
Table of Links
Abstract and 1 Introduction
-
Related Work
2.1. Multimodal Learning
2.2. Multiple Instance Learning
-
Methodology
3.1. Preliminaries and Notations
3.2. Relations between Attention-based VPG and MIL
3.3. MIVPG for Multiple Visual Inputs
3.4. Unveiling Instance Correlation in MIVPG for Enhanced Multi-instance Scenarios
-
Experiments and 4.1. General Setup
4.2. Scenario 1: Samples with Single Image
4.3. Scenario 2: Samples with Multiple Images, with Each Image as a General Embedding
4.4. Scenario 3: Samples with Multiple Images, with Each Image Having Multiple Patches to be Considered and 4.5. Case Study
-
Conclusion and References
Supplementary Material
A. Detailed Architecture of QFormer
B. Proof of Proposition
C. More Experiments
3.2. Relations between Attention-based VPG and MIL
In AB-MIL[16], weights are calculated as Equation 5.

Proposition 1. QFormer belongs to the category of Multiple Instance Learning modules.
Within the cross-attention layer of QFormer, every query token computes weights for image embeddings. Query embeddings, being learnable parameters, can be seen as a linear transformation from an instance to its weight. To provide further clarification, each row in the attention map A signifies the weights assigned to instances for aggregation. Consequently, the cross-attention between the learnable query embeddings and the input is permutation invariance.
The result of cross-attention is combined with the original query embeddings using a residual connection. This process can be expressed as shown in Equation 6, by replacing pool with Equation 1, and setting λ = γ = I, as illustrated in Equation 7, which is permutation equivalence.
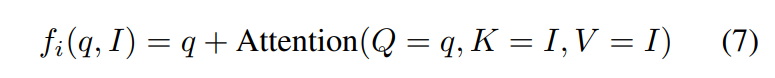
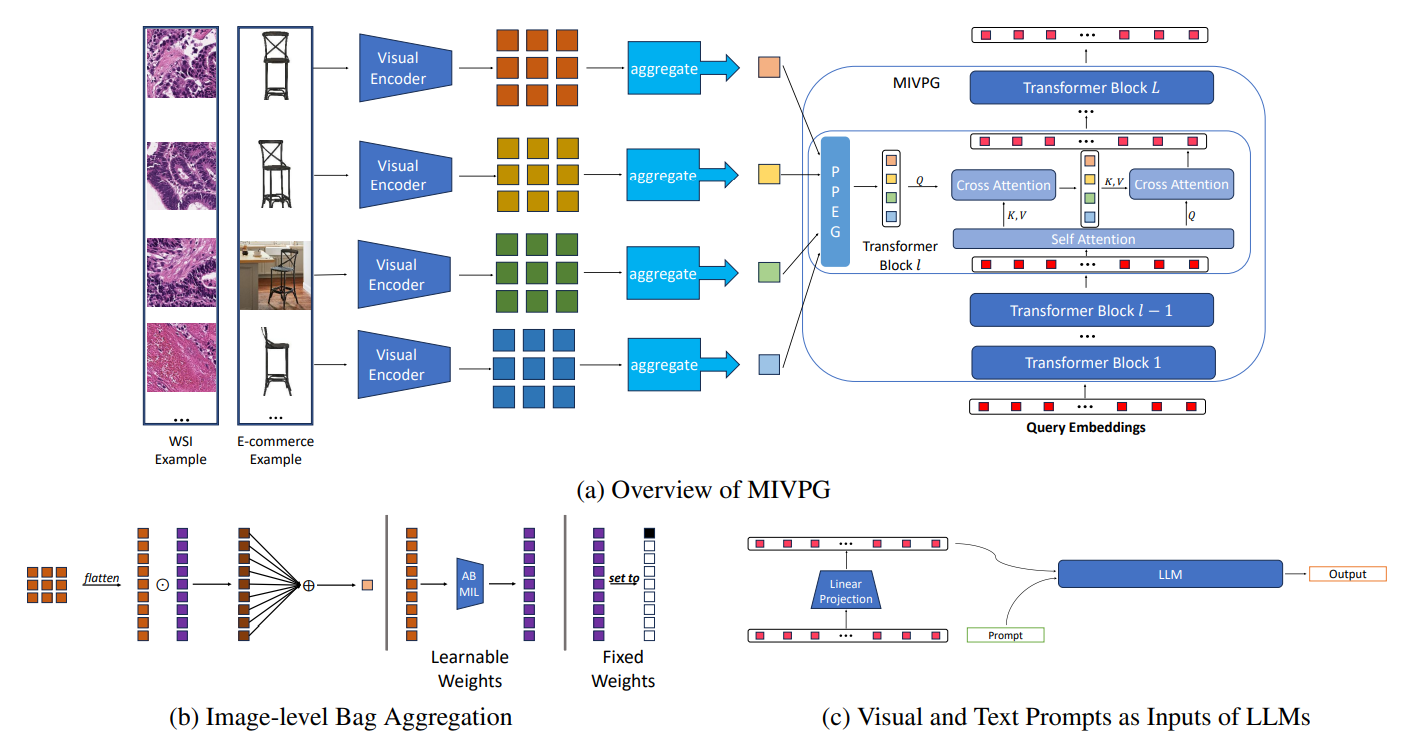
Considering that the self-attention layer within the QFormer block adheres to the principles of permutation equivalence, we can conceptualize the QFormer as a multi-head MIL mechanism.
From the standpoint of MIL, the weighted pooling in Equation 1 operates under the assumption that instances are independent and identically distributed (i.i.d)[34]. However, in practical scenarios, instances may exhibit correlations, and accounting for instance correlation can lead to improved performance. It’s worth noting that when each sample contains only one image, the input to QFormer comprises patch embeddings that have already incorporated correlations through the self-attention layer in ViT. Moreover, performance enhancement is attainable through the integration of a Pyramid Positional Encoding Generator (PPEG)[34], which complements the proposed MIVPG when handling single-image inputs.
:::info
Authors:
(1) Wenliang Zhong, The University of Texas at Arlington ([email protected]);
(2) Wenyi Wu, Amazon ([email protected]);
(3) Qi Li, Amazon ([email protected]);
(4) Rob Barton, Amazon ([email protected]);
(5) Boxin Du, Amazon ([email protected]);
(6) Shioulin Sam, Amazon ([email protected]);
(7) Karim Bouyarmane, Amazon ([email protected]);
(8) Ismail Tutar, Amazon ([email protected]);
(9) Junzhou Huang, The University of Texas at Arlington ([email protected]).
:::
:::info
This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::
 Semiconductor Stocks to Buy by Hand Before December (Hint: It’s Not Nvidia)")






{kind=link}