
Table of Links
Abstract and 1 Introduction
-
Related Work
-
Our Proposed DiverGen
3.1. Analysis of Data Distribution
3.2. Generative Data Diversity Enhancement
3.3. Generative Pipeline
-
Experiments
4.1. Settings
4.2. Main Results
4.3. Ablation Studies
-
Conclusions, Acknowledgments, and References
Appendix
A. Implementation Details
B. Visualization
A. Implementation Details
A.1. Data Distribution Analysis
We use the image encoder of CLIP [21] ViT-L/14 to extract image embeddings. For objects in the LVIS [8] dataset, we extract embeddings from the object regions instead of the whole images. First, we blur the regions outside the object masks using the normalized box filter, with the kernel size of (10, 10). Then, to prevent objects from being too small, we pad around the object boxes to ensure the minimum width of the padded boxes is 80 pixels, and crop the images according to the padded boxes. Finally, the cropped images are fed into the CLIP image encoder to extract embeddings. For generative images, the whole images are fed into the CLIP image encoder to extract embeddings. At last, we use UMAP [18] to reduce dimensions for visualization. τ is set to 0.9 in the energy function.
To investigate the potential impact of noise in the rare classes to TVG metrics, we conduct additional experiments to demonstrate the validity of TVG. We randomly take five different models each for the LVIS and LVIS + Gen data sources, compute the mean (µ) and standard deviation (σ) of their TVG, and calculate the 3 sigma range (µ + 3σ and µ−3σ), which we think represents the maximum fluctuation that potential noise could induce. As shown in Table 10, we find that: 1) The TVGs of LVIS all exceed the 3 sigma upper bound of LVIS + Gen, while the TVGs of LVIS + Gen are all below the 3 sigma lower bound of LVIS, and there is no overlap between the 3 sigma ranges of LVIS and LVIS + Gen; 2) For both LVIS + Gen and LVIS, there is no overlap between the 3 sigma ranges of different groups, e.g. frequent and common, common and rare. These two findings suggest that even in the presence of potential noise, the results can not be attributed to those fluctuations. Therefore, we think our proposed TVG metrics are reasonable and can support the conclusions.
A.2. Category Diversity
We compute the path similarity of WordNet [5] synsets between 1,000 categories in ImageNet-1K [23] and 1,203 categories in LVIS [8]. For each of the 1,000 categories in ImageNet-1K, if the highest similarity for that category is below 0.4, we consider the category to be non-existent in LVIS and designate it as an extra category. Based on this method, 566 categories can serve as extra categories. The names of these 566 categories are presented in Table 13.
A.3. Prompt Diversity
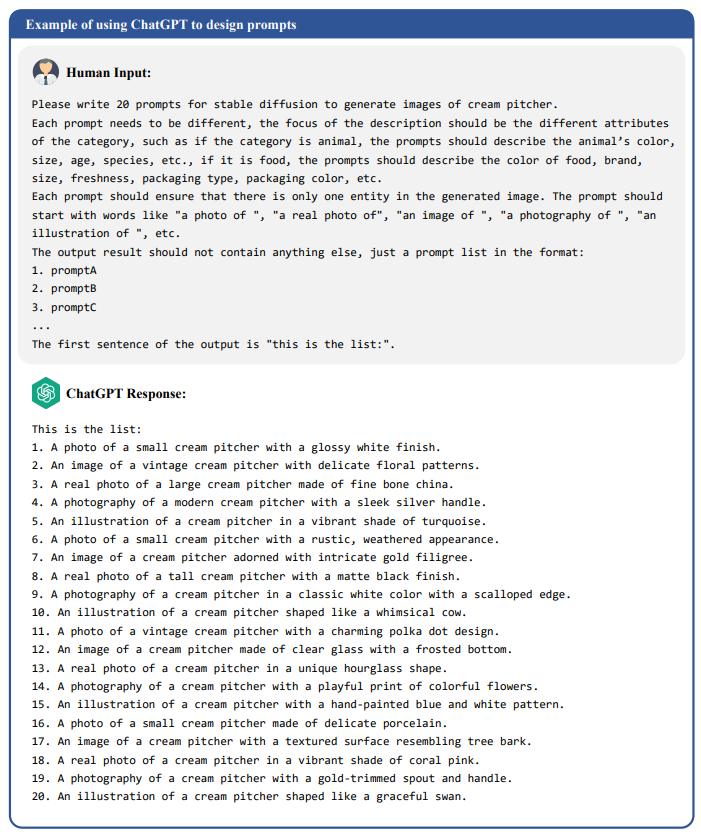
Limited by the inference cost of ChatGPT, we use the manually designed prompts as the base and only use ChatGPT to enhance the prompt diversity for a subset of categories. For manually designed prompts, the template of prompts is “a photo of a single {categoryname}, {categorydef}, in a white background”. category name and category def are from LVIS [8] category information. For ChatGPT designed prompts, we select a subset of categories and use ChatGPT to enhance prompt diversity for these categories. The names of the 144 categories in this subset are shown in Table 14. We use GPT-3.5-turbo and have three requirements for the ChatGPT: 1) each prompt should be as different as possible; 2) each prompt should ensure that there is only one object in the image; 3) prompts should describe different attributes of the category. Therefore, the input prompts to ChatGPT contain these three requirements. Examples of input prompts and the corresponding responses from ChatGPT are illustrated in Figure 8. To conserve output token length, there is no strict requirement for ChatGPT designed prompts to end with “in a white background”, and this constraint will be added when generating images.
A.4. Generative Model Diversity
We select two commonly used generative models, Stable Diffusion [22] and DeepFloyd-IF [24]. For Stable Diffusion, we use Stable Diffusion V1.5, with 50 inference steps and a guidance scale of 7.5. All other parameters are set to their defaults. For DeepFloyd-IF, we use the output images from stage II, with stage I using the weight IF-I-XL-v1.0 and stage II using IF-II-L-v1.0. All parameters are set to their defaults.
A.5. Instance Annotation
We employ SAM [12] ViT-H as the annotation model. We explore two annotation strategies, namely SAM-foreground and SAM-background. SAM-foreground uses points sampled from foreground objects as input prompts. Specifically, we first obtain the approximate region of the foreground object based on the cross-attention map of the generative model using a threshold. Then, we use k-means++ [1] clustering to transform dense points within the foreground region into cluster centers. Next, we randomly select some points from the cluster centers as inputs to SAM. We use various metrics to evaluate the quality of the output mask and select the mask with the highest score as the final mask. However, although SAM-foreground is intuitive, it also has some limitations. Firstly, cross-attention maps of different categories require different thresholds to obtain foreground regions, making it cumbersome to choose the optimal threshold for each category. Secondly, the number of points required for SAM to output mask varies for different foreground objects. Complex object needs more points than simple object, making it challenging to control the number of points. Additionally, the position of points significantly influences the quality of SAM’s output mask. If the position of points is not appropriate, this strategy is prone to generating incomplete masks.
Therefore, we discard SAM-foreground and propose a simpler and more effective annotation strategy, SAMbackground. Due to our leveraging of the controllability of the generative model in instance generation, the generative images have two characteristics: 1) each image predominantly contains only one foreground object; 2) the background of the images is relatively simple. SAM-background directly uses the four corner points of the image as input prompts for SAM to obtain the background mask, then inverts the background mask as the mask of the foreground object. The illustrations of point selection for SAM-foreground and SAM-background are shown in Figure 6. By using SAM-background for annotation, more refined masks can be obtained. Examples of annotations from SAM-foreground and SAM-background are shown in Figure 7.

