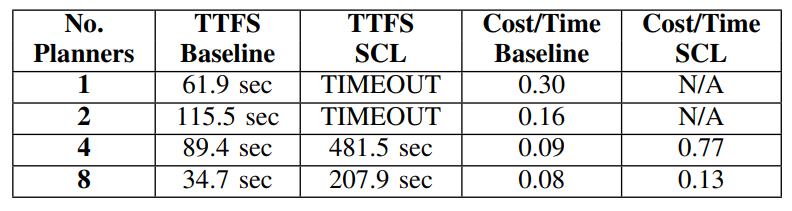
Using MPLambda with SCL, we compute a motion plan running a fetch scenario in which a Fetch mobile manipulator robot [17] declutters a desk. We measure the median wallclock time to find the first solution by the planners. We also measure the median average path cost per time of the lowest cost path the planners return. This captures how efficiently the planners can compute the best path. Because the planner uses random sampling, we run the same computation multiple times with different seeds. As with previous experiments, we run this test on Intel NUCs 7PJYH, equipped with Intel(R) Pentium(R) Silver J5005 CPU @ 1.50GHz with 4 physical cores (4 logical threads). We set a timeout of 600 seconds for the planners to compute a path.
We run up to 8 planners, running on separate Intel NUCs using SCL and comparing this to running MPLamda without SCL. We observe an increase in performance as we scale out the number of planners. Each planner runs computationally heavy workloads and PSL introduces several threads (i.e. crypto actors, zmq clients, OCALL/ECALL handlers) that take away CPU time from the planner thread. Furthermore, MPLambda planners use the Rapidly-exploring random tree (RRT*) [24] algorithm, to search for paths by randomly generating samples from a search space, checking whether the sample is feasible to explore, and adding the sample to a constructed tree data structure. The tree data structure may grow large and take up a significant amount of memory. Memory in SGX is a limited resource and increased memory pressure leads to more misses in the EPC and requiring paging in and out of enclaves frequently. There is work on limiting the memory usage of RRT* by bounding the memory for the tree data structure, which we can adopt in future work. [2].
:::info
Authors:
(1) Kaiyuan Chen, University of California, Berkeley ([email protected]);
(2) Alexander Thomas, University of California, Berkeley ([email protected]);
(3) Hanming Lu, University of California, Berkeley (hanming [email protected]);
(4) William Mullen, University of California, Berkeley ([email protected]);
(5) Jeff Ichnowski, University of California, Berkeley ([email protected]);
(6) Rahul Arya, University of California, Berkeley ([email protected]);
(7) Nivedha Krishnakumar, University of California, Berkeley ([email protected]);
(8) Ryan Teoh, University of California, Berkeley ([email protected]);
(9) Willis Wang, University of California, Berkeley ([email protected]);
(10) Anthony Joseph, University of California, Berkeley ([email protected]);
(11) John Kubiatowicz, University of California, Berkeley ([email protected]).
:::
:::info
This paper is available on arxiv under CC BY 4.0 DEED license.
:::







{kind=link}