To further validate the effectiveness of SAM-background, we manually annotate masks for some images as ground truth (gt). We apply both strategies to annotate these images and calculate the mIoU between the resulting masks and the ground truth. The results in Table 11 indicate that SAMbackground achieves better annotation quality.
A.6. Instance Filtration
We use the image encoder of CLIP [21] ViT-L/14 to extract image embeddings. The embedding extraction process is


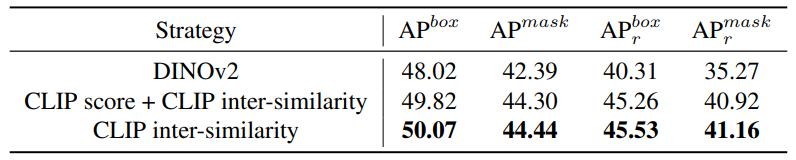
consistent with Sec A.1. Then we calculate the cosine similarity between embeddings of objects in LVIS training set and embeddings of generative images. For each generative image, the final CLIP inter-similarity is the average similarity with all objects of the same category in the training set. Through experiments, we find that when the filtering threshold is 0.6, the model achieves the best performance and strikes a balance between data diversity and quality, so we set the threshold to 0.6.
Furthermore, we also explore other filtration strategies. From our experiments, using pure image-trained models like DINOv2 [19] as image encoder or combining CLIP score and CLIP inter-similarity is not as good as using just CLIP inter-similarity alone, as shown in Table 12. Therefore, we ultimately opt to only use CLIP inter-similarity.
A.7. Instance Augmentation
In instance augmentation, we use the instance paste strategy proposed by Zhao et al. [34] to increase model learning efficiency on generative data. Each image contains up to 20 pasted instances at most.
The parameters not specified in the paper are consistent with X-Paste [34].
B. Visualization
B.1. Prompt Diversity
We find that images generated from ChatGPT designed prompts have diverse textures, styles, patterns, etc., greatly enhancing data diversity. The ChatGPT designed prompts and the corresponding generative images are shown in Figure 9. Compared to manually designed prompts, the diversity of images generated from ChatGPT designed prompts can be significantly improved. A visual comparison between generative images from manually designed prompts and ChatGPT designed prompts is shown in Figure 10.
B.2. Generative Model Diversity
The images generated by Stable Diffusion and DeepFloyd-IF are different, even within the same category, significantly enhancing the data diversity. Both Stable Diffusion and DeepFloyd-IF are capable of producing images belonging to the target categories. However, the images generated by DeepFloyd-IF appear more photorealistic and consistent with the prompt texts. This indicates DeepFloyd-IF’s superiority in image generation quality and controllability through text prompts. Examples from Stable Diffusion and DeepFloyd-IF are shown in Figure 11 and Figure 12, respectively.
B.3. Instance Annotation
In terms of annotation quality, masks generated by max CLIP [34] tend to be incomplete, while our proposed SAMbg is able to produce more refined and complete masks when processing images of multiple categories. As shown in Figure 13, our proposed annotation strategy can output more precise and refined masks compared to max CLIP.
B.4. Instance Augmentation
The use of instance augmentation strategies helps alleviate the limitation in relatively simple scenes of generative data and improves the efficiency of model learning on the generative data. Examples of augmented data are shown in Figure 14.







:::info
Authors:
(1) Chengxiang Fan, with equal contribution from Zhejiang University, China;
(2) Muzhi Zhu, with equal contribution from Zhejiang University, China;
(3) Hao Chen, Zhejiang University, China ([email protected]);
(4) Yang Liu, Zhejiang University, China;
(5) Weijia Wu, Zhejiang University, China;
(6) Huaqi Zhang, vivo Mobile Communication Co..
(7) Chunhua Shen, Zhejiang University, China ([email protected]).
:::
:::info
This paper is available on arxiv under CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International) license.
:::






{kind=link}